Анализ архитектурных принципов фон Неймана
Архитектурные принципы фон Нейманом формулировались примени-тельно к созданию автоматического устройства для решения дифферен-циальных уравнений.
Основные характеристики архитектуры фон Неймановского типа следующие:
· последовательно адресуемая единственная память линейного типа для хранения программ и данных;
· команды и данные различаются через идентификатор неявным способом лишь при выполнении операций. Принимаемые по умолчанию соглашения типа: операнды операции умножения– это данные, а объект, на который указывает команда перехода – это команда, позволяют обращаться с командой как с данными, например, для ее модификации;
· назначение данных определяется лишь логикой программы, так как в памяти машины набор бит может представлять собой как десятичное число с фиксированной точкой, так и строку символов.
Указанные свойства были исключительно важными для своего времени. Однако появление языков высокого уровня (ЯВУ), новых методов решения, логических способов ускорения операций, более совершенной элементной базы требует наряду с имеющимися возможностями архитектуры и принципиально новых. Среди них требования ЯВУ имеют следующие особенности:
· память состоит из набора дискретных именуемых переменных. Вовсе не требуется, например, чтобы память для значений переменных одной программы располагалась рядом с памятью для значений переменных другой программы. Таким образом, принцип единственной последовательной памяти имеет мало общего с организацией памяти в ЯВУ;
· ЯВУ наряду с линейными данными оперируют и с многомерными: массивами, структурами, списками;
· в ЯВУ четко разграничены операции и данные;
· данные определяют и операции над ними.
Например, смысл операции A + C определяется описанием A и С. Cемантика операции "+" совершенно различна, например, для целых чисел и символьных переменных.
Архитектура фон Неймана плохо ориентирована на выполнение программ на ЯВУ. Действительно,
· объем кодов, генерируемых компилятором, из?за несоответствия требуемой ЯВУ и предлагаемой архитектурой организации памяти значительно превосходит необходимый объем для решения запрограммированной задачи;
· примитивность выполняемых операций в объектном коде требует сложной работы компилятора.
К сожалению, ЯВУ имитируют в своей структуре архитектуру фон Неймановского типа: переменные – пассивное ЗУ; оператор присваивания – арифметическое устройство (АУ); последовательное выполнение операторов управления (IF, GOTO) – устройство управления (УУ).
Много сложностей из?за работы компьютера в двоичной системе. Как отразится на экране дисплея вводимое десятичное вещественное число? Не будет ли потерь в младшем разряде?
Язык АДА, особенно беспокоящийся о точности вычислений, также не ушел от аппроксимации десятичных вещественных чисел двоичными.
Общая взаимосвязь между ЯВУ и ЭВМ в зависимости от уровня языка машины может быть представлена следующей схемой (рис. 1.5).
Введение программно?адресуемых регистров (так называемых регистров общего назначения) существенно увеличивает количество используемых команд LOAD (загрузка в регистр) и STORE (запись в память), т. е. команд перемещения данных из регистров в память и обратно. Исследования на компьютере PDP для различных ЯВУ показывают, что 42 % всех выполняемых команд затрачивается на перемещение данных между памятью и регистрами. Имеются исследования, утверждающие, что использование кэш-памяти позволяет достичь увеличения быстродействия за счет использования регистров общего назначения.
В настоящее время имеются конкретные проекты архитектур машин, ориентированные на ЯВУ: ПАСКАЛЬ, PL, ЛИСП, КОБОЛ.
Однако больший интерес представляют архитектуры, ориентированные не на конкретный язык, а на общие семантические возможности некоторой группы языков. Так, архитектура машины SWARD ориентирована на языки PL/1, АДА, ФОРТРАН, КОБОЛ и некоторые другие, создавая тем самым благоприятную среду для программиста.
Компьютеры фирмы Burroughs, начиная с модели B 1700, за счет вызова различных микропрограмм динамически настраиваются на язык написания выполняемой программы.
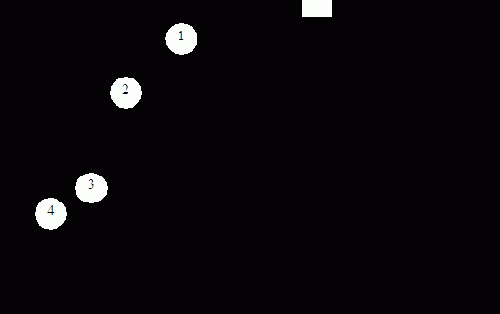 |
1 – это традиционный подход. После компилирования программа переводится на машинный язык, а затем интерпретируется машиной; 2 – компиляция идет на машинный язык более высокого уровня, сокращая тем самым семантический разрыв между ЯВУ и машиной; 3 – здесь ЯВУ можно рассматривать как язык ассемблера, т. е. имеется взаимно однозначное соответствие между типами операторов и знаков операций ЯВУ с командами машинного языка. Здесь идет ассемблирование, а не компилирование, во время которого удаляются комментарии и пробелы в исходной программе, преобразуются разделители, ключевые слова и знаки операций в машинные коды, имена – в адреса полей памяти. Таким образом, многих привычных функций компилятора здесь нет. Остальная привязка программы к ЭВМ происходит перед выполнением программы; 4 – здесь машинный
язык является ЯВУ и идет процесс интерпретации программы на компьютере
Отметим, что разработчику архитектуры ЭВМ не следует строго ориентироваться на языки программирования, компиляторы, операционные сис-
темы и другие программы, чтобы не потерять главное в архитектуре – ориентацию на современные требования задач и окружение пользователя.
Необходимо искать разумный компромисс в распределении функций системы между аппаратной и программной реализацией с учетом стоимости, возможности модификации, работы на микроуровне и т. д. Необходимо помнить, что компьютер создается для эффективного выполнения программ.
Архитектура как интерфейс между уровнями физической системы
 |
Применительно к ВС термин "архитектура" может быть определен как распределение функций, выполняемых системой, по различным уровням и установление интерфейса между этими уровнями. На рис.1.4 представлен набор уровней абстракции как специфического свойства архитектуры ВС. Остановимся лишь на ключевых уровнях.
Рис. 1.4. Многоуровневая организация архитектуры
вычислительной системы
Архитектура первого уровня определяет, какие функции по обработке данных решаются системой, а какие передаются внешнему миру: пользователю, оператору ЭВМ, администратору баз данных и т. д. Система взаимодействует с внешним миром через два набора интерфейсов: языки (язык программирования, язык оператора терминала, язык управления заданиями, язык общения с базой данных, язык оператора ЭВМ) и системные программы (программы редактирования, связи, оптимизации, восстановления и обновления информации, интерпретации, управления и т. д., т. е. программы, созданные разработчиком системы). Оба интерфейса должны быть созданы при разработке архитектуры системы.
Уровни, определяемые интерфейсами внутри программного обеспечения, могут быть представлены как архитектура программного обеспечения. К примеру, если прикладные задачи реализованы на языках программирования, которые не входят в набор языков, предоставляемых системой пользователю, то здесь речь может идти об архитектуре уровня, позволяющего определить указанные языки.
Уровень 5 является одним из центральных уровней архитектуры и проводит разграничение между системным программным и аппаратным (т. е. схемным и микропрограммным) обеспечением. Он позволяет представить физическую структуру системы независимо от способа реализации.
Остальные уровни отражают интерфейсы и распределяют функции между отдельными частями физической системы.
Таким образом, можно сказать, что архитектура компьютера – это абстрактное представление физической системы с точки зрения программиста.
Процесс разработки архитектуры ЭВМ включает все этапы разработки типовых проектов:
· анализ требований, предъявляемых к системе;
· составление спецификаций;
· изучение известных решений;
· разработку функциональной схемы;
· разработку структурной схемы;
· отладку проекта;
· оценку проекта.
При анализе требований, например, мы учитываем спектр необходимых языков программирования, способ взаимодействия с окружающей средой, требования к операционной системе, некоторые технико?экономические факторы: количество таких систем (ибо это существенно влияет на соотношение между аппаратным и программным обеспечением), совместимость разрабатываемой системы (по языкам программирования, операционным системам, форматам данных, техническим устройствам) с существующими аналогичными вычислительными системами и т. д.
При анализе требований и составлении перечня спецификаций параметров системы необходимо разработать критерии (с их весовыми коэффициентами), определяющие стоимость, надежность, защиту от несанкционированного доступа, совместимость и т. д. и описать функции системы в соответствии с этими критериями. В спецификациях учитывается и существующий или достижимый технологический уровень для производства системы. Естественно, что возникающие противоречивые требования должны быть разрешены в соответствии с приоритетами или на другой основе.
На этапе разработки функциональной схемы необходимо в первую очередь решить вопрос о разграничении функций между аппаратурой и программным обеспечением, а также между другими уровнями архитектуры. Здесь же решаются вопросы о необходимости работы с плавающей или фиксированной точкой, о приоритетных прерываниях, о стековой организации памяти и т. д.
При структурной организации все вопросы детализируются и углубляются. В частности, здесь решаются проблемы типов и форматов команд, способов представления данных, способов адресации, семантики языка.
При завершении проекта идет его отладка, согласование взаимодействия отдельных уровней и оптимизация, например, по количеству битов, пересылаемых между процессором и памятью при выполнении данной программы, отысканию эффективного метода кодирования команд и числовой информации и т. д.
И наконец – оценка проекта. Простая оценка быстродействия (которое иногда понимается как производительность) мало что определяет. Здесь необходимо учитывать время, затраченное на разработку программы. Используя известные статистические данные о том, что преобладающее количество разработанных программ выполняется только один раз, простота программирования при оценке архитектуры может оказаться важнее скорости выполнения команд.
Однако скорость выполнения операций – важный параметр. Быстродействие, естественно, зависит как от технологической элементной базы, влияющей на скорость обработки данных, так и от архитектуры машины, которая определяет объем выполняемых работ. Часто архитектуры сравниваются по критерию эффективности обработки информации. Для этого, как правило, анализируют следующие параметры:
S – размер программы, определяемый длиной команд, размером косвенных адресов, объемом рабочих областей для временного размещения
данных;
Np – количество битов, передаваемых между процессором и памятью машины (пересылка между регистрами) за время выполнения программы, характеризующее интерфейс, т. е. "полосу пропускания" между процессором и памятью, что в значительной степени определяет предел эффективности выполнения программ. Ясно, что параметр должен учитывать и локальность ссылок, т. е. близость расположения в памяти используемых данных;
NR – количество битов, передаваемых между внутренними регистрами процессора за время выполнения программы. Здесь учитываются те пересылки, которые не охватывает параметр Np. Значение NR в значительной части определяется набором функций, воплощенных в АЛУ и в схемной реализации процессора.
Иногда архитектуры сравнивают лишь по параметрам S и Np, исключая параметр NR, игнорируя тем самым внутренней организацией процессора.
Архитектура как набор взаимодействующих компонент
Ранее область применения вычислительных систем определялась ее быстродействием. Однако существует достаточно большое количество ВС, обладающих равным быстродействием, но имеющих совершенно разные способы представления данных, методы организации памяти, режимы работы, системы команд, набор ВнУ и т. д. Таким образом, ВС имеет, кроме быстродействия, ряд других характеристик, необычайно важных в той или иной области применения. Это стало особенно заметно при переходе к ВС четвертого и пятого поколений. Совокупность таких характеристик и легла в основу понятия архитектуры ВС.
Архитектура ВС определяет основные функциональные возможности системы, сферу применения (научно?техническая, экономическая, управление и т. д.), режим работы (пакетный, мультипрограммный, разделения времени, диалоговый и т. д.), характеризует параметры ВС (быстродействие, набор и объем памяти, набор периферийных устройств и т. д.), особенности структуры (одно?, многопроцессорная) и т. д. Составные части понятия "архитектура" можно определить следующей схемой (рис. 1.1).
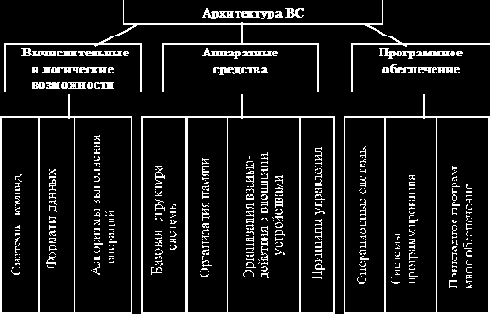 |
Рис. 1.1. Функциональные возможности ВС
Вычислительные и логические возможности ВС. Они обусловливаются системой команд (СК), характеризующей гибкость программирования, форматами данных и скоростью выполнения операций, определяющих класс задач, наиболее эффективно решаемых на ВС. Система команд ВС, базирующихся на архитектуре фон Неймана, сегодня мало чем отличается от СК ЭВМ 50?х годов. Большинство достижений в этой области остались незамеченными проектировщиками и соответственно не нашли адекватного воплощения в архитектуре современных компьютеров.
Анализ показывает, что в различных программах чаще всего встречаются достаточно простые команды: команды пересылки и команды процессора с использованием регистров и простых режимов адресации. Не нашли широкого применения и нетрадиционные способы кодирования данных, несмотря на значительные возможности их в плане разработки быстродействующих алгоритмов арифметических операций.
Среди них знакоразрядные системы, системы в коде вычетов и др.
Рассмотрим структуру системы команд в зависимости от класса решаемых задач (рис. 1.2).
К командам управления мы относим команды ввода-вывода данных и команды управления состоянием процессора, памяти и каналов.
Как видно из рис. 1.2, для решения задач любого класса необходимы
 |
команды типов 2 и 3. Следовательно, эти типы команд должны присутствовать в любом компьютере.
Большое влияние на точность выполнения операций оказывают форматы данных. Современные компьютеры имеют развитую систему форматов. Например, компьютеры фирм ЕС ЭВМ и IВМ имеют форматы в 2, 4, 8 и 16 байт.
Алгоритмы выполнения операций достаточно полно отражают производительность только однопроцессорных ВС.
Аппаратные средства. Простейшая ВС включает модули пяти типов: центральный процессор, основная память, каналы, контроллеры и внешние устройства.
Процессор (УУ + АЛУ + память) управляет работой системы и обеспечивает вычисления непосредственно по программе. Выполнение машинных команд, команд ввода-вывода (I/О), обращение к памяти, управление состоянием устройств инициализируются или выполняются с помощью процессора.
Основная память предназначена для хранения команд и данных и обеспечивает адресный доступ к ним от процессора. Современная память работает со скоростью, близкой к скорости работы процессора.
Каналы – спецустройства, управляющие обменом данных с внешними устройствами. Каналы инициируют свою работу с помощью процессора и затем переходят в автономный режим работы. Это, по сути, спецпроцессор ввода – вывода, обеспечивающий работу внешних устройств, контроль информации и т. д.
Контроллеры ввода-вывода служат для подсоединения внешних устройств (ВнУ) к каналам и обеспечивают обмен управляющей информацией с внешними устройствами, присвоение приоритетов и выдачу информации о состоянии ВнУ для канала, т. е. это устройства управления ВнУ.
ВнУ служат для ввода-вывода информации с различных носителей.
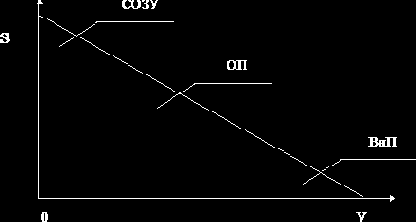 |
Рис. 1.3. Типы памяти (V – объем, S – быстродействие)
Уровни иерархии памяти взаимосвязаны между собой: все данные одного уровня могут быть найдены на более низком уровне.
Успешное или неуспешное обращение к уровню памяти называют соответственно попаданием (hit) или промахом (miss), а соответствующее время – временем обращения (hit time или miss penalty).
Существенное влияние на производительность ВС оказывают каналы ввода-вывода. Мультиплексный канал обеспечивает работу группы медленных устройств, блок-мультиплексный – группы быстрых устройств, селекторный – монополизирует информационную магистраль только одним быстродействующим устройством.
Для повышения пропускной способности каналов используют некоторые дополнительные меры, например буферизацию ВнУ путем введения памяти в состав самого устройства или контроллера.
Аппаратные средства защиты памяти служат для управления доступом к различным областям памяти в соответствии с имеющимися у пользователя полномочиями.
Программное обеспечение. Оно является составной частью архитектуры компьютера и существенно влияет на весь вычислительный процесс, в частности позволяет эффективно эксплуатировать аппаратные средства системы.
Операционная система (ОС) управляет ресурсами, разрешает конфликтные ситуации, оптимизирует функционирование системы в целом.
Широкий спектр языков программирования позволяет описывать практически любые задачи, а разнообразие компиляторов – их эффективно реализовывать.
Роль прикладного программного обеспечения (ПО) необычайно велика для решения тематических задач.
Архитектура MIPS компании MIPS Technology
Архитектура MIPS была одной из первых RISC-архитектур, получившей признание со стороны промышленности. Она была анонсирована в 1986 г. Первоначально это была полностью 32-битовая архитектура, которая включала 32 регистра общего назначения длиною в 32 бита, 16 регистров плавающей точки и специальную пару регистров для хранения результатов выполнения операций целочисленного умножения и деления. В компьютерной промышленности широкую популярность приобрели 32-битовые процессоры R2000 и R3000, которые в течение достаточно длительного времени служили основой для построения рабочих станций и серверов компаний Silicon Graphics, Digital, Siemens Nixdorf и др.
На смену микропроцессорам семейства R3000 пришли новые 64-битовые микропроцессоры R4000 и R4400 (MIPS была первой в компьютерной промышленности компанией, выпустившей процессоры с 64-битовой архитектурой). Набор команд этих процессоров (спецификация MIPS II) был расширен командами загрузки и записи 64-разрядных чисел с плавающей точкой, командами вычисления квадратного корня с одинарной и двойной точностью, командами условных прерываний, а также атомарными операциями, необходимыми для поддержки мультипроцессорных конфигураций. В процессорах R4000 и R4400 реализованы 64-битовые шины данных и 64-битовые регистры. В процессорах реализован метод удвоения внутренней тактовой частоты.
Процессоры R2000 и R3000 имели стандартные пятиступенчатые конвейеры команд. В процессорах R4000 и R4400 применяются более длинные конвейеры (иногда их называют суперконвейерами). Количество ступеней в процессорах R4000 и R4400 увеличилось до восьми, что объясняется прежде всего увеличением тактовой частоты и необходимостью распределения логики для обеспечения заданной пропускной способности конвейера. Процессор R4000 может работать с тактовой частотой 50/100 МГц и обеспечивает уровень производительности в 58 SPECint92 и 61 SPECfp92. Процессор R4400 может работать на частоте 50/100 МГц, или 75/150 МГц, показывая уровень производительности 94 SPECint92 и 105 SPECfp92.
Процессоры R4000 имели внутреннюю кэш- память емкостью 16 Кб, разделенную на 8Кб кэш команд и 8Кб кэш данных. С точки зрения реализации кэш-памяти процессор R4400 имеет более развитые возможности. Он выпускается в трех модификациях: PC (Primary Cash) – имеет внутренние кэши команд и данных емкостью по 16 Кб. Процессор в такой конфигурации предназначен главным образом для дешевых моделей рабочих станций. SC (Secondary Cash) содержит логику управления кэш-памятью второго уровня. MC (Multiprocessor Cash) использует специальные алгоритмы обеспечения когерентности и согласованного состояния памяти для многопроцессорных конфигураций.
Компания MIPS объявила о создании своего нового суперскалярного процессора R10000, который в ближайшем будущем должен появиться на рынке. По заявлениям представителей MIPS Technology, R10000 обеспечивает пиковую производительность в 800 MIPS при работе с внутренней тактовой частотой 200 МГц за счет обеспечения выдачи для выполнения четырех команд в одном такте синхронизации. При этом он обеспечивает обмен данными с кэш-памятью второго уровня со скоростью 3,2 Гб/с.
Чтобы обеспечить столь высокий уровень производительности в процессоре R10000 реализованы многие последние достижения в области технологии и архитектуры процессоров. На рис. 4.7 показана блок-схема этого микропроцессора.
Кэш-память данных первого уровня процессора R10000 имеет емкость 32 Кб и организована в виде двух одинаковых банков размером по 16 Кб, что обеспечивает двухкратное расслоение при выполнении обращений к этой
кэш-памяти. Каждый банк представляет собой двухканальную множественно-ассоциативную кэш-память с размером строки (блока) в 32 байта. Кэш данных индексируется с помощью виртуального адреса и хранит теги физических адресов памяти. Такой метод индексации позволяет выбрать подмножество кэш-памяти в том же такте, в котором формируется виртуальный адрес. Однако для того, чтобы поддерживать когерентность с кэш-памятью второго уровня, в кэше первого уровня хранятся теги физических адресов памяти.
Интерфейс кэш- памяти второго уровня процессора R10000 поддерживает 128-битовую магистраль данных, которая может работать с тактовой частотой 200 МГц, обеспечивая скорость обмена 3.2 Гб/с. Все стандартные
синхронные сигналы управления статической памятью вырабатываются внутри процессора. Минимальный объем кэш-памяти второго уровня составляет 512 Кб, максимальный размер – 16 Мб. Размер строки этой кэш-памяти программируется и может составлять 64 или 128 байт.
Устройство переходов процессора может декодировать и выполнять одну команду перехода в каждом такте. Так как за каждой командой перехода следует слот задержки, максимально могут быть выбраны одновременно две команды перехода, но только одна более ранняя команда перехода может декодироваться в данный момент времени. Бит признака перехода добавляется к каждой команде во время декодирования команд. Эти биты используются для пометки команд перехода в конвейере выборки команд. Направление условного перехода прогнозируется с помощью специальной памяти, которая хранит историю выполнения переходов в прошлом. Двухбитовый код в этой памяти обновляется каждый раз, когда принято окончательное решение о направлении перехода. Все команды, выбранные вслед за командой условного перехода, считаются условными (спекулятивными). Это означает, что в момент их выборки заранее не известно, будет ли завершено их выполнение. Процессор допускает предварительное прогнозирование направления четырех команд условного перехода, которые могут разрешаться в произвольном порядке. Специальный стек переходов содержит строку на каждую выполняемую спекулятивно команду условного перехода. Каждая строка этого стека содержит информацию, необходимую для восстановления состояния процессора, если спекулятивные команды перехода были предсказаны неверно. Стек переходов позволяет быстро и эффективно восстановить конвейер, если прогноз направления перехода оказался неверным.
Процессор R10000 содержит три очереди (буфера) команд (очередь целочисленных команд, очередь команд плавающей точки и очередь адресных команд).
Эти три очереди осуществляют выдачу команд в динамике в соответствующие исполнительные устройства. С каждой командой в очереди хранится тег команды, который перемещается вместе с командой по ступеням конвейера. Каждая очередь осуществляет динамическое планирование потока команд и может определить моменты времени, когда становятся доступными операнды, необходимые для каждой команды. Кроме того, очередь определяет порядок выполнения команд на основе анализа состояния соответствующих исполнительных устройств. Как только ресурс оказывается свободным, очередь выдает команду в соответствующее исполнительное устройство.
Зависимости между командами могут привести к деградации производительности процессора. Чтобы этого избежать, применяется специальная методика, которая называется методикой переименования регистров. Ее основная задача – определение зависимостей между командами и обеспечение точного адреса прерывания программы. В процессе переименования регистров каждый логический регистр, указанный в команде, заменяется физическим регистром на основе таблицы распределения регистров. Такое переименование происходит для каждого регистра результата команды. Поэтому, когда команда записывает в логический регистр новое значение, этот логический регистр переименовывается и будет использовать имя нового физического регистра. Однако его предыдущее значение оказывается сохраненным в старом физическом регистре. Сохранение значений старого регистра позволяет обрабатывать точные прерывания. В то время, как все команды переименовываются, логические номера их регистров сравниваются для определения зависимостей между четырьмя командами, декодированными в одном и том же такте.
В процессоре R10000 имеются шесть полностью независимых исполнительных устройств: два целочисленных АЛУ, два основных устройства плавающей точки и два вторичных устройства плавающей точки, которые работают с длинными операциями, такими как деление и вычисление квадратного корня.
Устройство загрузки-записи содержит очередь адресов, устройство вычисления адреса, устройство преобразования виртуальных адресов в физические (TLB), стек адресов, буфер записи и кэш-память данных первого уровня.
Устройство загрузки- записи выполняет команды загрузки, записи, предварительной выборки, а также команды работы с кэш-памятью.
Внешняя кэш-память второго уровня управляется с помощью внутреннего контроллера, который имеет специальный порт для подсоединения кэш-памяти. Специальная магистраль данных шириной в 128 бит осуществляет пересылки данных на тактовой частоте процессора 200 МГц. В процессоре имеется также 64-битовая шина данных системного интерфейса. Кэш-память второго уровня имеет двухканальную множественно-ассоциативную организацию. Максимальный размер – 16 Мб. Минимальный размер 512 Кб. Пересылки осуществляются 128-битовыми порциями (четыре 32-битовых слова).
Системный интерфейс процессора R10000 работает в качестве шлюза между самим процессором и связанным с ним кэшем второго уровня и остальной системой. Системный интерфейс работает с тактовой частотой внешней синхронизации. Возможно программирование работы системного интерфейса на тактовой частоте 200, 133, 100, 80, 67, 57 и 50 МГц.
Процессор поддерживает протокол расщепления транзакций, позволяющий осуществлять выдачу очередных запросов процессором или внешним абонентом шины, не дожидаясь ответа на предыдущий запрос. Максимально поддерживается до четырех одновременных транзакций на шине.
Процессор R10000 допускает два способа организации многопроцессорной системы. Один из способов связан с созданием специального внешнего интерфейса для каждого процессора системы. Этот интерфейс обычно реализуется с помощью заказной интегральной схемы, которая организует шлюз к основной памяти и подсистеме ввода-вывода. При таком типе соединений процессоры не связаны друг с другом непосредственно, а взаимодействуют через этот специальный интерфейс.
Второй способ предназначен для достижения максимальной производительности при минимальных затратах. Он подразумевает использование от двух до четырех процессоров, объединенных шиной Claster Bus. В этом случае необходим только один внешний интерфейс для взаимодействия с другими ресурсами системы.
Архитектура типа гиперкуб
Гиперкуб представляет собой архитектуру с большим числом 2n процессоров, связанных в систему таким образом, что каждый из них можно представить одной из вершин n-мерного двоичного гиперкуба. Архитектура отличается регулярностью и простотой. Каждый процессор связан только с n другими соседними, и при этом переход между любой парой процессоров – не более чем через n ребер.
Гиперкубы размерностью 0, 1, 2, 3, 4 показаны соответственно на рис. 9.9–9.13. Ясно, что двоичный n-мерный куб регулярным образом связывает 2n процессоров, представляемых вершинами, через n´2n-1 связей, представляемых ребрами, причем каждая вершина связана с n соседними. Максимальный кратчайший путь между вершинами имеет всего n = log2N ребер.
Примером компьютера, построенного по архитектуре гиперкуба, может служить построенная фирмой Thinking Machine параллельная ЭВМ с общим управлением Connection Machine-2 c 216 = 65536 процессорными элементами.
Можно получить различные схемы связи, убирая те или иные ребра. На рис. 9.14 и 9.15 продемонстрированы возможности преобразования архитектуры четырехмерного гиперкуба в трехмерную сетку. Убираемые ребра на этих рисунках отмечены штриховой линией.
 |
Рис. 9.9. Гиперкуб размерности 0
Рис. 9.10. Гиперкуб размерности 1
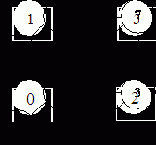 |
Рис. 9.11. Гиперкуб размерности 2
Рис. 9.12. Гиперкуб размерности 3
 |
Рис. 9.13. Гиперкуб размерности 4
 |
Рис. 9.14. Гиперкуб размерности 4 с разорванными связями
Рис. 9.15. Архитектура трехмерной сетки
Следует отметить, что трехмерная сетка не имеет внутренних вершин. Угловые вершины связаны ребрами с тремя соседними вершинами, а остальные – с четырьмя вершинами.
Арифметические операции
1. Сложение.
| Таблица сложения | Примеры сложения чисел: | ||||||||||||||||||||||||||||||||||||||||
| a | b | a) | б) | ||||||||||||||||||||||||||||||||||||||
| -1 | 0 | +1 | |||||||||||||||||||||||||||||||||||||||
| –1 |  | | 0 | 35 | ~ | 1 | 1 | 0 | | 35 | ~ | 1 | 1 | 0 | | ||||||||||||||||||||||||||
| 0 | | 0 | 1 | +15 | ~ | 1 | | | 0 | ?15 | ~ | | 1 | 1 | 0 | ||||||||||||||||||||||||||
| +1 | 0 | 1 | 1 | 50 | ~ | 1 | 0 | | | 20 | ~ | 1 | | 1 | | ||||||||||||||||||||||||||
2. Умножение.
Базовые инструментальные и технологические средстваЯзык и система программирования (СП) Эль-76. Универсальный базовый язык Эль-76 – язык высокого уровня, обеспечивающий сочетание современных средств программирования с доступом ко всем системным возможностям. При реализации большинство конструкций языка имеет полную аппаратную поддержку. Язык Эль-76 используется как язык системного программирования (на нем написаны основные компоненты общего системного программного обеспечения – ОС, включая систему файлов; трансляторы; система динамической диагностики; комплексатор; отладчик и др.); язык проблемного программирования (на нем написаны многие проблемные программы: системы управления, системы автоматизации проектирования, пакеты прикладных программ и др.); язык взаимодействия с операционной системой (он выполняет функции языка управления заданиями, через него доступны такие компоненты ОС, как управление памятью – создание и уничтожение локальных и глобальных массивов; управление массивами переменной длины; управление процессами – создание, запуск, синхронизация и уничтожение процессов; управление программами –открытие; подготовка к исполнению и запуск). Другие компоненты (текстовый редактор, трансляторы и т.д.) доступны через Эль-76 как стандартные процедуры языка управления внешними объектами. Система динамической диагностики. Она осуществляет диагностику динамических ошибок в терминах программы на исходном языке с указанием номера строки, фрагмента исходного текста, имен и текстовых координат вызванных процедур, имен и значений их локальных переменных. Многоязыковый комплексатор. Он осуществляет сборку программ из процедур, написанных на одном или нескольких языках программирования. Отладчик программ в терминах исходного текста. Система получения словаря идентификаторов программы. Она позволяет получить документ, содержащий информацию о точках и характере использования идентификаторов. Компилятор здесь генерирует еще одну структуру – файл ссылок на вхождения идентификаторов. Технологические пакеты для разработки трансляторов: ИНТЕРТЕКСТ – пакет для работы с текстовой формой программы; ИНТЕРФОК – пакет для работы с расширенным файлом объектного кода; ИНТЕРКОД – пакет для генерации и оптимизации кода конкретной модели МВК; ИНТЕРПАМ – пакет для динамической работы с памятью задачи. Системы программирования на базе широко распространенных языков: АЛГОЛ-60; АЛГОЛ-68; КОБОЛ; PL/1; СИМУЛА-67; ФОРТРАН; АДА; МОДУЛА-2; ПАСКАЛЬ; автокод ЭЛЬ-76. ЦЕЛОСТНОСТЬ, СЖАТИЕ И ЗАЩИТА ДАННЫХВ последние годы в связи с увеличением объема информации необычайно остро встает проблема надежного хранения, передачи и обработки информации. Весь спектр вопросов по работе с информацией можно условно разбить на три группы: · философский аспект, состоящий в изучении информационных потребностей общества (духовных, социальных, экономических) и создании возможностей (методов и средств) их эффективного удовлетворения. При этом должно соблюдаться право человека на получение информации; · технический аспект, обусловливающий технические средства, которые обслуживают информационные процессы, предоставляя возможности их качественного обеспечения, в том числе гарантируя такое свойство качества, как безопасность; · управленческий аспект, заключающийся в реализации идеи, что всякий процесс управления есть информационный процесс, базирующийся на сборе, хранении, обработке и передаче информации. При этом качество управления в значительной степени определяется качеством всех действий. На надежность информации в компьютерных системах, исключая несчастные случаи (отключение электроэнергии, стихийные бедствия и тому подобное), существенно влияют: · большое количество устройств, собранных из комплектующих низкого качества или любителями-сборщиками; · нелицензионное ПО; · несовместимость программного и аппаратного обеспечения; · недостаточная компьютерная грамотность сотрудников, ответственных за поддержание компьютерных систем; · экономия средств на главном – качественном оборудовании и обучении персонала. Проблема безопасности информации должна рассматриваться вместе с информационной безопасностью, под которой чаще всего понимают предупреждение отрицательного воздействия информации на любой объект: будь то мировая цивилизация или отдельный человек вне зависимости от формы воздействия – непосредственной, косвенной, направленной или случайной. Некоторые аспекты целостности, сжатия и защиты данных рассматриваются в данной главе. Дублирование | b | B | |||||||||
| 3 | Вызов c | c | B | B | |||||||
| 4 | Сложение | b+c | B | ||||||||
| 5 | Реверсирование | b | b+c | ||||||||
| 6 | Дублирование | b | B | b+c | |||||||
| 7 | Умножение | b2 | b+c | ||||||||
| 8 | Вызов a | a | b2 | b+c | |||||||
| 9 | Дублирование | a | A | b2 | b+c | ||||||
| 10 | Умножение | a2 | b2 | b+c | |||||||
| 11 | Сложение | a2+b2 | b+c | ||||||||
| 12 | Деление |   |
Как следует из табл. 2.5, понадобились лишь три обращения к памяти для вызова операндов (команды 1, 3, 8). Меньше обращений принципиально невозможно. Операнды и промежуточные результаты поступают для операций в АУ из стековой памяти; 9 команд из 12 являются безадресными.
Вся программа размещается в трех 48-разрядных ячейках памяти.
Главное преимущество использования магазинной памяти состоит в том, что при переходе к подпрограммам (ПП) или в случае прерывания нет необходимости в специальных действиях по сохранению содержимого арифметических регистров в памяти. Новая программа может немедленно начать работу. При введении в стековую память новой информации данные, соответствующие предыдущей программе, автоматически продвигаются вниз. Они возвращаются обратно, когда новая программа закончит вычисления.
Наряду с указанными преимуществами стековой памяти отметим также:
* уменьшение количества обращений к памяти;
* упрощение способа обращения к ПП и обработки прерываний.
Недостатки стековой организации памяти:
· большое число регистров с быстрым доступом;
· необходимость в дополнительном оборудовании, чтобы следить за переполнением стековой памяти, ибо число регистров памяти конечно;
· приспособленность главным образом для решения научных задач и в меньшей степени для систем обработки данных или управления технологическими процессами.
выполняет функции обработчика информации,
ЭВМ БЭСМ-6 и ЭВМ Днепр-21 (ИК АН УССР) – единый двухмашинный комплекс. БЭСМ- 6 выполняет функции обработчика информации, а Днепр-21 – функции I/О. При этом обеспечивается связь между многочисленными, в том числе и удаленными терминалами. Связь между машинами реализована через селекторный канал Днепр-21 и седьмой канал БЭСМ-6. Вся вводимая информация накапливается в компьютере Днепр-21 и передается в БЭСМ-6 в таком виде, как будто она вводилась с перфокарт. Редактирование и счет выполняет БЭСМ-6. Выводимая информация поступает в оперативную память Днепр-21 и выводится по мере надобности. Синхронизация работы машин осуществляется посредством передачи управляющей информации между операционными системами машин по диспетчерскому каналу, в качестве которого со стороны БЭСМ-6 использован канал I/О на перфоленту, а со стороны Днепр-21 – мультиплексный канал.
Если, например, в последовательном ЯП определен цикл
for i = L step 1 until N do R(i),
который задает последовательное выполнение вычислений
R(L), R(L + 1), ... , R(N),
то их одновременная обработка требует конфигурации
for i = L step 1
until N do par R(i),
задающей параллельное выполнение этих же вычислений. В связи с тем что понятие параллельного выполнения может быть трактовано по-разному, можно принять в общем случае следующее описание параллельного цикла:
for i = < индексное множество > do < тип параллельности >,
где < индексное множество > задает цикл типа арифметической прогрессии, перечисления, логического выражения и т. д., а < тип параллельности > определяет семантику оператора, например ориентацию на асинхронные ВС с общей памятью, с разделенной памятью, ВС с единым потоком команд ОКМД, возможность синхронизации ветвей с обменом или без обмена информации т. д.
Формальная модель программ на сетях Петри
Информационная зависимость фрагментов программ (ФП) играет определяющую роль при построении параллельных программ. Однако при решении задачи распараллеливания последовательных алгоритмов следует учитывать и логическую подчиненность ФП, которая может существенно препятствовать распараллеливанию наиболее сильно связанных на элементарном уровне ФП. В связи с этим в моделях программ, ориентированных на микроуровень ФП, требуется в значительной степени отражать режим управления вычислениями с учетом логической подчиненности ФП в исходных последовательных схемах и программах. В этом плане достаточно удобен и пригоден для практических целей аппарат сетей Петри, на базе которого построен целый ряд моделей параллельных вычислений.
 |
Графически сеть Петри изображается как ориентированный бихроматический граф (рис. 8.6).
Рис.8.6. Графический образ сети Петри.
Форматы таблиц процессов
Рассмотрим структуру записей в памяти компьютера, описывающих соответствующие процессы. Любой процесс, управляемый хранящейся в памяти программой, имеет два важных параметра:
*
адрес, по которому выбирается следующая команда;
* адрес страницы (блока) данных, который следует прибавлять к каждой ссылке на данные во время обращения.
Периферийный процесс характеризуется типом устройства и адресом данных, участвующих в обмене. Кроме того, каждый процесс может быть "свободным" или "занятым", пока не выполнится определенное условие. Каждому процессу в памяти компьютера соответствует запись примерно следующего формата (рис. 7.5)
Горизонтальное микропрограммирование
 |
Существуют два вида микропрограммного управления: горизонтальное и вертикальное. При горизонтальном – каждому разряду МИК соответствует определенная МИО, выполняемая независимо от содержания других разрядов. Микропрограмма может быть представлена в виде матрицы n ´ m, где n – число ФИ, m – количество МИК, т. е. строка соответствует одной МИК, а столбец – одной МИО (рис. 2.4).
Рис.2.4.
Микропрограмма при горизонтальном
микропрограммировании
Примерные значения разрядов МИК приведены на рис. 2.5.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... |
Рис.2.5. Значение разрядов МИК (МИО):
1 – гашение сумматора; 2 – гашение указателя переполнения; 3 – обратный код сумматора; 4 – гашение регистра множителя частного; 5 – инвертирование знака; 6 – сдвиг содержимого сумматора влево; 7 – сдвиг содержимого сумматора вправо; 8 – увеличение содержимого сумматора на 1; 9 –
чтение из ЗУ в сумматор; …
Наличие "1" в пересечении какой-либо строки и столбца означает посылку ФИ в данную МИК, а наличие "0" – его отсутствие.
Размещение "1" в нескольких разрядах МИК означает выполнение нескольких МИО одновременно. Конечно, возбуждаемые МИО должны быть совместимы.
Пусть, например, разряды 9-разрядной МИК принимают следующие значения: 001001101. Тогда, если заданные разряды соответствуют семантике, указанной на рис. 2.5, то МИО, определяемые разрядами 9, 7 и 6, несовместимы.
Для расширения возможностей МИК иногда используют многотактный принцип исполнения МИК. При этом каждому разряду присваивается номер такта, в котором выполняется соответствующая ему МИО, т. е. здесь все совместимые МИО имеют один номер такта. Все остальные такты нумеруются в порядке их естественного выполнения. Однако универсальную нумерацию МИО в МИК указать затруднительно.
Достоинства горизонтального микропрограммирования:
· возможность одновременного выполнения нескольких МИО;
· простота формирования ФИ (без схем дешифрации).
Недостатки:
· большая длина МИК, так как число ФИ в современных компьютерах достигает нескольких сот, и соответственно большой объем ЗУ для
хранения МИК;
· из-за ограничений совместимости операций, а также из-за последовательного характера выполнения алгоритмов операций лишь небольшая часть разрядов МИК будет содержать "1". В основном матрица будет состоять из нулей. Неэффективное использование ЗУ привело к малому распространению горизонтального микропрограммирования.
Графическое представление процессов
Чаще всего полезно представить процесс в виде некоторого графа, включающего кружки-вершины, соединенные стрелками-дугами. По традиции (терминологической) вершины представляют собой состояния процесса, а дуги – переходы между ними, при этом корневая вершина соответствует начальному состоянию процесса. Дуги помечаются именем события, соответствующего данному переходу.
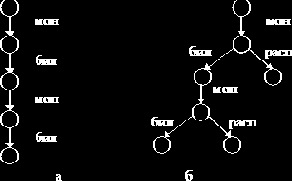 |
Пример 1. Изобразим графически действия автомата, продающего билеты (рис. 7.7, а), и действия автомата, продающего билеты и расписание (рис. 7.7, б).
Рис. 7.7. Графическое изображение действий автомата:
а – автомат, продающий билеты; б – автомат, продающий билеты и расписание
На рис. 7.7 введены следующие сокращения: мон – опустить монету; бил – получить билет; расп – получить расписание.
Вершина без выходных дуг соответствует состоянию СТОП. А если процесс обладает неограниченным поведением, то для его изображения необходимо ввести непомеченную дугу, ведущую из висячей вершины назад к некоторой вершине графа.
Пример 2. Представим автомат, изображенный на рис.7.7, б в более компактной графической форме (рис. 7.8, а).
Доказать графически, что рис. 7.8, а и рис.7. 8, б иллюстрируют в точности один и тот же процесс.
Слабость графической формы состоит в том, что с ее помощью трудно представить процесс с очень большим количеством состояний. Для отображения событий, в которых участвовал процесс, существует понятие протокола.
Протоколом поведения процесса называют конечную последовательность символов, фиксирующую события, в которых процесс принял участие до некоторого момента времени.
Обычно протокол обозначают последовательностью символов, заключенных в угловые скобки:
< > – пустая последовательность, не содержащая событий;
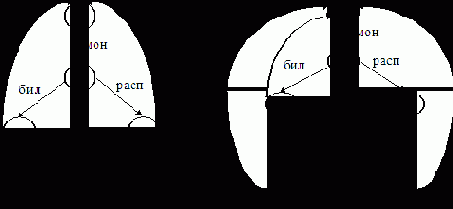 |
Рис. 7.8, а Рис. 7.8, б
< x > – последовательность, содержащая единственное событие x;
< x,y > – последовательность, состоящая из двух событий: x и следующего за ним y.
Пример. Для автомата, продающего билеты, после обслуживания первых двух покупателей протокол будет иметь вид
< мон; бил; мон; бил >.
Протокол того же автомата перед тем, как второй покупатель вынул билет, будет
< мон; бил; мон >.
Понятие протокола сегодня широко используется и в компьютерных сетях. Например, в сети Internet, состоящей из множества сетей различной природы: от ЛВС типа Token Ring до глобальных сетей типа NSFNET, базовым протоколом является TCP/IP (Transmission Control Protocol / Internet Protocol). TCP отвечает за доставку сообщений по указанному адресу, а IP поддерживает адресацию сетевых узлов.
Вообще говоря, TCP/IP – это семейство протоколов и прикладных
программ.
Графическая форма представления протоколов позволяет легче анализировать взаимодействие процессов и разрешать (или предупреждать) различные возникающие ситуации, в частности тупики и гонки.
Хранение информации в виде самоопределяемых данных
Обычно информацию о типе хранимых в памяти данных мы узнаем из команд программы. Однако мы можем в ячейке памяти, где хранятся данные, указать и тип данных (целое, десятичное, символьное и т.д.), дополнив данные некоторым набором битов – тегом. Этот принцип организации памяти получил название теговой памяти. Наряду с типом данных в теге можно хранить и другие характеристики, например длину операнда, информацию об определении текущего значения переменной, использующего данную ячейку памяти, и т. д.
Что дает тег? Известно, что в IBM 370 имеется 15 различных команд ADD, формат одной из них требует двух 4?битовых полей для указания длины обоих операндов. Использование тегов позволило бы ограничиться одной командой, а тип подлежащих сложению операндов и их длину компьютер определял бы путем анализа содержимого тегов соответствующих операндов.
Расширив тег еще одним битом, мы могли бы использовать его в случае обращения к этой ячейке для незапрограммированного прерывания при возникновении определенной ситуации и переходе к процедуре ее обработки.
Бывают два типа тегов: статические, содержимое которых определяется перед выполнением программы и по ходу вычислений не изменяется, и динамическое – с наполнением его содержания во время вычислений и периодическим обновлением.
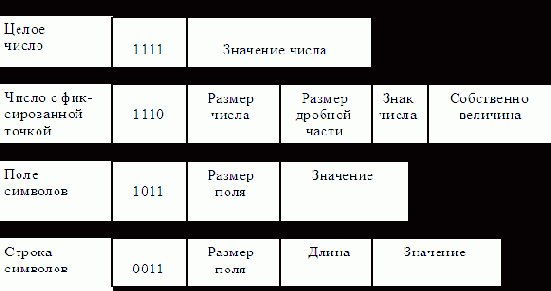 |
Вот пример типов структур элементов теговой памяти, ориентированный на языки программирования (рис. 1.6). Здесь стрелка "¯" разделяет тег и данные.
Рис. 1.6. Типы ячеек при теговой организации
Первые четыре бита определяют тип хранимой величины: целое, число с фиксированной точкой и т. д., затем идет количество цифр, длина и т. д.
Использование тегов позволяет найти некоторые ошибки. Например, может обнаружиться, что одним из операндов команды сложения является строка символов или число с плавающей точкой записывается в качестве адреса, или значение одного из операндов неизвестно и т. д. То есть идет защита типа данных.
Может возникнуть ситуация, когда складываем числа с фиксированной точкой, но позиции точки в числах разные, т. е.
необходимо предварительно выравнять эти позиции. Данные могут отличаться длиной или формой представления. Таким образом, возможно автоматическое преобразование данных.
Теги позволяют повысить скорость обработки команд. Это происходит, во-первых, из-за того, что обычно для преобразования данных надо генерировать компилятором отдельные наборы команд, а во?вторых, отпадает необходимость в извлечении из памяти и декодировании команд преобразования данных. Теги позволяют упростить алгоритмы некоторых операций. Так, для сравнения двух величин необходимо произвести их выравнивание (усечение до меньшей или дополнение до длинной), на что компилятор PL/1, например, генерирует код из 49 команд, а при теговой архитектуре потребуется одна машинная команда.
Структуры команд делаются более регулярными, за счет чего уменьшается разнообразие команд. Однако мы должны задаться вопросом, всегда ли уменьшение количества команд способно эквивалентно отразить исходное разнообразие операций. Всегда ли эквивалентна, например, операция арифметического сдвига и операция деления на 2?
Компилятор становится более простым и быстрым. Это следует из предыдущих рассуждений. Здесь не надо генерировать различный код в зависимости от типа данных, ибо набор команд инвариантен к типу обрабатываемых данных.
Теги позволяют сделать отладку более совершенной. В частности, дамп памяти становится более информативным.
Осуществляется независимость разрабатываемых программных средств от данных благодаря наличию команд, инвариантных к типу данных.
А что будет с объемом памяти для хранения программ и данных? Оказывается, хотя все данные требуют дополнительные поля, но за счет многократного и из многих команд обращения за данными, благодаря устранению избыточности информации в кодах операций команд в машинах с теговой организацией памяти потребуется меньший объем для хранения программ и данных, чем в ЭВМ с традиционной архитектурой. Проведенные эксперименты с программами на языке КОБОЛ показали, что если число обращений к операнду больше 3,5, то теговая организация уже выгодна и по объему памяти.
Среднее же число обращений к одному операнду в некоторых наборах экономических программ имеет коэффициент обращения > 10,4.
Эти рассуждения еще раз подтверждают мысль, что оптимальное решение при проектировании архитектуры машины можно принимать лишь при глубоком анализе ЯП и программ.
Экономия памяти происходит из-за ненадобности повторного генерирования кодов для функций контроля и преобразования данных. Экономии можно достичь и за счет того, что один тег можно заводить для всего массива данных и для всех элементов строки символов, так как последние содержат, как правило, одинаковые атрибуты.
Наряду с тегами, во многих машинах используются и дескрипторы. Это дополнительная информация, выполняющая роль косвенного адреса ячейки памяти с данными. В этих компьютерах команды содержат ссылки на дескрипторы, которые, в свою очередь, содержат ссылки на области памяти, хранящие значения операндов команд.
Основное отличие тегов и дескрипторов состоит в следующем: дескрипторы создают дополнительный уровень адресации, что требует увеличения затрат на формирование адреса, т. е. дескрипторы – это часть команды (программы), а теги – это часть данных.
Пример использования дескрипторов (рис. 1.7).
101 |
P |
I |
R |
W |
Длина |
Адрес |
Здесь первые три бита содержат тег. Если значение его 101, то данное слово дескриптор. Бит P указывает, находятся данные в основной памяти или во вспомогательной; I указывает, одиночный ли элемент описывает данный дескриптор или весь массив; R идентифицирует непрерывную или разрывную область памяти; W означает, что разрешено только чтение данных.
Инструменты разработчиков
Программно-аппаратные средства сжатия данных предназначены не только для конечных пользователей, но и для разработчиков, желающих расширить области применения сжатия данных.
Если говорить о рынке систем общего назначения, то комплекты средств для разработчиков таких систем предлагают фирмы Aladdin Systems и Salient Software. Эти пакеты позволяют использовать алгоритмы, реализованные соответственно в программах Stuffit Deluxe и DiskDoubler, в новых прикладных программах через подсистему взаимодействия прикладных программ ICA.
У программистов, занимающихся обработкой цветных и полутоновых изображений, тоже есть выбор. Одна из лидирующих фирм в этой области, Electronic for Imaging (EFI), предлагает JPTG-совместимую библиотеку функций Ecomp. Эту библиотеку можно использовать как для создания новых программ обработки изображений, так и для модификации уже имеющихся, с целью включить в них функции сжатия образов.
Фирма C-Cube предложила интерфейс сжатия образов ICI (набор соглашений, в соответствии с которыми прикладные программы могут взаимодействовать с аппаратными и программными средствами архивации). Фирма предлагает Compression Workshop – набор исходных текстов на стандартных диалектах языков Си и ПАСКАЛЬ, который позволяет использовать ICI в прикладных программах. Интерфейс ICI обеспечивает сопряжение средств сжатия с программами Photoshop фирмы Adobe, QuarkXpress 3.0, Stuffit Deluxe, Studio-32, а также DiskDoubler Plus. C-Cube также предлагает программно-аппаратный инструментальный комплекс, позволяющий разработчикам оценить по достоинству микросхему CL 550, аппаратно реализующую алгоритм JPEG.
Самый большой файл, который вы могли создать с помощью программы MacPaint для одной страницы, занимал меньше 500 Кб, даже если вы задавали для каждого элемента изображения расширенное описание. Затем появилась 32-битовая программа Color QuickDraw, которая создавала растровые файлы почти в 100 раз большего размера. Тем временем число обычных файлов, которые должен был обрабатывать компьютер, тоже стремительно росло, а появление сканеров еще больше обострило проблему нехватки места на дисках.
Ни одна фирма, производящая программы для цветной графики, не осмелится выпустить свое изделие, не оснастив его встроенными средствами сжатия и восстановления данных (возможно, подключаемыми командой из меню File). Кроме того, ожидается появление новых цветных сканеров и фиксаторов видеокадров со встроенными аппаратными средствами сжатия данных. Фирма Apple, в свою очередь, активно развивает собственные алгоритмы сжатия. Уже в 1990 г. на демонстрации технологий, состоявшейся во время конференции Siggraph, фирма показала собственное программное обеспечение для сжатия и восстановления видеоинформации, которое послужило дополнением системных программ и 32-битовой программы QuickDraw. Столкнувшись с проблемами быстродействия, некоторые производители обратились к специализированным микросхемам типа CL 550 фирмы C-Cube для воплощения алгоритмов сжатия в аппаратуре. Фирма Next создала Nextdimension – 32-разрядный адаптер цветного дисплея. В состав адаптера входят: 64-разрядный графический RISC-сопроцессор и процессор обработки изображений CL 550 фирмы C-Cube. Фирма Apple нашла место для схемы сжатия изображений на плате центрального процессора Macintosh. Схема CL 550 с тактовой частотой 10 МГц была бы в этом случае неплохим вариантом: ее цена близка к цене модуля памяти SIMM емкостью 1 Мб – даже при невысоких объемах производства.
Но разработка аппаратных средств – не единственный путь к повышению быстродействия. Фирма Radius выпустила программы сжатия данных под условным названием Piculator, которая сравнима с аппаратными средствами, реализующими JPEG-алгоритмы, и поэтому может стать приемлемым вариантом для использования в приложениях, интенсивно работающих с графикой. Программа сжимает файл изображения в формате PICT размером 1 Мб менее чем за 6 с на компьютере MacIIсх, и при этом его размер уменьшается в 20 раз и более. При такой скорости работы программы время восстановления файла пренебрежимо мало по сравнению со временем, необходи мым для загрузки прикладной программы.И хотя вначале сжатие данных всерьез интересовало только специалистов по обработке медицинской информации и ученых из НАСА, теперь мы удивляемся тому, как вообще могли обходиться без подобных средств.
ЯПФ-язык
Более удобным в этом плане является язык ярусно-параллельных форм (ЯПФ) Д.А. Поспелова. Программа на ЯПФ представляет собой мультиграф, задаваемый, например, в матричной форме. Вершинами мультиграфа являются операторы, мультиграф не имеет контуров. Дуги данного мультиграфа бывают двух типов: информационные и управляющие. При выполнении программы на ЯПФ первоначально выделяется нулевой ярус (множество операторов, не имеющих непосредственных предшественников по информационным дугам) (рис. 10.1) и инициируется выполнение операторов из этого
множества. После их выполнения убираются все информационные дуги, вы-
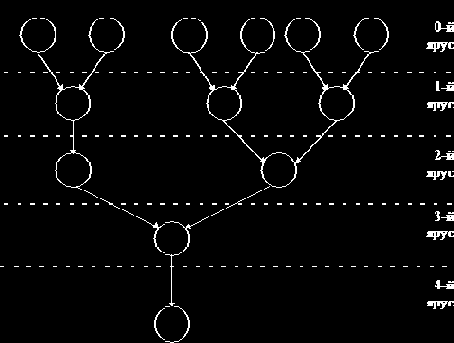 |
Рис. 10.1. ЯПФ-представление алгоритма
ходящие из нулевого яруса, и в оставшемся графе таким же образом выделяется первый ярус.
Процесс продолжается от яруса к ярусу. После выполнения управляющего оператора, из которого выходят управляющие дуги, происходит выбор одного из операторов, в которые заходят эти дуги. Процесс обработки ЯПФ-программы завершается, когда выполнены все операторы из яруса с наибольшим номером.
Однако представление программы в ЯПФ требует "развертки" циклических участков программы, что не позволяет использовать ее как язык практического параллельного программирования.
Язык диспозиций
Определим некоторый класс формальных описаний задач, которые будут включать в себя как основные известные определения алгоритмов, так и некоторые неалгоритмические описания. Последние отличаются от алгоритмических тем, что в них, кроме предписаний выполнить данное преобразование текста по некоторому правилу, используются также разрешения выполнять некоторые преобразования. Такие схемы описания задач будем называть диспозициями. Предписание является вырожденным случаем разрешения, когда разрешается только одно преобразование.
Будем задавать диспозицию D знаковой системой S, множеством операторов M = {A1, A2, ..., An} (в дальнейшем оно предполагается конечным) и графом диспозиции Г(D). Каждый оператор Ai имеет один вход и Pi выходов (S1, S2, ... , SРi). Оператор Ai осуществляет некоторое преобразование Ai текстов в знаковой системе S и проверяет серию условий w0i, w1i, ... , wki. Когда оператор Ai применяется к тексту T, он проверяет, удовлетворяет ли текст T серии условий
w0i, w1i, ... , wki, и преобразует текст T по правилу Ai в текст T¢. Особую роль играет условие w0i, которое будем называть условием применимости оператора Ai. Если оно выполняется (w0i = 1), то оператор работает, как было описано выше. Иначе (т. е. если w0i = 0) оператор Ai оставляет текст неизменным (т. е. T¢ = T). Для каждого оператора Ai задается Pi функций:
j1i (w0i, w1i, ... , wki);
j2i (w0i, w1i, ... , wki);
. . .
jРii (w0i, w1i, ... , wki).
Каждая из этих функций может принимать два значения: 1 (возможно) и 0 (невозможно). Будем называть систему функций правильной, если для каждой функции существует, по крайней мере, один набор значений аргументов, при котором она принимает значение 1.
Графом диспозиции Г(D) будем называть связный граф, вершинам которого сопоставлены либо операторы диспозиции D, либо знак #. Вершины обладают следующими свойствами:
· имеется только одна вершина, называемая входом диспозиции, и обозначается aвх;
· имеется, по крайней мере, одна вершина, из которой не исходит ни одна дуга и которой сопоставлен знак #. Эти вершины называются выходами диспозиции и обозначаются aвых1, aвых2, ..., aвыхn;
· вершинам, которые не являются выходами, сопоставлены операторы диспозиции. При этом, если из вершин исходит n дуг, то ей может быть сопоставлен только тот оператор Ai, число выходов которого Pi ³ n. Каждый выход оператора Ai сопоставляется одной из дуг, исходящих из соответствующей вершины a. Каждой дуге, исходящей из a, должен быть сопоставлен, по крайней мере, один из выходов оператора Ai.
Граф Г(D) и соответствующую ему диспозицию D назовем правильными, если выполняются следующие дополнительные требования:
· из любой вершины графа Г существует путь, по крайней мере, в
один выход;
· для каждой вершины графа Г существует путь, ведущий из входа в
эту вершину.
Так определенная диспозиция задает систему допустимых последовательностей преобразований текста, а именно: если задан начальный текст T0, то оператор, сопоставленный входу диспозиции aвх, проверяет условие w0 i; если оно не выполнено (w0 i = 0), то текст T0 не меняется; если же w0 i = 1, то к тексту T0 применяется преобразование, соответствующее данному оператору, причем до выполнения этого преобразования вычисляются значения w1i, w2i, ... wki. После преобразования текста вычисляются значения функций
j1i, j2i, ..., jрii.
Те функции jj, которые принимают значение 1, определяют дуги, исходящие из входной вершины графа диспозиции, по которым возможен переход в следующую вершину. Один из этих переходов должен быть осуществлен. Тем самым на следующем шаге процесса реализации диспозиции выбирается одна из смежных с предыдущей вершина графа Г(D).
Если все функции jj = 0, то процесс останавливается. Эта ситуация называется безрезультатной остановкой.
Оператор диспозиции, сопоставленный этой вершине, применяется к полученному тексту таким же образом, как входной оператор применяется к исходному тексту T0.
Если этой вершине сопоставлен знак #, то процесс на этом заканчивается, и образовавшийся к этому моменту текст считается результатом диспозиции.
Одному и тому же начальному тексту может соответствовать несколько результатов (если один, то диспозиция однозначна).
Диспозиция называется алгоритмической, если для любого начального текста на каждом шаге возможен (а следовательно, и предписан) переход только к одной вершине графа Г(D).
Заметим, что алгоритмическая диспозиция еще не обязательно есть алгоритм, так как сами преобразования могут быть определены неоднозначно (например, марковские подстановки без указания на то, какое вхождение слова берется). Мы уже использовали понятие “реализация диспозиции”, описывая, как диспозиция преобразует исходный текст. Определим реализацию диспозиции D формально.
Будем рассматривать в графе Г(D) пути (называемые сквозными), состоящие из последовательности вершин:
al0 = aвх, al1, ..., aln, aln+1 = aвыхj,
так как ali ®







Знак ® означает: поставлен в соответствие.
Иногда удобнее описывать метод решения ряда задач как диспозицию, а затем уже тем или иным способом переходить к алгоритмам решения этих задач. Чтобы выделить алгоритмические диспозиции, следует рассматривать только такие наборы M операторов, что для " Ai Î M не более чем одна из функций j1i, j2i, ..., jрii принимает значение 1 вне зависимости от набора значений аргументов.
Пример. Рассматриваются слова в алфавите Z. Задан список слов П в алфавите Z. Слово B называется возможной основой слова C, если последнее может быть представлено в виде
D1 D2 ... DnB,
где n ³ 0 и "i (Di Î П.
Требуется для каждого слова найти все его возможные основы. Пусть
Z = {a, b, c, d}, Z¢ = {Z È ®} и П = {a, ab, ba}.
Тогда возможными основами слова abacd будут слова abacd, bacd, acd, cd, а слова babcd – слова babcd, abcd, bcd, cd.
Построим диспозицию для решения этой задачи:
M = {A1, A2, A3, A4, A5}.
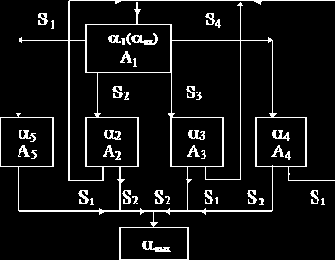 |
Рис. 10.2. Граф-схема диспозиции
Оператор A1
приписывает к исходному слову слева букву ®. Операторы A2, A3, A4 отделяют от слова, к которому они применяются, соответственно префиксы a, ab и ba (вместе с начальной буквой ®). Описание операторов находится в табл. 10.1.
Язык OCCAM
Для многотранспьютерных систем английскими учеными был создан специальный язык параллельного программирования OCCAM, детальное описание которого было дано в 1984 г. в книге "INMOS Limitid Occam Programming Manual". В отличие от ЯПП, например, Concurent Fortran или Concurent Pascal, он не построен путем расширения известных последовательных ЯП.
Теоретической основой данного языка является язык CSP (Com-municating Sequential Processes), разработанный Т. Хоаром. Основным понятием языка является процесс (примитивный, составной, именованный), напоминающий процедуры и подпрограммы обычных языков программирования.
Простейшим примитивным процессом является процесс SKIP.
Если именованный процесс имеет список формальных параметров, то они следуют в описании процесса после его имени с указанием ключевых слов VALUE, VAR и CHAN, обозначающих их природу: соответственно значение, переменная или канал.
Процессы взаимодействуют с помощью каналов и могут выполняться как последовательно, так и параллельно. Так как в системе команд транспьютера имеются команды, предназначенные для компиляции примитивных процессов считывания из канала и записи в канал, то эти процессы хорошо согласуются с транспьютерной архитектурой. При этом операции создания процессов, их планирования и синхронизации представляются программисту столь же "примитивными" действиями, как и такие операции, как скажем, вызов процедуры в языках последовательного действия.
Последовательный процесс задается перечислением за ключевым словом SEG всех его компонент, которые должны выполняться последовательно.
Для описания параллельного процесса после ключевого слова PAR задаются необходимые составляющие его процессы. Выполнение параллельной композиции (PAR-процесса) состоит в выполнении каждой его компоненты до полного их завершения.
Выбор процесса для исполнения в зависимости от готовности других процессов задается через ALT-процесс.
Все имена в Occam-программе до их использования должны быть опи- саны.
Описания позволяют именовать значения констант (ключевое слово DEF), переменных (ключевое слово VAR) и каналы (ключевое слово CHAN). При этом должны быть определены два параллельных процесса: передача в канал и прием из канала в области действия описания каждого канала.
В языке OССАМ существует только один вид структурированных данных– одномерный массив. В Occam-2 допускается использование двумерных и трехмерных массивов различных объектов: констант, переменных и каналов.Описание массива включает его имя, за которым в квадратных скобках записывается константное выражение:
имя [количество].
Например, выбор символов строки string [ ] через канал output будет иметь вид
PROC write. string (CHAN output, VALUE string []).
Язык OССАМ постоянно развивается в связи с совершенствованием транспьютеров и доведением его до языка высокого уровня с естественным расширением класса решаемых задач. При этом выдерживается основной принцип языка: число сущностей не следует умножать без надобности.
Пока трудно сказать, насколько мы приблизились к созданию качественного и практичного ЯПП. Все зависит от класса решаемых задач, архитектур разрабатываемых компьютеров и, естественно, подвержено фактору времени. Для ВС, содержащих небольшое число процессоров, можно с успехом использовать ЯП АЛГОПП, АДА, МОДУЛА-2, OССАМ, имеющие достаточные средства организации параллельных ветвей, синхронизации управления в параллельных ветвях и средства обмена информацией между ветвями.
ЯЗЫКИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
При эксплуатации первых многопроцессорных ВС для повышения эффективности их работы возникла необходимость в параллельных алгоритмах, а следовательно, и в языках параллельного программирования
(ЯПП), имеющих специальные средства для описания параллельных процессов. ЯПП в первую очередь должны предоставлять программистам средства для описания явного и обнаружения скрытого параллелизма. На сегодняшний день разработаны параллельные алгоритмы во многих областях обработки информации. Поэтому нужен язык, который позволял бы описывать имеющиеся параллельные алгоритмы. На создание подобных языков существенное влияние оказывают принципы, заложенные в языках моделирования различных явлений, ибо они включают мощные средства отображения параллельных процессов. Кроме того, при разработке языков необходимо учитывать те средства описания параллелизма, которые присутствуют в современных языках программирования (АЛГОЛ-68, ПАСКАЛЬ, PL/1, МОДУЛА и др.), и структуру параллельных методов численного решения задач.
Среди ЯПП можно выделить две группы языков исходя из средств задания взаимодействий между параллельными процессами:
· взаимодействия фрагментов (процессов) через доступ к общим пе-ременным;
· взаимодействия посредством передачи межпроцессорных сообщений.
Еще один из возможных признаков классификации языков – число вовлекаемых во взаимодействие процессов. Можно выделить языки, обеспечивающие явное задание:
· индивидуальных (парных) взаимодействий между фрагментами: механизм подчиненных процессов ОС/360, язык взаимодействующих процессов Хоара, ОССАМ, язык граф-схем;
· групповых взаимодействий между фрагментами (процессами): ОВС-КОБОЛ (ФОРТРАН), параллельный КОБОЛ, языковые средства суперкомпьютера ИЛЛИАК-4.
Для решения проблемы диспетчеризации, т. е. распределения задач по процессорам (машинам), необходимо разрабатывать методы распознавания и выделения независимых фрагментов программ. При этом в качестве исходных позиций для решения этой задачи можно выделить следующие:
· кто и когда осуществляет разбиение исходной программы и распределение по процессорам;
· какое время сохраняется разбиение;
· каковы максимально неделимые участки;
· какие критерии используются при разбиении и распределении.
Эталонная модель сети
Наличие больших объемов вычислений внутри учреждений, без выхода (передачи) информации за их пределы, и заметный рост информации, передаваемой между учреждениями, привели к тому, что рядом фирм были разработаны вычислительные сети. Однако большое разнообразие в их архитектурных решениях затрудняло обмен информацией между сетями. Для упрощения решения этой проблемы требовалось стандартизировать многие решения по сетям. Поэтому в 1977 г. при Комитете по вычислительной технике и обработке информации Международной организации по стандартизации (ISO, International Organization for Standartization) был образован новый подкомитет с целью создать модель межсетевого взаимодействия, на базе которой можно было бы разрабатывать основные направления стандартизации по сетям.
В 1979 г. была создана эталонная модель взаимодействия открытых систем (OSI, Open System Interconnection), называемая обычно «семиуровневой моделью» (рис. 3.1). Функции взаимодействия делятся на ряд слоев, именуемых уровнями (layers). Все уровни модели взаимодействуют строго по иерархической системе: каждый уровень обслуживает уровни, находящиеся выше его, и пользуется услугами уровней, расположенных ниже. Иерархия уровней следующая: физический, канальный, сетевой, транспортный, сеансовый, представления данных и прикладной. Правила взаимодействия объектов одноименных уровней различных систем называют протоколами, правила взаимодействия объектов смежных уровней одной и той же системы – меж-уровневым интерфейсом. Все протоколы связи соответствующих уровней
| Уровень OSI | ||||||||||
| 7 | Прикладной | ................... | Прикладной | |||||||
| Информационные процессы | 6 | Представления данных | Протоколы
................... | Представления данных | ||||||
| 5 | Сеансовый | ................... | Сеансовый | |||||||
| Транспортный
процесс | 4 | Транспортный | ................... | Транспортный | ||||||
| Коммуника- | 3 | Сетевой | ................... | Сетевой | ||||||
| ционные | 2 | Канальный | ................... | Канальный | ||||||
| процессы | 1 | Физический | ................... | Физический | ||||||
| Физическая среда | ||||||||||
| Взаимодейству-ющая машина | Операцион-ная среда | Взаимодейству-ющая машина | ||||||||
Рис.3.1. Эталонная модель взаимодействия открытых систем
взаимодействующих устройств были стандартизованы. После определения полного набора протоколов любые два устройства смогут взаимодействовать, несмотря на свои конструктивные особенности, функциональное назначение или внутренний интерфейс. В модели OSI под открытой системой понимается система, выполняющая стандартное множество функций взаимодействия, принятое в информационно-вычислительной сети. На верхнем уровне взаимодействия мы соприкасаемся с прикладными процессами и включаем в модель те их части, которые связаны с передачей информации между системами. Основные части прикладных процессов, связанные с хранением и обработкой информации, в модели не рассматриваются.
На нижнем уровне функции взаимодействия связаны с физическими средствами соединения, по которым передается информация между системами. Топология, структура и параметры этих средств в эталонной модели не рассматриваются.
В информационно-вычислительной сети используются три типа соединений: одностороннее (от одного объекта к другому либо к другим); поочередное двухстороннее (передача информации поочередно в обе стороны); одновременное двухстороннее (передача идет сразу в обе стороны).
Объекты N-го уровня взаимодействуют друг с другом через соединения, создаваемые на (N-1)-м уровне. Все уровни в эталонной семиуровневой модели существуют только для того, чтобы обеспечить работу основного прикладного уровня.
В соответствии с уровнями сети в логической структуре всех систем также выделяются семь уровней взаимодействия. Три верхних уровня определяют информационные процессы, выполняемые в системе, транспортный процесс определяет процедуры передачи информации от системы-отправителя к системе-адресату. На трех нижних уровнях выполняются коммуникационные процессы, осуществляющие передачу данных между множеством взаимодействующих систем.
Физический уровень (physical layer) обеспечивает интерфейс между машиной, участвующей во взаимодействии, и средой передачи сигналов и управляет потоком данных.
Стандарты физического уровня включают рекомендации V.24 МККТТ, EIA RS232.
Канальный уровень (link layer) обеспечивает средства установления, поддержания и освобождения линий передачи данных, связывающих системы друг с другом. Он формирует из данных, передаваемых первым уровнем, так называемые "кадры" или последовательности кадров, осуществляет управление доступом к передающей среде, используемой несколькими машинами, обнаруживает и исправляет ошибки. Самым известным стандартом этого уровня является стандарт ISO – высокоуровневый протокол управления каналом HDLC (High Level Data Link Control).
Сетевой уровень (network layer) реализует функции маршрутизации, чтобы "кадры" II уровня, здесь уже называемые, как правило, "пакетами", могли передаваться через несколько каналов по одной или нескольким сетям. Обычно это требует включения в пакет сетевого адреса, причем адрес скорее относится к подключаемой машине, чем к узлам коммутации. На сетевом уровне осуществляется управление потоками данных, которыми обмениваются системы, не связанные друг с другом физическими соединениями. Самый известный стандарт этого уровня – рекомендации X.25 МККТТ (для сетей общего пользования с коммутацией пакетов).
Транспортный уровень (transport layer) обеспечивает взаимодействие процессов в подключенных машинах и сквозное управление движением пакетов между этими процессами, что освобождает отправителя от необходимости ориентироваться на конкретный способ передачи данных.
Рассмотренные уровни (с I по IV) можно рассматривать как уровни передачи данных, уровни же V–VII – это уровни обработки данных.
Сеансовый уровень (session layer) организует и поддерживает сеансы взаимодействия (диалог) между прикладными процессами определенного типа, обрабатываемыми на разных компьютерах. Может быть разрешено несколько сеансовых уровней (а значит, и несколько протоколов) для таких различных по типу процессов, как передача речи в цифровом коде и интерактивные вычисления.
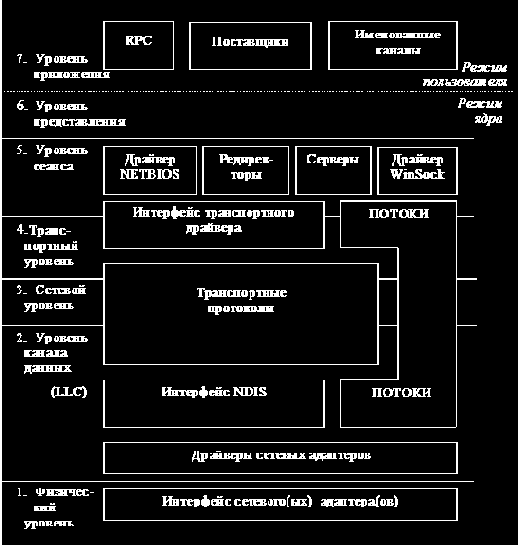 |
Рис. 3.2. Уровни сетевой архитектуры Windows NT
Уровень представления данных ( presentation layer) осуществляет интерпретацию данных (форматов, кодов, структур, команд), передаваемых во время диалога между прикладными процессами. На передающем компьютере этот уровень преобразует данные из формата, посылаемого прикладным уровнем, в общепринятый формат, а на принимающем компьютере идет обратное преобразование. При управлении экраном терминала реализуются и другие функции, например выделение на экране особо важных полей, защита от стирания некоторых частей экрана и т. д.
Прикладной уровень (application layer) реализует все функции, которые необходимы для обслуживания прикладных процессов и которые не были реализованы всеми предыдущими уровнями. Это функции обслуживания сети, управления заданиями, протоколы обмена данными определенного ти-
па и т. д.
Прикладным процессом называют основной компонент системы, осуществляющий обработку информации для пользователей или административное управление сетью. Прикладной процесс является либо источником, либо потребителем информации.
Примеры прикладных процессов:
· человеко-машинный, в котором человек-оператор работает у пульта терминала;
· внутримашинный, определяемый программой работы с данными, расположенными в ЭВМ;
· производственный, обеспечивающий сбор информации и управляющий технологическим процессом.
Прикладные процессы административного уровня связаны с управлением ресурсами, расположенными на всех уровнях системы.
В реальных системах уровни эталонной модели реализуются по-разному. Имеются свои особенности и для ЛВС. На рис. 3.2 показано, как в Windows NT реализована модель OSI.
Здесь NDIS (Network Driver Interface Specification) – спецификация интерфейса сетевого драйвера, LLC (Logical Link Control) – подуровень управления логической связью уровня канала данных, а RPC (Remote Procedure Call) – поддержка удаленных вызовов процедур.
К-язык
В качестве языка параллельного программирования был разработан так называемый К-язык. Суть языка: задается множество элементарных операторов и множество порождающих правил построения алгоритмов, образующие некоторое исчисление. Запись вывода в этом исчислении и является К-программой. Имеются три типа основных порождающих правил: суперпозиция, дизъюнкция, рекурренция. Правило суперпозиции означает, что результаты выполнения операторов b1,b2, ..., bk
служат аргументами для некоторого оператора B. Порядок выполнения операторов b1, b2, ..., bk безразличен, что и порождает параллелизм в их выполнении. Правило дизъюнкции задает ветвление в К-программе, а правило рекурренции – цикличность. К-язык относится к языкам асинхронного типа.
Классификация и особенности программных методов защиты от копирования
Защитные механизмы по способу своего внедрения в защищаемый программный модуль могут быть пристыковочными и/или встроенными.
В пристыковочной защите работа модуля, ее осуществляющего, по времени не пересекается с работой защищаемого модуля. Как правило, сначала отрабатывает модуль защиты, затем – защищенный модуль. В этом случае обычно можно отследить момент передачи управления от пристыковочного модуля к защищаемому и обойти систему защиты без ее анализа.
Эффективной и надежной является та система, "взлом" которой достаточно долог и трудоемок. Основным параметром, определяющим эффективность средства защиты, является время, необходимое на снятие защиты.
Существуют две проблемы:
· не потеряет ли программа за время снятия ее защиты своей актуальности, т. е. не устареет ли ее информация;
· не превысят ли затраты на снятие защиты стоимости программы.
На сегодняшний день защита строится на внедрении в защищаемый модуль дополнительного модуля, осуществляющего некоторую проверку перед запуском основного модуля. В случае совпадения сравниваемых признаков осуществляется передача управления основному модулю. Иначе обычно происходит выход в операционную систему или "зависание" программы.
Более эффективной является встроенная защита, которая может отрабатывать как до начала, так и в процессе работы функционального модуля. Для создания эффективной встроенной защиты наиболее приемлемы такие защитные механизмы, которые проверяют какие-то специфические характеристики компьютера. Наиболее типичными характеристиками компьютера, к которым чаще всего осуществляется "привязка" защищаемой программы, являются:
· временные характеристики (быстродействие различных компонент компьютера: процессор, память, контроллеры и т. д.; скорость вращения двигателей дисководов; время реакции на внешние воздействия);
· тип микропроцессора и конфигурация машины (тип микропроцессора и разрядность шины данных, наличие и тип контроллеров внешних
устройств);
· характерные особенности компьютера (контрольная сумма BIOS; содержимое СМОS-памяти; длина конвейера шины данных; аномальные явления при программировании микропроцессора).
Временные характеристики компьютера в наибольшей степени отражают индивидуальные особенности машины. Однако ввиду нестабильности электронных элементов компьютера происходит нестабильность показателей быстродействия его компонент. Это приводит к усложнению защитного механизма, в функции которого должно входить нормирование замеренных временных показателей.
С точки зрения защиты программ от исследования отладочными средствами очень интересно использование конвейера шины данных микропроцессора. Программа в этом случае должна определить, идет ли выполнение программы с трассировкой или нет и осуществить ветвление в зависимости от принятого решения.
Еще одним интересным и эффективным способом защиты программ от несанкционированного копирования (НСК) является использование аномальных явлений, с которыми приходится сталкиваться при программировании микропроцессора. Информацию о них чаще всего можно получить лишь экспериментальным путем. Это такие особенности работы компьютера, которые являются исключением из общих правил его функционирования. В качестве примера такого аномального явления может служить потеря одного трассировочного прерывания после команд, связанных с пересылкой сегментных регистров. Это свойство может применяться для недопущения работы программы под отладчиком.
Наиболее эффективным методом программной защиты выполняемых программ от НСК является их защита на этапе разработки. Модули защиты могут располагаться в нескольких местах программы, что значительно затруднит работу "взломщика" по поиску в дизассемблированной программе тех мест, где производится проверка каких-либо параметров машины. Это особенно эффективно, если программа написана не на Ассемблере, а на языке высокого уровня (С, ПАСКАЛЬ и др.).
Можно отметить два существенных момента:
· не использовать для защиты нескольких программ стандартные программные модули;
· не оформлять эти модули в виде процедур и функций, вызов которых производится в основной программе.
Первое обусловлено тем, что стандартный защитный модуль может быть обнаружен "взломщиком" при сопоставлении нескольких защищенных таким образом программ.Этот модуль будет иметь один и тот же вид в дизассемблированных кодах различных программ.
Второе обусловлено легким поиском в дизассемблированной программе места вызова модуля защиты.
Все вышеизложенное позволяет сделать следующий вывод: для создания достаточно эффективной и надежной программной защиты от НСК необходим индивидуальный подход к созданию нестандартных механизмов защиты и включению их в основную программу на этапе ее разработки.
Классификация ошибок и их характеристики
Систематические ошибки. Они появляются, как правило, в результате отказов одного или нескольких схемных элементов, входящих в цепи передачи информации или в устройства, с помощью которых выполняются арифметические и логические операции. Если повторяется одна и та же операция над одними и теми же данными, ошибка будет повторяться всякий раз. При других данных или других операциях она может и не повторяться. Тем не менее вычисления бессмысленны.
Случайные ошибки. Это результат сбоя в элементах машины. Эти ошибки – источник основных затруднений для эффективной эксплуатации ВС. Единственный способ установить наличие или отсутствие ошибки – это контроль каждой операции или всего решения в целом.
Одиночные и кратные ошибки. Определение их зависит от вида обработки информации, характера операции и т. д. При хранении информации или ее передаче одиночная ошибка состоит в изменении одного двоичного знака. Если же изменению подверглось несколько знаков, ошибку называют кратной. Так же определяются ошибки результата поразрядных логических
операций.
Иначе дело обстоит с ошибками в результатах арифметических операций. При выполнении сложения, например, ошибка в одном разряде из-за переносов может привести к тому, что двоичные символы в нескольких позициях будут неправильными. То же самое – сбой в цепи переноса. Тем не менее такие ошибки классифицируются как одиночные, ибо разность между правильным результатом и ошибочным будет иметь единицу только в одной
позиции.
Пример. Пусть правильный результат ~ 101111, а нами получен ~ 110000. Результаты отличаются в пяти позициях, но их разность равна 000001. Следовательно, ошибка одиночная.
Кратными считаются ошибки (две и более), которые произошли независимо при выполнении одной операции в нескольких разрядах.
С повышением кратности обнаружение и исправление ошибок затруд-
няются.
Наиболее просто обнаруживать и исправлять одиночные ошибки. Поэтому важно выяснить законы распределения вероятностей ошибок в числе или слове.
Наиболее просто это сделать для компьютера параллельного действия. Здесь каждый двоичный разряд передается по отдельному каналу и обрабатывается в отдельных устройствах, связанных друг с другом только цепями переноса. Следовательно, возникновение ошибок в отдельных двоичных разрядах можно считать независимыми случайными событиями, имеющими одинаковую вероятность. Тогда для ошибок i-й кратности в n-разрядном числе справедлив биномиальный закон распределения:
 |
(3) |
Формула (3) позволяет определить вероятность ошибки i-й кратности при условии, что в остальных n–i разрядах ошибок нет. Из формулы (3) следует, что для очень малых значений q наибольшую вероятность имеет случай одиночной ошибки.
Для компьютеров последовательного действия положение осложняется тем, что ошибки в разных разрядах числа происходят, вообще говоря, в разное время. Поэтому кратность ошибок в числе, очевидно, зависит от соотношения между быстродействием узлов компьютера и длительностью сбоя. Во всяком случае, вероятности кратных ошибок следует ожидать более высокими, чем в предыдущих случаях, при одинаковой вероятности сбоя в ап-
паратуре.
То же можно сказать о ЗУ на НМЛ и НМД. Запись и чтение информации с них обычно выполняются последовательным или последовательно-параллельным способом. Кроме того, причиной ошибок могут быть различные механические повреждения магнитной поверхности. При большой плотности записи последняя ситуация является источником целой группы ошибок.
Код
Окончание таблицы 11.4.
| 1 | 2 | 3 | |||
| l | 2 | 11011 | |||
| i | 2 | 11110 | |||
| d | 2 | 11111 | |||
| y | 2 | 100000 | |||
| f | 1 | 100110 | |||
| m | 1 | 100001 | |||
| n | 1 | 100010 | |||
| O | 1 | 100011 | |||
| P | 1 | 100100 | |||
| U | 1 | 100101 | |||
| При сжатии текстовых файлов часто встречающиеся символы или последовательности символов заменяются кодовыми последовательностями длиной меньше обычных 8 бит.
Длина исходного файла= 366 бит (42 символа х 8 бит). Длина сжатого файла = 187 бит. |
Алгоритм Лемпеля–Зива (LZ), или Лемпеля–Зива–Уэлча (LZW). Это еще одна схема сжатия, основанная на сведении к минимуму избыточности кодирования. Вместо кодирования каждого отдельного символа LZ-алгоритм кодирует часто встречающиеся символьные последовательности. Например, можно заменить краткими кодами слова "который" "так же", "там", оставляя имена собственные и другие слова, встречающиеся один раз, незакодированными. Программа, реализующая LZ-алгоритм, просматривает файл, содержащий текст, символы или байты графической информации, и выполняет статистический анализ для построения своей кодовой таблицы.
Если заменить 60–70 % текста символами, длина кода которых составляет менее половины первоначальной длины, можно достигнуть сжатия приблизительно в 50 %. При попытке применить этот алгоритм к исполняемым файлам получаются менее впечатляющие результаты (от 10 до 20 % сжатия), так как избыточность кода, создаваемого компиляторами, значительно меньше избыточности текста на естественном языке. Файлы баз данных – еще один трудный случай: записи, содержащие имена, адреса и номера телефонов, редко повторяются, а поэтому плохо поддаются сжатию. В то же время файлы монохромных изображений в формате PICT архивируются довольно хорошо, так как зачастую обладают большой избыточностью, например содержат много белого пространства. Файлы полутоновых и цветных изображений также можно архивировать с помощью алгоритма Хаффмана, хотя и с меньшим успехом.
Большинство пользователей компьютеров Мaс знакомо с утилитами архивации общего назначения. В качестве примера можно привести популярные программы Stuffit Classic и Stuffit Deluxe фирмы Aladin Systems и Compactor фирмы Goodman. Такие программы в основном используют для сжатия нескольких файлов в один архивный файл. Другая программа сжатия – DiskDoubler фирмы Salent Software – представляет собой скорее утилиту для работы с диском, чем архиватор. Двойное нажатие клавиши на манипуляторе "мышь" автоматически запускает программу разархивирования отмеченного файла, а когда вы закончили работать с файлом и сохраняете его на диске, DiskDoubier автоматически выполнит обратную операцию.
Код с проверкой на четность
Код с проверкой на четность образуется добавлением к группе информационных двоичных знаков одного контрольного. Значение его выбирается таким образом, чтобы общее число единиц в слове было четным или нечетным. После чтения или записи данных в память проверяется, сохранен ли принцип записи. Здесь d = 2. Обнаруживаются одиночные ошибки и групповые с нечетной кратностью. Целесообразно дополнять "до нечета", чтобы отличить "0" от отсутствия информации в слове, ибо в этом случае в слове будет хотя бы одна единица.
Рассмотренные выше коды используются лишь для повышения надежности передачи информации. Они непригодны для контроля выполнения операций в компьютере. Действительно, все рассматриваемые коды основаны на определении изменения исходного кода. При выполнении арифметических и логических операций (АЛО) код всегда изменяется, даже если он без ошибок.
Известно много кодов для контроля выполнения АЛО. Например, код "2 из 5" или "2 из 7" (2 единицы и 3 нуля и 2 единицы и 5 нулей соответственно). Но эти коды имеют большую избыточность и требуют сложной схемы АЛУ.
Определение 1. Наименьшим неотрицательным вычетом C(N) числа N по модулю P назовем число

Определение 2. Два числа N1 и N2 сравнимы по mod P, если равны их наименьшие вычеты по этому модулю, т. е. если
С (N1) = C (N2), т. е. N1 º N2 (mod P).
Верно соотношение N º C (N) (mod P).
Наибольшее распространение как в отечественных, так и в зарубежных компьютерах получил раздельный контроль АО с помощью спецустройства, выполняющего арифметические операции над контрольными разрядами. При этом контрольные знаки есть двоичное изображение наименьшего вычета по mod P. Такой контроль получил название контроля по модулю.
Контроль АЛО основан на следующих свойствах:
* если N1 ± N2 = N3
или N1N2 = N3 , то C(N1) ± C(N2) º C(N3) (mod P) и C(N1) C(N2) º C(N3) (mod P);
* если N1 = N2N3 + N4, то C(N1) º [C(N2) C(N3) + C(N4)] (mod P).
Кодирование чисел состоит в определении C(Ni), а для обнаружения ошибок вместо декодирования проверяется выполнение сравнений.
Принцип раздельного контроля по модулю может быть представлен следующей схемой (рис. 11.1)
Для эффективного использования данного метода модуль, выбираемый для контроля, должен удовлетворять следующим свойствам:
· должен быть достаточно велик, ибо от его значения зависит корректирующая способность кода;
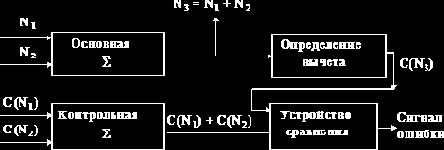 |
· должен быть таким, чтобы наименьшие неотрицательные вычеты по нему можно было легко определить;
Выбор модуля с минимальным кодовым расстоянием d = 2 используют для обнаружения одиночных и некоторых кратных ошибок. Чаще выбирают модуль P, равный B–1, где B – основание системы, что позволяет проще определять вычеты.
Все вышеизложенное позволяет утверждать, что система в коде вычетов – самокорректирующаяся.
Кодирование цветных изображений
Если вы постоянно работаете с полутоновыми или цветными изображениями, алгоритмы сжатия информации группы IV вам не подойдут. Цветные изображения содержат большое количество информации. Каждый элемент изображения, считанного с разрешением 12 точек/мм, описывается 32 битами информации: 8 бит на интенсивность красного цвета, 8 бит на зеленый, 8 бит на синий, плюс 8 дополнительных бит (RGB-описание). Даже для передачи градаций серого цвета в полутоновом изображении требуется 8 бит. Объем информации здесь значительно больше, и ее характер непрерывно меняется вдоль линии сканирования, поэтому схемы сжатия, разработанные для текстовых файлов и штриховых рисунков, здесь неприменимы. В отличие от рассмотренных выше, алгоритмы сжатия цветных образов основаны на особенностях цветовой чувствительности человеческого глаза.
Когда мы смотрим на цветную картину, мы неосознанно выделяем цветные пятна и переходы между ними. Многие мелкие детали, изменения оттенков и абсолютная яркость глазом не воспринимаются. Возьмем, например, абсолютную яркость. Очевидно, что никакая точка телевизионного изображения не может быть чернее, чем серый цвет выключенного экрана. Когда вы смотрите телевизионную программу, видимый вами иссиня-черный цвет – не более чем иллюзия, которая возникает из-за соседства с ним контрастных ярких тонов.
Алгоритмы сжатия цветных образов, преобразуя обычное описание изображения, основанное на содержании в нем красного, зеленого и синего цветов (RGB), в представление, основанное на характеристиках цветности и яркости, базируются на специфике человеческого цветовосприятия. Эти алгоритмы исключают информацию, которая не воспринимается глазом, и таким образом уменьшают сохраняемый объем данных. В течение 1990 г. схема сжатия, предложенная Объединенной группой экспертов в области фотографии (JPEG), завоевала практически всеобщее признание как стандартный метод обработки неподвижных изображений. Другой коллектив, группа экспертов в области движущихся изображений (MPED), разработал схемы сжатия для видеозаписей.
Работа с цветностью и яркостью, а не с RGB-описанием, позволяет алгоритму JPEG использовать тот факт, что на большой площади изображения изменения цвета и интенсивности незначительны. Чистое голубое небо, например, на залитом солнцем пейзаже состоит из множества элементов изображения, но содержит мало информации. При обработке каждого участка размером 8х8 элементов изображения с помощью алгоритма JPEG применяются последовательно три процедуры: дискретное косинус-преобразование (ДКП), квантование и схема кодирования, подобная алгоритмам обработки текстовых файлов. При восстановлении к каждому такому участку применяется обратная процедура. Все это требует, безусловно, значительных вычислений.
Пользователи алгоритма JPEG могут устанавливать требуемую степень сжатия, идя на компромисс между качеством изображения и размером файла. Время, которое требуется для сжатия (и восстановления) образа, больше зависит от его содержания, чем от требуемой степени сжатия. Это происходит потому, что картинка, воспринимаемая вами как очень сложная, может оказаться совсем простой для программы, выполняющей сжатие.
Кодирование данных с помощью вычетов
Поиск новых систем кодирования данных постоянно преследует цель – оптимизировать ресурсы, необходимые для обработки данных: память, процессорное время, средства надежности, точность вычислений и т.д.
Не явилась исключением и система кодирования данных с применением вычетов.
Пусть P1, P2, ..., Pn — целые числа; Pi > 1, (Pi, Pj
) = 1, i ¹ j; M =

A º xi (mod Pi), i = 1, 2, ..., n; A Ì [0,M).
Тогда кортеж (x1, x2, ..., xn) будем называть кодом числа A в системе в коде вычетов (СКВ) при заданных основаниях P1, P2, ..., Pn. Записывают это обычно так: A ~ (x1, x2, ..., xn). Компоненты xi называют разрядами числа A в СКВ. Идейными корнями данная система восходит к так называемой китайской теореме об остатках.
Теорема. Пусть числа Ms и Ms’ определены из условий
P1,P2,...,Pk º MsPs, MsMs’ º 1 (mod Ps)
и пусть
x0 = M1M1’b1 + M2M2’b2 +¼+ MkMk’bk.
Тогда совокупность значений x, удовлетворяющих системе сравнения x ºb1(mod P1), x ºb2(mod P2), ¼, x ºbk(mod Pk), определяется сравнением x º x0(mod P1, ..., Pk).
Среди особенностей СКВ исследователи отмечали следующие:
· каждый разряд числа несет информацию обо всем числе, откуда следует независимость разрядов друг от друга;
· отсутствие переносов между разрядами при выполнении арифметических операций упрощает их выполнение;
· малоразрядность компонент числа, в связи с чем арифметические операции превращаются в однотактные, иногда просто в выборку результата из таблицы.
Арифметические операции
Рассмотрим алгоритмы арифметических операций. Пусть необходимо выполнить операцию A Ä B = C, где A ~ (x1,x2,...,xn); B ~ (y1,y2,...,yn); C ~ (g1,g2,...,gn).
1. Если Ä – сложение, то
gi = | xi + yi |
Pi, т.е. gi = xi + yi - liPi,
где

2. Если Ä – вычитание, то
gi = | xi – yi |
Pi, т. е. gi = xi – yi + liPi,
где

3. Если Ä – умножение, то
gi = | xiyi |
Pi, т. е. gi = xiyi – liPi,
где

4. Если Ä – деление, то
gi =

Иногда операцию деления A/B заменяют операцией умножения A на мультипликативную инверсию от B по модулю M, т. е. выполняют умножение:
(x1, x2, ..., xn)?(y1’, y2’, ..., yn’),
где (y1’, y2’, ..., yn’) – мультипликативная инверсия от B по модулю M. Здесь yi’ =


Пример. Пусть P1 = 2, P2 = 3, P3 = 5. M = 30. Тогда числу A = 7 будет в данной СКВ соответствовать код (1, 1, 2), а числу 3 ~ (1, 0, 3).
Выполним арифметические операции над кодами чисел 3 и 7 в СКВ
(1, 1, 2) |
(1, 1, 2) |
(1, 1, 2) |
|||
+ |
– |
x |
|||
(1,  |
(1, |
(1, |
|||
( |
( |
(1, |
Восстановление позиционного значения числа А по его коду (x1, x2, ..., xn) в СКВ осуществляется из соотношения
Anec=

где Bi – ортогональные базисы; rА – ранг числа А.
Ортогональные базисы представляют собой целые числа, удовлетворяющие соотношению

и ищутся среди чисел вида

Для заданной системы оснований P1, P2, ..., Pn
ортогональные базисы фиксируются и хранятся как константы на протяжении всего времени вы-чиcлений.
Из общих соображений можно предположить, что наиболее целесообразной будет система оснований, требующая наименьшего числа малоразрядных модулей. Однако это не всегда так. Целесообразность выбранных модулей в каждом случае зависит от цели, которая ставится при проектировании компьютера на базе системы в коде вычетов.
Исследование алгоритмов выполнения различных операций в коде вычетов показывает, что основным требованием предъявляемым к модулям системы, является однозначность кодирования данных. Известно (это доказано в теории чисел), что для выполнения этого требования необходимо, чтобы (pi, pj) = 1 для всех i ¹ j, i, j = 1,…, n, т. е. необходима взаимная простота модулей системы.
Исследования показали, что полученные алгоритмы выполнения немодульных операций в рамках классической СКВ близки к предельным. В связи с этим рассмотрим некоторые обобщения классической СКВ, которые позволили бы усовершенствовать алгоритмы основных операций в плане уменьшения их вычислительной сложности, что дало бы возможность расширить класс задач, решаемых на компьютерах с базовой системой СКВ.
Итак, целое неотрицательное число A будем представлять в виде
(l1x1 + (1 – l1) (x1 – P1), …, ln xn + (1 – ln) (xn – Pn)), |
(1) |
Определение 1. Систему в коде вычетов, для которой любое целое AÎ[0, M) допускает ФНР, назовем безранговой СКВ (БСКВ).
Из (1) следует, что разряды чисел в этой системе могут быть положительными, отрицательными или равны нулю.
Примеры, демонстрирующие представления целых чисел в БСКВ, даны в табл. 5.2. При этом в предпоследнем столбце приведены коды чисел 0, 1, 2, … , 10, а в последнем - коды чисел 0, –1, –2, …, –10.
Из примера следует, что трансформирование положительных чисел в равные по абсолютной величине отрицательные получаются инвертированием знаков всех разрядов числа. Этот факт следует из (1) и формы восстановления позиционного значения числа по его коду в БСКВ. Суть инвертирования состоит в дополнении значения каждого разряда до соответствующего Pi, i = 1, 2, … , n, и замене знака каждого разряда числа на противоположный.
КОДИРОВАНИЕ ДАННЫХ В КОМПЬЮТЕРАХ
Система кодирования данных возникла в связи с необходимостью счета, сравнения вещей и обмена. На протяжении истории развития земной цивилизации на разных континентах зарождались и развивались свои системы кодирования. В последние годы они во многом унифицировались, но до сих пор идет поиск новых способов кодирования уже в связи с использованием и развитием средств вычислительной техники, в частности эффективного использования различных ресурсов: памяти, процессорного времени, удобочитаемости для пользователя и т.д. Среди многочисленных классификаций подобных систем мы будем использовать только классификацию, базирующуюся на зависимости значения числа от позиций цифры в слове, т. е. будем различать позиционные и непозиционные системы кодирования.
Коды Хемминга
Наиболее известные из самоконтролирующихся и самокорректирующихся кодов – коды Хемминга. Построены они применительно к двоичной системе счисления.
Для построения самокорректирующегося кода достаточно иметь один контрольный разряд (код с проверкой на четность). Но при этом мы не получаем никаких указаний о том, в каком именно разряде произошла ошибка, и, следовательно, не имеем возможности исправить ее. Остаются незамеченными ошибки, возникшие в четном числе разрядов.
Коды Хемминга имеют бóльшую относительную избыточность, чем коды с проверкой на четность, и предназначены либо для исправления одиночных ошибок (при d = 3), либо для исправления одиночных и обнаружения без исправления двойных ошибок (d = 4). В таком коде n-значное число имеет m информационных и k контрольных разрядов. Каждый из контрольных разрядов является знаком четности для определенной группы информационных знаков слова. При декодировании производится k групповых проверок на четность. В результате каждой проверки в соответствующий разряд регистра ошибки записывается 0, если проверка была успешной, или 1, если была обнаружена нечетность.
Группы для проверки образуются таким образом, что в регистре ошибки после окончания проверки получается K-разрядное двоичное число, показывающее номер позиции ошибочного двоичного разряда. Изменение этого разряда – исправление ошибки.
Первоначально эти коды предложены Хеммингом в таком виде, при котором контрольные знаки занимают особые позиции: позиция i-го знака имеет номер 2i–1. При этом каждый контрольный знак входит лишь в одну проверку на четность.
Рассмотрим код Хемминга, предназначенный для исправления одиночных ошибок, т. е. код с минимальным кодовым расстоянием d = 3.
Ошибка возможна и в одной из n позиций. Следовательно, число контрольных знаков, а значит, и число разрядов регистра ошибок должно удовлетворять условию
| k ³ log2(n + 1). | (1) |
Отсюда
| m £ n – log2(n + 1). | (2) |
Значения m и k для некоторых коротких кодов, вычисленные по формулам (1) и (2) даны в табл. 11.1.
Таблица 11.1. Значения m и n
n |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
m |
1 |
1 |
2 |
3 |
4 |
4 |
5 |
6 |
7 |
8 |
k |
2 |
3 |
3 |
3 |
3 |
4 |
4 |
4 |
4 |
4 |
I гр.: |
все нечетные позиции, включая и позиции контрольного разряда, т. е. позиции, в первом младшем разряде которых стоит 1. |
|
II гр.: |
все позиции, номера которых в двоичном представлении имеют 1 во втором разряде справа (например, 2, 3, 6, 7, 10) и т. д. |
|
III гр. |
: |
разряды, имеющие "1" в третьем разряде справа, и т. д. |
Пример 1. Пусть k = 5 (табл. 11.2).
Таблица 11.2. Формирование контрольных групп
Номер проверки |
Позиция контрольного знака |
Проверяемые позиции |
1 |
1 |
1, 3, 5, 7, 9, 11, 13, ... |
2 |
2 |
2, 3, 6, 7, 10, 11, ... |
3 |
4 |
4, 5, 6, 7, 12, 13, ... |
4 |
8 |
8, 9, 10, 11, 12, 13, ... |
5 |
16 |
16, 17, 18, 19, 20, 21 |
КОМПЬЮТЕРНЫЕ СЕТИ
При решении ряда задач экономически невыгодно содержать вместе с компьютером накопитель на жестких магнитных дисках большого объема, лазерный принтер, модем и т.д. Кроме того, при решении сложной задачи, разбитой на фрагменты, выполняемые на отдельных компьютерах разными исполнителями, необычайно сложным представляется процесс координации их работы. Совместная работа над одной задачей требует постоянного и оперативного обмена информацией и текущего контроля промежуточных результатов для эффективного и успешного ее завершения.
Есть задачи, решение которых непроизводительно или просто невозможно без совместного использования информации. Например, при резервировании и продаже билетов на транспорт, при формировании бюджета страны и т. д.
Справиться с указанными проблемами позволяет компьютерная сеть, представляющая собой объединение отдельно работающих компьютеров в один совместно функционирующий механизм, поддерживаемый соответствующим программным обеспечением.
Компьютерная сеть позволяет обеспечить, по крайней мере, решение следующих трех вопросов:
· экономить память на жестких магнитных дисках, так как группе пользователей придется тратить меньше памяти для хранения системных программ и пакетов общего назначения;
· упростить и сделать оперативным процесс обмена информацией между различными пользователями компьютеров;
· получать одновременный доступ к одной и той же информации за счет соответствующего сетевого программного обеспечения.
Организуют работу всех компонент сети и обеспечивают их эффективное функционирование сетевые операционные системы NOS (Network Operating System).
Одной из первых компаний, производящих компьютерные сети (оборудование и программное обеспечение), была Novell. Разработанная ею NOS Netware способна поддерживать рабочие станции, управляемые DOS, Windows, OS/2, UNIX, Windows NT, Mac System 7 и некоторыми другими.
Наиболее распространенные в последнее время в Республике Беларусь NOS являются Windows NT (фирма Microsoft).
Windows NT Server позволяет работать в сети пользователям, ПК которых функционируют под управлением MS DOS, Windows 3.11 и Windows 95. Клиенты загружают свои задания, используя программное обеспечение, находящееся на жестких дисках сети. Каждый клиент (или рабочая станция), владея сетевым адаптером с начальной программой сетевой загрузки (Remote Initial Program Load, RPL), имеет возможность осуществлять удаленную загрузку (booting remotely) в сеть.
Одна из принципиальных особенностей операционной системы Windows NT состоит в том, что сетевые возможности в нее были встроены изначально. В таких системах, как OS/2, Windows 3.11 или MS DOS возможности работы в сети были добавлены к готовым используемым програм-мным продуктам.
Одним из самых распространенных вычислительных комплексов в настоящее время являются, пожалуй, локальные вычислительные сети (ЛВС). Термин "локальная сеть" LAN (Local Area Network) требует пояснения, о каком масштабе "локальности" идет речь. Технические характеристики ЛВС имеют значительный разброс. Типовое расстояние между абонентами сети может составлять от нескольких метров до нескольких километров. Термин "область действия ЛВС" (site) переводится в зависимости от контекста как "здание", "этаж", "помещение".
Главное отличие ЛВС от глобальных или распределенных сетей – это наличие для всех абонентов высокоскоростного канала передачи данных, к которому компьютеры и другое оборудование подключаются через специальные блоки сопряжения – станции локальной сети.
Системы LAN Manager и LAN Server содержат богатые возможности для создания приложений типа Клиент/Сервер. Компьютер, работающий под управлением Windows NT, может выступать как в роли клиента, так и в роли сервера. Windows NT Workstation и Server могут работать и как клиент, и как сервер как в одноранговых сетях, так и в среде распределенных приложений.
Компьютеры со стековой архитектурой
При создании компьютера одновременно проектируют и систему команд (СК) для него. Существенное влияние на выбор операций для их включения в СК оказывают:
*
элементная база и технологический уровень производства ком-пьютеров;
* класс решаемых задач, определяющий необходимый набор операций, воплощаемых в отдельные команды;
* системы команд для компьютеров аналогичного класса;
* требования к быстродействию обработки данных, что может породить создание команд с большой длиной слова (VLIW-команды).
Анализ задач показывает, что в смесях программ доминирующую роль играют команды пересылки и процессорные команды, использующие регистры и простые режимы адресации.
На сегодняшний день наибольшее распространение получили следующие структуры команд: одноадресные (1A), двухадресные (2A), трехадресные (3A), безадресные (БА), команды с большой длиной слова (VLIW – БДС) (рис. 2.1):
| 1А ~ | КОП | А1 | |||||||||||||
| 2А ~ | КОП | А1 | А2 | ||||||||||||
| 3А ~ | КОП | А1 | А2 | А3 | |||||||||||
| БА ~ | КОП | ||||||||||||||
| БДС ~ | КОП | Адреса | Теги | Дескрипторы |
Рис. 2.1. Структуры команд
Причем операнд может указываться как адресом, так и непосредственно в структуре команды.
В случае БА-команд операнды выбираются и результаты помещаются в стек (магазин, гнездо). Типичными первыми представителями БА-компьютеров являются KDF-9 и МВК "Эльбрус". Их характерной особенностью является наличие стековой памяти.
Стек – это область оперативной памяти, которая используется для временного хранения данных и операций. Доступ к элементам стека осуществляется по принципу FILO (first in, last out) – первым вошел, последним вышел. Кроме того, доступ к элементам стека осуществляется только через его вершину, т. е. пользователю "виден" лишь тот элемент, который помещен в стек последним.
Рассмотрим функционирование процессора со стековой организацией памяти.
При выполнении различных вычислительных процедур процессор использует либо новые операнды, до сих пор не выбиравшиеся из памяти компьютера, либо операнды, употреблявшиеся в предыдущих операциях. В процессорах с классической структурой обращение к любому операнду (1A-ЭВМ) требует цикла памяти.
Рассмотрим пример.
Концепции вычислительных систем с комбинированной структурой
Одна из первых концепций ВС с комбинированной структурой – это ортогональная машина Шумана, состоящая из горизонтальных и вертикальных АУ, совместно использующих ортогональную память.
 |
Ортогональная память – это ЗУ, позволяющее использовать горизонтальному АУ доступ к данным, расположенным на горизонтальном срезе памяти, а вертикальному АУ – доступ к данным по вертикально расположенным разрядным срезам. На базе концепции ортогональной машины создана реальная система – OMEN 60 с ЭВМ PDP-11 в качестве горизонтального АУ, что позволило применить развитое ПО этой системы, не разрабатывая нового (рис. 9.7). В качестве вертикального АУ используется 64 идентичных процессорных элемента. Ортогональная память построена таким образом, что для горизонтального АУ она представляется обычной памятью с 16 разрядными словами (2 байта), а для вертикального АУ – памятью длиной в 64 разряда. Программное обеспечение систем семейства OMEN 60 содержит расширенные версии языков ФОРТРАН и БЕЙСИК, реализованных на PDP-11, а также OC PDP-11, дополненную расширенной версией языка APL.
Рис. 9.7. Структурная схема семейства OMEN 60
Значительный интерес представляет концепция системы MAP (Multi Associative Processor), которая сочетает в себе черты ансамблей процессоров матричных и ассоциативных систем, т. е. черты основных представителей класса ОКМД и МКМД (рис. 9.8). На рисунке:
ПЭ – процессорный элемент;
ОП – модуль оперативной памяти;
УУ – устройство управления;
S – коммутатор сектора процессорных элементов.
 |
Рис. 9.8. Структурная схема системы MAP
Система содержит 1024 ПЭ и восемь УУ. Системное ПО реализуется не на одном процессоре, а в самой системе. Допускается программное управление связями между ПЭ вместо обычных фиксированных связей.
Такая организация позволяет использовать ПЭ как распределяемые ресурсы, что в сочетании с 8 УУ позволяет одновременно решать несколько программ, причем одни программы могут обрабатываться в параллельном режиме, а другие – в последовательном. Одновременная работа в параллельном и последовательном режимах в отличие от матричных и ассоциативных систем позволяет отказаться от универсальной ВС в качестве сопрягаемого ведущего процессора.
Недостатки системы МАР:
· невозможен, как в ИЛЛИАК-4, быстрый ввод-вывод информации в собственное ЗУ для ПЭ. Загрузка памяти ПЭ осуществляется через ОП и УУ, за которым в данный момент закреплен рассматриваемый процессорный элемент;
· скорость обмена информацией между соседними ПЭ ограничена.
По оценкам авторов и пользователей системы МАР, стоимость выполнения одной команды в ней в 2 раза меньше, чем в обычном компьютере с аналогичными характеристиками.
Концепция виртуальной памяти
Каждая часть среды компьютера имеет собственное обозначение: ячейка – адрес, периферийное устройство – номер и т. д. В простейших компьютерах собственные обозначения указываются непосредственно в программе. В более сложных компьютерах программа отделена от среды "аппаратом преобразования собственных обозначений". Рассмотрим один элемент среды – память. Аппарат преобразования адреса (АПА) не находится под прямым управлением программы и связь с ним осуществляется только через процедуры, работающие в управляющем режиме.
Если программисту безразлично существование АПА, то он работает с набором ячеек и периферийных устройств, образующих "виртуальную (математическую, мнимую) среду". Почти всегда виртуальная среда есть переупорядоченное подмножество реальной среды. Каждому виртуальному элементу соответствует реальный элемент, но обратное не всегда верно.
Рассмотрим один из элементов виртуальной среды – виртуальную память (ВП).
Контроль данных
Проблема обеспечения достоверности функционирования ВС имеет много общего с проблемой достоверности передачи дискретной информации по каналам связи (КС). В обоих случаях она включает две группы меро-
приятий:
· совершенствование элементов аппаратуры в целях снижения вероятности появления ошибок;
· разработку эффективных методов контроля, т. е. методов обнаружения ошибок и их исправления.
Корректирующие коды
ЭВМ воспринимают вводимую в них информацию в виде определенных символов. Обычно применяются двоичные символы: 0 и 1. Это обусловливается сравнительной простотой электронных элементов с двумя устойчивыми состояниями: ключевым режимом ламп и полупроводников, переключением состояний магнитных сердечников с прямоугольной петлей гистерезиса и т. д.
Кодирование информации состоит в представлении чисел и слов соответствующими им комбинациями символов.
Совокупность всех комбинаций из определенного количества символов, которые избраны для представления информации, называют кодом. Каждую такую комбинацию символов будем называть кодовой комбинацией. Общее количество кодовых комбинаций может быть меньше или равно числу всевозможных комбинаций из заданного количества символов.
Приведем некоторые определения из теории кодирования.
Равномерный код – код, все комбинации которого содержат одинаковое количество символов.
Неравномерный код – код с различным количеством символов для различных комбинаций (например, азбука Морзе).
В компьютерах обычно используют равномерные коды.
Кодовое расстояние – число позиций, в которых коды не совпадают. Так, если A~ a1, a2, ..., an, B ~ b1, b2, ..., bn, то кодовое расстояние (W) вычисляется по формуле

Пример: A ~ 101110, B ~ 000110, то W(AÄB) = 2.
Минимальное кодовое расстояние
(d) – это минимальное расстояние между двумя любыми кодовыми комбинациями в заданном коде.
Для всех корректирующих кодов d > 1. Для обнаружения ошибки кратности t требуется, чтобы d = t + 1, а для ее исправления — d = 2t + 1. C увеличением значения d растет корректирующая способность кода, которая количественно может быть выражена как вероятность обнаружения или исправления ошибок различных типов.
В зависимости от назначения и возможностей помехозащищенных кодов различают коды самокорректирующиеся (позволяющие автоматически исправлять ошибки) и самоконтролирующиеся (позволяющие автоматически обнаруживать наиболее вероятные ошибки).
Магистральные системы
В большинстве ранних компьютеров и современных малых машин команды выполняются последовательно (рис. 9.5), т. е. происходит чтение команды, затем процессор переходит к фазе исполнения операции. Последовательный характер работы процессора способствует простоте его логической организации. Достаточно для всей памяти системы иметь один узел управления циклом памяти. Так как процессор во время поиска команды не занят, он может быть использован для индексных операций над адресами. Такое совмещение работы процессора позволяет эффективно использовать обору-дование.
 |
Рис. 9.5. Последовательное исполнение команды
Стремление повысить быстродействие ВС привело к появлению процессоров с совмещением операций, несмотря на удорожание оборудования, т.е. к распараллеливанию процессов.
Идея об использовании принципа совмещения операций в целях повышения скорости ЭВМ, равно как и идея об объединении машин и о создании многопроцессорных систем с общей основной памятью, была высказана академиком С.А. Лебедевым на сессии АН СССР в 1957 г. Несмотря на то что эти идеи были высказаны более 40 лет назад, они актуальны и сегодня.
Одна из возможностей совмещения операций состоит в модульной организации памяти, при которой каждый модуль имеет собственный адресный и числовой регистры, т. е. модули способны работать одновременно. Количество модулей обычно равно небольшой степени двойки. В начальных моделях IBM данные и команды извлекались из ячеек памяти с последовательными адресами. Поэтому оказалось возможным чередование адресов, при котором последовательно возрастающие адреса соответствуют разным модулям памяти. Например, в IBM 7030 имеются две группы модулей памяти с чередующимися в каждой группе адресами. Одна группа может использоваться главным образом для хранения команд, а другая – для хранения операндов. Используя указанные свойства в сочетании с соответствующим программированием задачи, можно достичь более высокой скорости поступления данных из памяти, чем та, которая обеспечивается физическим циклом памяти.
Более сложные способы реализации совмещения обращений к памяти состоят в построении многовходовой памяти, что допускает одновременное обращение к ней со стороны многих устройств, разрешая при этом конфликт одновременного обращения.
Еще большая степень совмещения показана на рис. 9.6.
Такая организация функционирования направлена на возможно более полную загрузку всех компонент системы. Однако, с одной стороны, не все этапы выполнения команды идентичны по времени, а с другой – не все команды выполняются до конца (ветвления, циклы и т. д.), в связи с чем не все устройства ВС работают на полную мощность.
Дальнейшим развитием идеи совмещения операций явилось создание магистральной (конвейерной) организации функционирования, которую мы рассмотрим ниже.
 |
На сегодняшний день магистральные системы получили большое распространение. Так, уже системы STAR 100, CDC 6600, CDC 7600, IBM 360/91, IBM 360/195 имели отдельные блоки для магистральной обработки. Принцип магистральной обработки основан на разбиении вычислительного процесса на несколько подпроцессов, каждый из которых выполняется на отдельном устройстве, как это имеет место при выполнении сложных операций последовательно по подоперациям на промышленном конвейере, в связи с чем этот метод иногда называют конвейерным.
В случае четырехшаговой арифметико-магистральной обработки каждая команда выполняется последовательно на четырех различных устройствах, а последовательность четырех следующих друг за другом команд заполняет арифметическую магистраль так, что одновременно на последнем, четвертом, устройстве выполняется завершающий четвертый этап первой команды, а на первом – начальный, первый этап четвертой команды. После завершения выполнения первая команда выводится из магистрали, вторая, третья и четвертая поступают на очередное устройство, а пятая входит на первое устройство магистрали.
В системе STAR 100, например, используется четырехэтапная магистраль для сложения, а шестиэтапная – для умножения.
Более высокий уровень магистральной обработки – командно-магистральная обработка. Здесь каждая команда из потока команд выполняется на соответствующих ей функциональных обрабатывающих устройствах, которые могут работать одновременно. Для эффективной работы подобных систем необходимо, чтобы команды были по возможности независимы друг от друга, а распределение команд в потоке по возможности совпадало с набором функциональных устройств. Типичный представитель такой системы – CDC 6600, который содержит 10 спецустройств обработки (умножение с плавающей точкой, сложение целых чисел и др.).
Суть макромагистральной обработки состоит в следующем. Пусть множество исходных данных может быть обработано последовательным решением двух и более задач.
Обработка может быть осуществлена с помощью двух различных процессоров, каждый из которых специализируется на решении своей задачи. Данные из буфера поступают в первый процессор, обрабатывается (решается первая задача), затем результаты поступают во второй буфер, откуда передаются на второй процессор для дальнейшей обработки (решается вторая задача). В это время первый буфер заполняется следующим набором данных и т.д. В результате – оба процессора работают одновременно.
Все три этапа обработки характеризуются тем, что имеется магистраль (конвейер) обработки с независимыми компонентами, которые при заполнении магистрали работают одновременно и, по возможности, без перерывов.
Считается, что магистральный принцип обработки повышает эффективность операций сложения на 47 %, а операций умножения – на 230 %.
Магистральные структуры можно различать и по типу команд: обычные и векторные. Функциональные возможности магистральной обработки наиболее полно проявляются при векторной обработке данных, при которой выполняются однотипные операции над упорядоченной группой данных.
Первым шагом на пути создания магистральных систем явилось перекрытие операций. В большой мере это перекрытие операций I/O, обработки в процессоре и обращения к ОП (UNIVAC, IBM 7094).
Из отечественных ЭВМ следует отметить БЭСМ-6. В результате эволюции структур компьютеров проектировщики пришли от реализации отдельных блоков для магистральной обработки (IBM 360/91, IBM 360/195) до полной реализации принципа магистральной обработки (STAR 100, CRAY 2, 3, 4 и т. д.).
Сегодня отработан стандарт конвейера, включающий пять ступеней: чтение команды, декодирование, чтение операндов, исполнение операции, запись результата.
В компьютерах Pentium Pro каждая из указанных ступеней может еще разбиваться на подступени, так что общая "длина" конвейера включает 12 подступеней. Естественно, что в зависимости от типа выполняемой операции идет настройка на конкретную длину конвейера.
Для обработки 12 подступеней конвейера в Pentium Pro включены три устройства. Устройство выборки и декодирования поддерживает шесть подступеней: выборку команд, распознавание команд в потоке байтов, декодирование, постановку микрокоманд в очередь, запись микрокоманд в таблицу регистров, формирование статуса микрокоманд. Устройство диспетчирования и выполнения реализует подступени: выбор готовых для исполнения микрокоманд, выполнение микрокоманд, изменение статуса микрокоманд, сравнение реального и предсказанного результатов выполнения и осуществление соответствующей реакции. Устройство удаления выполненных команд осуществляет удаление выполненных команд и микрокоманд из пула и внесение соответствующих изменений в ряд таблиц.
Матричные компьютеры
Типичным представителем матричных компьютеров является ЭВМ ИЛЛИАК-1. Она появилась в то время, когда эпоха "mainframe houses" находилась в эволюционном развитии. Проект ее зародился в недрах системы "Соломон", когда руководитель ее проекта Д. Слотник перешел в Иллинойский университет.
Система "Соломон" имела 1024 элементарных процессора, которые выполняли одну и ту же команду одновременно, но с различными операндами. Каждый процессор имел собственную память для операндов. Процессоры работали синхронно.
ИЛЛИАК-4 – разработка Иллинойского университета (США) совместно с фирмой Burroughs. ЭВМ специализированная.
Цель первоначального проекта – создание матричной системы с производительностью порядка 1 млрд оп/с. Он должен был содержать одно управляющее звено, в качестве которого использовалась B-6500 с быстродействием около 500–600 тыс. оп/с.
Достижение такого быстродействия потребовало создания параллельной архитектуры и высокого быстродействия электронных компонент. Первоначальный проект содержал четыре независимых блока по 64 обрабатывающих элемента каждый. Это типичный представитель SIMD-машин. Спроектированный арифметический процессор был рассчитан на обработку 64-битных слов с плавающей точкой. Однако технические трудности не позволили воплотить в жизнь предложенный проект. Пришлось остановиться на одноблочном варианте. Разработки велись на новом алголоподобном языке TRANQUIL, одновременно разрабатывалось ПО еще и на ассемблере GLYPNIR. Язык TRANQUIL имел возможности для задания параллельных (векторных) конструкций.
Реализованный вариант содержал 64 процессора и ЭВМ 7500 с общей производительностью до 200 млн оп/с. Он рассчитан на решение задач, хорошо поддающихся распараллеливанию: от проблем линейного программирования до задач метеорологии. Простейшие из них: решение систем линейных алгебраических уравнений (СЛАУ), обращение матриц, умножение матриц и т. д. Оценки авторов проекта ИЛЛИАК-4 показывают, что для задач, поддающихся распараллеливанию, время решения уменьшается примерно в 220 раз по сравнению со временем их выполнения на однопроцессорных ВС с последовательным выполнением команд.
В ИЛЛИАК- 4 отказались от строгой синхронизации работы элементарных процессоров, допуская произвольное выполнение (по времени) общей команды. Каждый процессор здесь превращен, по сути, в целую ЭВМ, допускающую модификацию выполнения команд в зависимости от операнда, тем самым приблизив процессоры почти к независимой работе. Оперативная память в 2048 слов длиной 64 бита. Цикл ЗУ примерно 350 нс. Хотя каждый процессор получает для обработки одну и ту же последовательность команд, характер работы каждого зависит от типа локальных данных.
В ИЛЛИАК-4 заложена возможность выполнения в разных процессорах различных программ, правда, за счет уменьшения скорости обработки. Реализуется это следующим образом: в 64-разрядный регистр маски в центральном УУ (каждый разряд соотнесен определенному процессору) заносится значение, блокирующее (или разрешающее) работу соответствующего процессора, что позволяет блокировать определенную группу процессоров. Это в принципе и дает возможность выполнять разные последовательности команд на различных процессорах.
При разработке ИЛЛИАК-4 был решен ряд важнейших проблем. В частности, проблема информационного обмена между отдельными индивидуальными ЗУ каждого процессора. Она была решена посредством обеспечения возможности обращаться к ЗУ соседних процессоров.
Вторая проблема – организация работы всех процессоров в целом, т. е. задача координации функционирования системы. Функции координатора программ, их трансляции и распараллеливания возложены на универсальную ЭВМ В-7500, которая имеет богатые возможности по связи с внешними устройствами.
Третья проблема – обеспечение живучести и надежности. ИЛЛИАК-4 включает до 7 млн электронных компонент. С этой целью разработана система контроля работы устройств и передачи данных между узлами и блоками ЗУ. Имеется мощная система технической диагностики.
ИЛЛИАК-4 включает ПЗУ большого объема – лазерное ПЗУ, представляющее собой металлическую пленку, которая покрывает барабан с выжженными лазерным путем микроотверстиями.Такое ЗУ используется для длительного и надежного хранения информации.
Система ИЛЛИАК-4 оказала также содействие развитию компьютерной науки. Она, в частности,
·
продемонстрировала, что SIMD-архитектура может быть эффективно использована для некоторых важных применений;
· показала, что система такой сложности может быть использована производительно и надежно.
Главный недостаток, препятствующий широкому использованию ИЛЛИАК-4, постоянная эволюция применений и высокая стоимость.
Метод круговорота (карусель)
Простой круговорот (round robin, RR) не использует никакой информации о приоритетах. Порядок обслуживания процессов следующий: первый пришедший процесс получает квант времени to
и встает в очередь на обслуживание, если только он себя не заблокирует. Поэтому при наличии N процессов в системе для обслуживания будем считать, что скорость работы процессора равна V/N, где V– истинное быстродействие процессора. Если to ® ¥, то стратегия SRR (simple round robin) сводится к стратегии FIFO (first in first out). С уменьшением to улучшается обслуживание коротких процессов. Но to не должно быть слишком мало: если оно становится сравнимым по порядку со временем переключения с одного процесса на другой, то задержка в выполнении процессов становится заметной. Метод RR часто применяется в системах разделения времени (СРВ) с большим числом пользователей. Системы СРВ должны гарантировать каждому пользователю приемлемое время ответа. Время ответа в случае N пользователей » t0N.
Одна из модификаций метода – raund robin cicle (RRC). В нем в качестве to для гарантии
выбирается максимально возможное время ожидания. Суть метода: формируется множество Pг – множество готовых для выполнения процессов. Пусть мощность этого множества No. Выбирается время цикла Тц для очереди Pг, равное максимально достижимому времени ответа. Тогда to = Тц/No, to вычисляется для каждого прохождения цикла Pг. Процессы, вновь появляющиеся для обслуживания в Pг, не включаются в очередь до завершения цикла. Если to оказывается слишком маленьким (сравнимым со временем переключения процессов), то выбирается некоторая нижняя оценка для величины to, что позволяет сократить потери на переключение процессов.
Существуют и другие разновидности метода RR, например "эгоистический" RR. Суть его: войдя в систему, процесс ждет, пока его приоритет не достигнет величины приоритетов работающих процессов, затем он выполняется в круговороте с другими процессами.
Можно выделить ведущую и фоновую очередь готовых процессов в зависимости от вероятности затребования определенного количества квантов времени ЦП для их завершения.
Методы адресации и типы команд
В машинах с регистрами общего назначения метод (или режим) адресации объектов, с которыми манипулирует команда, может задавать константу, регистр или ячейку памяти.
В табл. 2.2 представлены основные методы адресации операндов, которые реализованы в компьютерах, рассмотренных в настоящей книге.
Таблица 2.2. Методы адресации
| Метод адресации | Пример команды | Смысл команды | Использование команды | ||||
| Регистровая | Add R4, R3 | R4 = R4+R3 | Для записи требуемого значения в регистр | ||||
| Непосредственная или литерная | Add R4, #3 | R4 = R4+3 | Для задания констант | ||||
| Базовая со смещением | Add R4, 100(R1) | R4= R4+M(100+R1) | Для обращения к локальным переменным | ||||
| Косвенная регистровая | Add R4, (R1) | R4 = R4+M(R1) | Для обращения по указателю к вычисленному адресу | ||||
| Индексная | Add R3, (R1+R2) | R3 = R3+M(R1+R2) | Полезна при работе с массивами: R1 – база, R3 – индекс | ||||
| Прямая или абсолютная | Add R1, (1000) | R1=R1+M(1000) | Полезна для обращения к статическим данным | ||||
| Косвенная | Add R1, @(R3) | R1 = R1+M(M(R3)) | Если R3 – адрес указателя р, то выбирается значение по этому указателю | ||||
| Автоинкрементная | Add R1, (R2)+ | R1 = R1+M(R2)
R2 = R2+d | Полезна для прохода в цикле по массиву с шагом: R2 – начало массива. В каждом цикле R2 получает приращение d | ||||
| Автодекрементная | Add R1, (R2)– | R2 = R2–d
R1 = R1+M(R2) | Аналогична предыдущей. Обе могут использоваться для реализации стека | ||||
| Базовая индексная со смещением и масштабированием | Add
R1, 100(R2)(R3) | R1=R1+M(100)+R2+R3*d | Для индексации массивов |
Адресация непосредственных данных и литерных констант обычно рассматривается как один из методов адресации памяти (хотя значения данных, к которым в этом случае производятся обращения, являются частью самой команды и обрабатываются в общем потоке команд).
В табл. 2.2 на примере команды сложения (Add) приведены наиболее употребительные названия методов адресации, хотя при описании архитектуры в документации производители компьютеров и ПО используют разные названия для этих методов.
В табл. 2.2. знак "=" используется для обозначения оператора присваивания, а буква M обозначает память (Memory). Таким образом M(R1) обозначает содержимое ячейки памяти, адрес которой определяется содержимым регистра R1.
Использование сложных методов адресации позволяет существенно сократить количество команд в программе, но при этом значительно увеличивается сложность аппаратуры.
Команды традиционного машинного уровня можно разделить на несколько типов, которые показаны в табл. 2.3.
Таблица 2.3. Основные типы команд
Тип операции |
Примеры |
Арифметические и логические |
Целочисленные арифметические и логические операции: сложение, вычитание, логическое сложение, логическое умножение и т. д. |
Пересылки данных |
Операции загрузки/записи |
Управление потоком команд |
Безусловные и условные переходы, вызовы процедур и возвраты |
Системные операции |
Системные вызовы, команды управления виртуальной памятью и т. д. |
Операции с плавающей точкой |
Операции сложения, вычитания, умножения и деления над вещественными числами |
Десятичные операции |
Десятичное сложение, умножение, преобразование форматов и т. д. |
Операции над строками |
Пересылки, сравнения и поиск строк |
Обычно тип операнда (целый, вещественный, символ) определяет и его размер. Как правило, целые числа представляются в дополнительном коде. Для задания символов компания IBM использует код EBCDIC, другие компании применяют код ASCII. Для представления вещественных чисел с одинарной и двойной точностью придерживаются стандарта IEEE 754.
В ряде процессоров применяют двоично кодированные десятичные числа, которые представляют в упакованном и неупакованном форматах. Упакованный формат предполагает, что для кодирования цифр 0 – 9 используют 4 разряда и две десятичные цифры упаковываются в каждый байт.В неупакованном формате байт содержит одну десятичную цифру, которая обычно изображается в символьном коде ASCII.
Методы обнаружения и исправления ошибок в ЭВМ
Автоматический контроль функционирования ЭВМ предполагает получение каким-либо способом информации об ошибках. Причем для исправления ошибок требуется более полная информация.
Существуют два вида контроля, отличающиеся способами получения такой информации: программный и схемный (аппаратурный) контроль.
Программный контроль состоит в том, что при составлении программы решения задачи в нее включаются дополнительные операции, имеющие математическую или логическую связь с алгоритмом задачи. Сравнение результатов введенных операций с результатом решения всей задачи в целом или отдельных этапов решения позволяет установить с определенной вероятностью наличие или отсутствие ошибки. На основании сравнения появляется возможность исправить обнаруженную ошибку. Такой дополнительной операцией может быть двойной (тройной) счет программы или ее частей, позволяющий осуществить исправление ошибки без ее обнаружения. Возможность исправления обусловлена тем, что ошибка носит случайный характер и в дальнейшем не повторяется.
Достоинства программных методов:
·
простота реализации;
· отсутствие дополнительного оборудования;
· возможность применения в любом компьютере.
Недостатки:
· значительное снижение производительности компьютера;
· проблематичность использования в компьютерах, работающих в режиме управления.
Схемный контроль связан с введением в состав ЭВМ дополнительной аппаратуры, предназначенной для выявления ошибок в контролируемом устройстве. Принцип их действия связан обычно со специальным кодированием операндов и команд программы. Код должен содержать дополнительные разряды, несущие требуемую для контроля избыточную информацию. Иногда избыточная информация получается дублированием основной аппаратуры без применения спецкодов.
Достоинства схемных методов: небольшое относительное время контроля, ибо операции контроля удается почти полностью совместить с выполнением основных операций.
Недостатки: необходимость увеличения объема аппаратуры.
Схемно-программный метод заслуживает особого внимания. Сущность его состоит в том, что задача обнаружения ошибок возлагается на контрольные схемы, встроенные во все устройства и тракты машины. Исправление же обнаруженных ошибок осуществляется специальной исправляющей программой, которая берет на себя управление по сигналу ошибки.
Достоинства комбинированного метода:
· производительность компьютера снижается незначительно, ибо исправляющая программа включается редко;
· объем дополнительного оборудования гораздо меньше того, который требуется при схемном методе.
МЕТОДЫ ПЛАНИРОВАНИЯ
Ветви решений, полученные после формирования параллельной программы, или исходный набор задач для обработки на компьютере в случае многопроцессорных систем или компьютерных сетей должны быть распределены по процессорам (или компьютерам) для выполнения.
Ниже мы рассмотрим некоторые подходы и методы назначения задач на процессоры.
Методы защиты информации
Программные механизмы защиты строятся, как правило, на принципе проверки определенных параметров машины на предмет совпадения некоторых данных, хранящихся в памяти компьютера, жестком диске, ключевой дискете.
При разработке программ защиты, которые в дальнейшем предполагается устанавливать на любой компьютер, предлагают обычно вариант использования ключевой дискеты. В защитном механизме в этом случае должна осуществляться проверка на присутствие на ключевой дискете определенной информации. Ввиду того что в настоящее время существует большое количество программ по полному копированию дискет, необходимо предусмотреть механизм нестандартного их форматирования.
Микропроцессоры
Наряду с развитием и совершенствованием технологии производства элементной базы совершенствуется и архитектура компьютеров. Ниже рассмотрены архитектурные решения, предлагаемые ведущими мировыми фирмами по проектированию и производству компьютеров. Среди них фирмы IBM, Intel, Microsystems, Hewlett Packard, Motorola, DEC, Apple и др.
Многобайтовые команды
устройств
Одним из важных преимуществ RISC-архитектуры является высокая скорость арифметических вычислений. RISC-процессоры первыми достигли планки наиболее распространенного стандарта IEEE 754, устанавливающего 32-разрядный формат для представления чисел с фиксированной точкой и 64-разрядный формат "полной точности" для чисел с плавающей точкой. Высокая скорость выполнения арифметических операций в сочетании с высокой точностью вычислений обеспечивает RISC-процессорам безусловное лидерство по быстродействию в сравнении с CISC-процессорами.
Другой особенностью RISC-процессоров является комплекс средств, обеспечивающих безостановочную работу арифметических устройств: механизм динамического прогнозирования ветвлений, большое количество оперативных регистров, многоуровневая встроенная кэш-память.
Организация регистровой структуры – основное достоинство и основная проблема RISC. Практически любая реализация RISC-архитектуры использует трехместные операции обработки, в которых результат и два операнда имеют самостоятельную адресацию – R1 : = R2, R3. Это позволяет без существенных затрат времени выбрать операнды из адресуемых оперативных регистров и записать в регистр результат операции. Кроме того, трехместные операции дают компилятору большую гибкость по сравнению с типовыми двухместными операциями формата "регистр – память" архитектуры CISC. В сочетании с быстродействующей арифметикой RISC-операции типа "регистр – регистр" становятся очень мощным средством повышения производительности процессора.
Вместе с тем опора на регистры является ахиллесовой пятой RISC-архитектуры. Проблема в том, что в процессе выполнения задачи RISC-система неоднократно вынуждена обновлять содержимое регистров процессора, причем за минимальное время, чтобы не вызывать длительных простоев арифметического устройства. Для CISC-систем подобной проблемы не существует, поскольку модификация регистров может происходить на фоне обработки команд формата "память – память".
Существуют два подхода к решению проблемы модификации регистров в RISC-архитектуре: аппаратный, предложенный в проектах RISC-1 и RISC-2, и программный, разработанный специалистами IВМ и Стэндфордского университета. Принципиальная разница между ними заключается в том, что аппаратное решение основано на стремлении уменьшить время вызова процедур за счет установки дополнительного оборудования процессора, тогда как программное решение базируется на возможностях компилятора и является более экономичным с точки зрения аппаратуры процессора.
Многомашинная система ОИЯИ
Система объединенного института ядерных исследований (ОИЯИ) имеет развитую иерархическую структуру. Один из вариантов ее был устроен следующим образом. Верхний уровень был образован ЭВМ БЭСМ-6 и СДС6200 суммарной производительностью около 2 млн оп/с. Использовался для сложных расчетов и обработки огромных массивов экспериментальной информации, получаемой на ускорителях.
Средний уровень предназначался для автономного решения задач каждой лаборатории. Он образован из машин типа ЕС 1040, БЭСМ-4, СДС 1604, Минск-32(22) и др. Некоторые из этих машин имели кабельную связь с БЭСМ-6.
Нижний уровень служит для накопления и предварительной обработки информации и используется в системах контроля и управления работой физических установок. Он состоит из малых советских ЭВМ: М-6000, М-400, Электроника-100; ЭВМ стран СЭВ: ТРА, ЕС1010 и компьютеров некоторых западных фирм: PDP-8, CDC 160А и др.
Обмен между ЭВМ разных уровней осуществлялся как за счет физического переноса носителей информации, так и (для БЭСМ-6) по быстродействующим кабельным линиям связи с пропускной способностью до 500 Кб/с.
Наиболее простая схема МК ОИЯИ дана на рис. 9.2.
Многомашинные комплексы на базе ЕС ЭВМ
Структура ЕС ЭВМ позволяет осуществлять комплексирование машин на уровне процессора, каналов, внешней памяти (внешних устройств) и оперативной памяти. При комплексировании на первых трех уровнях, что характерно для малых и средних машин ряда 1 (1010, 1012, 1020), создаются многомашинные комплексы. При комплексировании на уровне оперативной памяти, с сохранением возможности комплексирования на других уровнях (ЕС 1050 и ряд 11 – 1015, 25, 35, 45, 55, 60, 65), создаются многопроцессорные системы.
Отметим, что программная организация работы процессоров с общим полем оперативной памяти принципиально сложнее, нежели взаимодействие процессоров на уровне внешнего оборудования, хотя является наиболее гибкой и быстрой.
Обмен информацией между процессорами или между процессором и ВнП (управляющей или синхронизирующей информацией) использует средства прямого управления, к которым относятся команды ПРЯМАЯ ЗАПИСЬ и ПРЯМОЕ ЧТЕНИЕ. Связь между процессорами или процессором и ВнП осуществляется с помощью указанных команд и механизма внешних
прерываний.
При комплексировании на уровне каналов используется адаптер, который имеет два выхода на стандартный интерфейс I/О и подключается к селекторным (или мультиплексным) каналам двух модулей ЕС ЭВМ.
При комплексировании на уровне внешней памяти на НМД и НМЛ используются двухканальные переключатели, которые позволяют подсоединять УУ, НМЛ и НМД к двум каналам различных ЭВМ, в результате чего образуется общее поле памяти на управляемых ими накопителях. Возможно взаимодействие процессоров по телефонным и телеграфным линиям связи.
Наибольшую возможность комплексирования имеют компьютеры ЕС 1030: из двух ЭВМ, соединенных линиями прямого управления; из нескольких ЭВМ, имеющих доступ к общему полю внешней памяти; из нескольких ЭВМ, соединенных адаптером "канал–канал".
В случае прямого управления обмен информацией выполняется по командам прямого управления. По ним из одного процессора передается один байт информации, прерывающий работу другого процессора.
Такая система эффективна, если объем и скорость передачи информации небольшие.
При организации многомашинного комплекса, связанного общим полем внешней памяти, передача информации одним процессором и прием ее другим происходят неодновременно, в результате чего производительность взаимодействующих систем не снижается. Эта связь эффективнее объединения с помощью линий прямого управления.
В случае связи через адаптер "канал–канал" прямая связь между каналами ЭВМ осуществляется через стандартный интерфейс (interface – общая граница). Интерфейсом могут быть аппаратурный блок, связывающий два устройства, а также часть области памяти или регистры, доступные двум или более программам. Скорость обмена информацией определяется пропускной способностью каналов.
Результат комплексирования двух ЭВМ 1030 – это МК 1010. ЭВМ в нем соединены между собой по шинам прямого управления через блок состояния вычислительного комплекса, раздельные внешние устройства и через адаптер "канал–канал".
 |
Рис. 9.3. Структурная схема адаптера "канал–канал"
Режим 1. Оба компьютера принимают информацию с внешних устройств и обрабатывают ее, а выдачу информации осуществляет только основная ЭВМ, а вторая резервирует ее. Если первая машина не может выполнять планируемые функции, ее работу выполняет вторая.
Режим 2. Первый компьютер выполняет свои основные функции, а второй выходит на профилактику. Это режим работы без резервирования. В случае надобности (например, если компьютер вышел из строя) вторая машина может быть выведена из профилактики и переведена в рабочий режим.
Режим 3. Оба компьютера работают независимо.
Текущее состояние каждой ЭВМ фиксируется и как байт состояния (флажок) хранится в блоке состояния МК. Задание режима работы МК и перевод в требуемый режим осуществляются оператором с пульта ЭВМ.
Изменить байт состояния компьютера в блоке состояния МК можно и программным путем с помощью команд прямого управления. Блок состояния, в свою очередь, связан с ЭВМ по двум стандартным интерфейсам прямого управления. Адаптеры "канал–канал" предназначены как для передачи массивов данных между каналами I/О ЭВМ данного МК, так и для связи с другими
системами.
Адаптер работает в автономном режиме и передает информацию со скоростью более медленного канала из двух соединенных. Адаптер, по сути, играет роль УУ для канала: реагирует на запросы канала, принимает и расшифровывает команды каналов, но использует все полученные сведения не для управления устройствами I/О, а для обеспечения связи между каналами и синхронизации их работы.
Управление работой двухмашинного комплекса МК 1010 осуществляет операционная система ОС К1, включающая средства комплексирования и являющаяся расширением ОС ЕС с мультипрограммированием в режиме фиксированного числа задач.
Ряд особенностей имеет ЕС 1035: расширенную СК, виртуальную память, коррекцию одиночных ошибок при чтении информации из ОП и обнаружение двойных ошибок, совместимость с ЭВМ "Минск-32" (разработаны конверторы языков ФОРТРАН и КОБОЛ "Минск-32", эмулятор программ "Минск-32" на ЕС 1035 и средства переноса данных).
Известны многомашинные и многопроцессорные системы на базе ЕС 1050. В частности, в двухпроцессорной системе на базе ЭВМ ЕС 1050 связь осуществляется на уровне процессоров, каналов, внешней памяти (внешних устройств) и оперативной памяти, при помощи средств комплексирования: соответственно средств прямого управления, адаптеров "канал–канал", двухканальных переключателей устройств управления внешними устройствами, а также при помощи пульта реконфигурации.
Для создания общего поля оперативной памяти система должна иметь двухвходовые устройства оперативной памяти. В двухпроцессорной системе с общим полем оперативной памяти задание режима работы системы, физического распределения ресурсов системы между процессорами и исключения неисправных устройств осуществляется с помощью пульта реконфигурации системы.
Прямоадресуемая память одного из двух процессоров во избежание наложения ее на прямоадресуемую память другого процессора смещена путем префиксации адреса. Основные сведения о комплексировании компьютеров серии ЕС даны в табл. 9.1.
Таблица 9.1. Комплексирование ЭВМ серии ЕС
Устройства ЭВМ. Уровни комплексирования |
Технические и программные средства комплексирования |
Что реализуется в результате комплексирования |
Что обеспечивается в результате комплексирования |
Процессор |
Средства прямого управления (включая шины прямого управления, линии синхронизации и спецкоманды) и механизм внешних прерываний |
Прямая связь между двумя процессорами |
Обмен управляющей информацией между процессорами и необходимая при этом синхронизация их работы |
Оперативная память |
Пульт реконфигура- ции, средства операционной системы и средства прямого управления |
Общее поле опе-ративной памяти и прямая связь между двумя процессорами |
Быстрый параллельный доступ процессоров к программной и числовой информации в общем поле оперативной памяти, реализуемый с участием расширенных средств прямого управления |
Каналы |
Адаптер "канал–канал" и средства операционной системы |
Соединение канала одной ЭВМ с каналом другой ЭВМ |
Быстрая синхронизированная передача программной и числовой информации из оперативной памяти одной ЭВМ в оперативную память другой ЭВМ |
Внешняя память |
Двухканальный пере-ключатель (входной коммутатор) устройств управления внешними устройства-ми и средства ОС |
Общее поле вне-шней памяти |
Одновременный и разнесенный во времени доступ процессоров к большим объемам информации в общем поле внешней памяти |
Многопроцессорный вычислительный комплекс Эльбрус
При разработке МВК Эльбрус ставились следующие три задачи:
· повысить эффективность использования оборудования;
· обеспечить возможность предельной производительности;
· создать высоконадежные резервируемые структуры, обладающие возможностью постепенного наращивания производительности с учетом адаптации к решаемым задачам.
В состав семейства МВК Эльбрус входит система Эльбрус-1 с производительностью от 1,5 млн оп/с до 10 млн оп/с и Эльбрус-2 с суммарным быстродействием 120 млн оп/с.
Все процессоры систем имеют:
· одну и ту же систему команд;
· одинаковую по функциям операционную систему ЕОС (единую ОС).
Основными модулями системы являются:
· центральные процессоры (ЦП) от 1 до 10;
· модули оперативной памяти (от 4 до 32) объемом от 576 Кб до 4608 Кб;
· модули процессоров ввода-вывода (ПВВ) (от 1 до 4);
· модули процессоров передачи данных (ППД) (от 1 до 16);
· модули управления накопителями на магнитных барабанах и дисках, образующие систему управления массовой памятью.
Оперативная память для всех процессоров системы доступна через коммутатор, на который возлагаются функции замены неисправных блоков резервирования (рис. 9.4). Аппаратный контроль охватывает не только работу процессоров, но и работу по обмену информацией на всех уровнях.
Система команд центрального процессора базируется на принципе магазинного обращения к памяти с аппаратной реализацией стека. Внутренний язык машины подобен ПОЛИЗу. В вершине стека могут находиться не только сами операнды, но и ссылки на них, а также ссылки на процедуры их вычисления. По принципу построения СК для ЦП МВК Эльбрус близка к СК KDF-9 и ЭВМ фирмы Барроуз. Однако МВК Эльбрус имеет более развитый аппарат описания типов данных, их защиты, способов распределения памяти, а также развитый аппарат дескрипторов.
Каждый объект данных в памяти снабжен дополнительным управляющим разрядом (тегом), в котором содержится информация о типе данных (целое, вещественное, набор, дескриптор, адрес, метка, формат) и различные управляющие признаки, включая признаки защиты по чтению и записи. Все это позволяет строить чистые (иногда их называют реентерабельные, повторно входимые) процедуры, явно не имеющие ссылок на адреса объектов в математической или физической памяти. Это очень важно, ибо позволяет одно и то же тело процедуры использовать разными процессорами над разными данными. Аппарат дескрипторов и косвенных ссылок позволяет разным программам обращаться к общим
данным.
Многие функции синхронизации процессов, т. е. синхронизации при параллельном выполнении ветвей одной задачи над общими данными, реализованы аппаратно (используется аппарат семафоров).
Модуль ПВВ (процессор ввода-вывода) – это, по сути, специальная ЭВМ с локальной памятью и доступом к основной оперативной памяти. Он служит для управления связью системы с внешними устройствами.
В состав ПВВ входят блоки быстрых каналов, состоящие из 4 селекторных каналов, каждый из которых может обслужить до 64 быстрых абонентов, и блоки стандартных каналов, каждый из которых в свою очередь содержит 16 каналов, обслуживающих до 256 внешних абонентов. Стандартный канал обеспечивает мультиплексное обслуживание медленных абонентов. Кроме того, в состав ПВВ входит блок сопряжения с процессорами передачи данных (до 4 каналов).
 |
Основное назначение ПВВ – освободить ЦП от функций организации очередей обмена, от функций реакций на прерывание по I/О, от функций оптимизации обслуживания очередей запросов на обмен.
Математическая память разбивается на страницы длиной в 512 слов.
В основу программного обеспечения положен принцип достижения высокой эффективности счета при помощи гибкости и адаптируемости МВК. Для этой цели тщательно выбирается сравнительно малый набор основных возможностей программного обеспечения и разрабатываются максимально эффективные средства комплексирования, чтобы программист мог достаточно просто конструировать нужные программы.
Здесь МВК и его ПО как бы адаптируются к решаемым задачам, а не наоборот, как сделано во многих системах, когда алгоритм решаемой задачи модифицируется, чтобы его можно было реализовать в рамках жесткой ВС.
МВК Эльбрус может выполнять программы пользователей БЭСМ-6 благодаря спецпроцессору, реализующему систему команд БЭСМ-6.
Построенный по модульному принципу МВК Эльбрус включает модули центральных процессоров, ОП, процессоров I/О, процессоров приема – передачи данных, внешней памяти на НМБ, НМД, НМЛ, а также устрой-
ства I/О.
Модули ЦП, ОП и процессоров I/О связаны между собой при помощи центрального коммутатора (К). Процессоры приема–передачи данных, промежуточная и внешняя память, а также устройства I/О подключаются к центральной части системы через процессоры I/О.
Модули системы работают параллельно и независимо друг от друга, ресурсы системы динамически распределяются единой операционной системой (ЕОС). ЕОС обеспечивает мультипрограммные режимы ближней и дальней пакетной обработки, режим разделения времени и терминальную обработку.
Для повышения быстродействия аппаратно реализованы базовые конструкции и общепринятые механизмы воплощения ЯП, лежащие в основе систем программирования.
Многоуровневое планирование
В большинстве современных систем процессоры взаимодействуют посредством прерываний. В ЦП прерывание происходит, если истекает отведенный квант времени, или канал заканчивает работу, или выполняемая программа пытается осуществить ввод-вывод. Затем управление передается СУПЕРВИЗОРу, который после осуществления некоторых действий (разблокирование или порождение процесса, запуск канала и т. д.) передает процессор новому процессу из очереди. Следует отметить, что эту работу надо проделывать каждый раз при появлении прерываний, что требует больших затрат времени. Поэтому предлагается метод многоуровневого планирования, который сохраняет всю информацию о процессах, выполняет перевычисления приоритета и т. д., но делает это не очень часто.
В основе этого метода лежит следующий принцип – операции, которые встречаются часто, должны требовать меньше времени, чем те, которые встречаются редко. С этой целью все операции в зависимости от частоты выполнения разбиваются на уровни. Часто используется трехуровневая система планирования: диспетчер, краткосрочный планировщик и долгосрочный планировщик.
Диспетчер вызывается после завершения обработки прерывания, он выбирает следующий готовый процесс для выполнения. Так как он вызывается
часто, то должен срабатывать очень быстро. Например, взять первый процесс из очереди и запустить, т. е. предоставить ему процессор.
Краткосрочный планировщик вставляет процесс в очередь. Здесь возможен анализ состояния процесса. Однако, так как процессы ставятся в очередь довольно часто, краткосрочный планировщик не должен вносить сложных изменений в состояние и приоритет процесса, оставляя подобные действия для долгосрочного планировщика. Долгосрочный планировщик может осуществлять глубокий анализ состояния процессов.
Если наперед известна частота появления вызовов на каждом уровне, то, пользуясь многоуровневым планированием, мы можем ввести ограничения на допустимый объем вычислений на каждом уровне, что во многом определяет алгоритмы планирования на каждом уровне.
Рассмотренные нами алгоритмы планирования представляют собой ряд приемов распределения процессорного времени между процессами. Однако многие из них могут быть с успехом применены и к распределению других ресурсов в операционных системах.
Какими бы ни были методы планирования, должны существовать способы доказательства эффективности этих методов или установления источников потери эффективности.
