Ранг




Справедлива следующая теорема 1.

Теорема 1. Для того чтобы в СКВ с основаниями P1, P2, …, Pn , ортогональными базисами B1, B2, … , Bn , весами m1, m2, …, mn для любого целого AÎ[0, M) с рангом rA существовала ФНР, необходимо и достаточно, чтобы выполнялось соотношение
 | (2) |
Доказательство. Необходимость. Пусть ( x1, x2, … , xn) — код некоторого числа AÎD в заданной СКВ. Предположим, что его можно представить в форме (1). Не нарушая общности рассуждений, будем считать, что A в форме (1) имеет вид
(x1, x2, … , xk, xk+1 – Pk+1, … , xj – Pj, xj+1, …, xn).
|
 |
||
Тогда

A в СКВ имеем

Откуда следует, что

Достаточность. Пусть для rA заданного числа A выполняется (2). Не
нарушая общности рассуждений, предположим, что



т. е. число A имеет ФНР.
Теорема доказана.
Следствие 1. Если для выбранной системы модулей P1,P2, …, Pn веса ортогональных базисов m1 = m2 = … = mn = 1, то для любого AÎ[0, M) существует ФНР.
Следствие 2. Число A в ФНР будет иметь столько отрицательных разрядов, сколько слагаемых mi входит в сумму (2).
Следствие 3. Чтобы число AÎ[0,M) имело единственную ФНР, необходимо и достаточно, чтобы для указанного A сумма (2) была единственной.
Пусть D1 — область определения операций в БСКВ. Как следует из (1) D1Ì[Amin, Amax], где Amin =

Установим связь между кодированием чисел противоположных по знаку. Пусть (x1, x2, … , xn) представление числа A>0 в ФНР. По определению БСКВ
 |
(3) |

симметрично относительно нуля.
Пусть в классической СКВ ранги всех чисел AÎ[0,M) заключены в интервале [r1, r2], а R — множество всех целых чисел из [r1, r2].
Теорема 2. В классической СКВ минимальный элемент множества R равен нулю, а максимальный

Доказательство. Из соотношения



|
 |
||
Исследуем структуру множества D1. Обозначим через


Пусть P - множество всевозможных наборов (x1, x2, …, xn), удовлетворяющих условию –Pi <xi<Pi, i = 1, 2, …, n, для системы модулей P1,P2, … , Pn, допускающих ФНР. Пусть (x1, x2, … , xn) - произвольный набор из P, а ранги чисел AÎ[0, M) принимают все целые значения из интервала [0, r2]. Будем говорить, что заданный набор порождает во множестве D1
новый элемент, если возможно представление его в форме (1) таким образом, чтобы результаты подстановки обеих версий наборов в (3) не были равны.
Утверждение 1. Каждый набор (x1, … , xn) порождает в D1 столько новых элементов, чему равен ранг числа, соответствующего этому набору в СКВ.
Справедливость утверждения 1 вытекает непосредственно из соотношения (1) и теоремы 1.
Следствие 1. Множества
е. ê
Следствие 2. Мощность множества D1 меньше мощности множества целых чисел из интервала [Amin, Amax].
Обозначим через 01 множество особых точек, т. е. 01 – это такое множество, что 01Ì[Amin, Amax], но 0ËD1. Наличие 01
несколько ухудшает характеристики БСКВ. Если окажется, что существуют множества D1, для которых êD1ê = ê[Amin, Amax]ê (мы рассматриваем только целые числа из интервала), то указанный недостаток будет исключен. Вообще говоря, не совсем ясно, насколько существен данный недостаток, так как аналогичная ситуация, возникающая при округлении чисел в позиционной системе счисления (ПСС), не вызывает практических затруднений, и тщательное ее исследование в литературе не встречалось.
Вышеизложенное позволяет сформулировать следующее утверждение.
Утверждение 2. Набор (x1 x2 , … , xn) из P с рангом


Следствие 1. Число AÎ[0, M) не может быть порождающим ни для какого элемента из интервала с номером N>r2.
Следствие 2. Мощность множества D1 равна

Выясним, как построить систему модулей, ортогональные базисы для которых имели бы наперед заданные веса.
Теорема 3. Для того чтобы совокупность целых чисел P1, P2, …, Pn (Pi >1, i = 1, 2, …, n) представляла собой набор оснований системы в коде вычетов, ортогональные базисы для которых имели бы заданные веса m1, m2, … , mn, необходимо и достаточно, чтобы для Pi выполнялось соотношение
 |
(4) |
Доказательство теоремы 3 ведется методом индукции, причем вначале доказывается необходимость условий теоремы, а потом и их достаточность.
Для ускорения поиска оснований безранговых систем необычайно полезно получить оценки (верхние и нижние) для каждого из искомых оснований. Получим также оценки для БСКВ с единичными весами ортогональных базисов.
БСКВ, для которых m1 = m2 = … = mn, необычайно полезны в том плане, что алгоритмы выполнения операций для соответствующих модулей P1, P2, …, Pn значительно проще, чем для произвольных весов ортогональ-
ных базисов.
Утверждение 3. Пусть P1, P2, … , Pn - основания некоторой БСКВ, ортогональные базисы для которой имеют единичные веса, а Pi* = (Pi*) - соответственно нижняя (верхняя) оценка величины основания Pi. Верны следующие равенства:
  |
известны), получим оценку
для Pi*.
1. В применении к БСКВ, указанным в утверждении 3, формула для ортогонального базиса

 |
(5) |
 |


откуда имеем, что

Утверждение доказано.
Пусть S (n) - множество всех БСКВ с mi = 1, i = 1, 2, …, n. При нахождении БСКВ всегда необходимо находить величину g1. Используя полученные результаты, дадим его оценку для некоторого n.
Из (5) следует, что

Вместо P1*
можно взять i-е простое число. Тогда для оценки g1 необходимо подсчитать сумму

можно считать g1
= 1.
Приведем примеры безранговых систем с количеством оснований, равным 3, 4 и 5:
при n = 3: P1 = 2, P2 = 3, P3 = 5;
n = 4: P1 = 2, P2 = 3, P3 = 41, P4
= 7;
n = 5: P1 = 2, P2 = 3, P3 = 7, P4
= 83, P5 = 85;
P1 = 2, P2 = 3, P3 = 7, P4 = 43, P5
= 1805;
P1
= 2, P2 = 3, P3 = 11, P4 = 17, P5 = 59.
Из вышеизложенного следует, что БСКВ позволяет построить сравнительно простые алгоритмы выполнения немодульных операций.
Система в коде вычетов в основном применяется в специализированных вычислительных устройствах из-за высокой сложности операций определения знака числа и сравнения чисел.
Распределение задач по процессорам
Сформированное множество процессов необходимо распределить по процессорам для выполнения. Неизвестен эффективный способ априорного определения числа процессоров, для которого может быть получено наилучшее среди всех возможных распределение. Как правило, рассматриваются алгоритмы распределения при фиксированном числе процессоров. Задача может быть сформулирована следующим образом.
Пусть задано P-процессоров и множество задач Z = {Z1, Z2, ..., Zn}, которые надо решить на МВС. Каждая задача из Z может характеризоваться некоторыми параметрами, в частности объемом требуемой памяти, необходимым временем центрального процессора и т. д. Следует построить распределение S1, S2, ..., Sm
задач по процессорам МВС, учитывая параметры задач, с тем, чтобы минимизировать, скажем, общее время решения всего множества задач Z.
При распределении множества задач следует учитывать существующие связи между ними и обеспечивать экстремальное значение некоторому критерию качества при определенных ограничениях. Достижение экстремума может производиться и за счет изменения структуры ВС. Однако динамическая адаптация структуры ВС очень ограничена, и поэтому обычно считают, что состав и структура ВС не изменяются во все время ее работы.
Вообще говоря, методы распределения наборов задач существенно зависят от мощности набора, момента его поступления, времени обработки отдельных задач на каждой машине, связности задач, степени однородности компонент системы, методов обмена информацией между отдельными компонентами и т. д. Однако многие из указанных параметров известны, как правило, с невысокой достоверностью. Кроме того, учет всех параметров при распределении задач необычайно сложен, в связи с чем обычно строятся распределения при различных упрощающих ограничениях. Широкое распространение при распределении процессоров в случае параллельных вычислений получили методы теории расписаний. Наибольший эффект при этом достигается, если набор задач на распределение поступает одновременно и известно время реализации каждой задачи.
Мы укажем только на некоторые случаи однократных алгоритмов построения расписания, т. е. алгоритмов, не изменяющих момент начала выполнения задач при последующем составлении расписания. Это так называемые алгоритмы диспетчирования.
Известны два подхода к проблеме диспетчирования. При первом каждая задача из входного набора предварительно назначается для обслуживания на некоторую машину. Задачи начинают выполняться только после окончания диспетчирования всего входного набора. Метод, основанный на таком подходе, называют статическим диспетчированием. Задача статического диспетчирования допускает оптимальное решение, которое в принципе можно получить полным перебором возможных вариантов. Однако с ростом числа вариантов эффект от использования оптимального распределения (по сравнению с некоторым случайным распределением) может быть сведен на нет трудоемкостью получения оптимального результата.
При втором подходе задачи назначаются для выполнения по мере освобождения машин (процессоров) от решения ранее распределенных задач. Здесь проблема, решаемая диспетчером, значительно упрощается, так как будет анализироваться не весь входной набор, а только некоторые подмножества его задач, готовых к выполнению и ожидающих своего распределения. В этом случае будем говорить о динамическом диспетчировании. Применение динамического диспетчирования приводит, как правило, к субоптимальному решению задачи о назначениях. Такое решение получаем, применяя алгоритмы со сравнительно малой трудоемкостью, при этом качество полученного решения незначительно отличается от оптимального.
Для конкретной МВС при заданном входном наборе задача диспетчирования может быть сформулирована как одна из задач математического программирования, а именно "задача о назначениях", для решения которой можно использовать известные методы целочисленного программирования. Однако с ростом числа задач во входном наборе трудоемкость применения этих методов превосходит получаемый от их использования эффект.МВС может быть занята в этом случае решением задачи диспетчирования более длительное время, чем временной выигрыш, полученный в результате ее решения. Поэтому второй подход, основанный на методах динамического диспетчирования, считается более перспективным.
Чаще всего в качестве критерия работы диспетчера выбирается время выполнения всего набора задач, хотя используются и другие критерии: минимальное время простоя (максимальная загрузка) различных устройств МВС; минимальное среднее время ожидания решения для всего набора задач; минимальное число используемых процессоров при заранее заданном времени окончания решения задач и т. д. Иногда используются обобщенные критерии в виде функции, устанавливающей зависимость между отдельными частными критериями. Качество диспетчера тогда – отклонение от экстремального значения обобщенного критерия. Большую сложность здесь представляет процедура обоснованного формирования функции, задающей обобщенный
критерий.
Реакция управляющей процедуры
образования
нового процесса
Для ускорения обработки управляющей процедурой всех записей последние хранятся не в виде последовательных записей (массива), а в виде списковой структуры. При организации списковой структуры проблема "сборки мусора" решается автоматически, ибо свободная запись сразу подключается к списку "свободного места".
Операции над процессами служат для их создания, обработки и уничтожения. Наиболее типичные операции над процессами: создать новый процесс; уничтожить процесс; приостановить процесс; активизировать процесс; установить приоритет процесса; определить состояние процесса.
RISC- и CISC-АРХИТЕКТУРА
При проектировании суперминикомпьютеров на базе последних достижений СБИС-технологии оказалось невозможным полностью перенести в нее архитектуру удачного компьютера, выполненного на другой элементной базе. Такой перенос был бы очень неэффективен из-за технических ограничений на ресурсы кристалла: площадь, количество транзисторов, мощность рассеивания и т.д.
Для снятия указанных ограничений в Беркли (США, Калифорния) была разработана RISC(Restricted (reduced) instruction set computer)-архитектура (регистро-ориентированная архитектура). Компьютеры с такой архитектурой иногда называют компьютерами с сокращенным набором команд. Суть ее состоит в выделении наиболее употребительных операций и создании архитектуры, приспособленной для их быстрой реализации. Это позволило в условиях ограниченных ресурсов разработать компьютеры с высокой пропускной способностью.
Семантический разрыв между архитектурными решениями ЭВМ и его программным окружением
Все характерные особенности архитектуры большинства сегодняшних компьютеров появились уже к 1960 г. Среди них индексные регистры, регистры общего назначения, данные в форме с плавающей точкой, косвенная адресация, программные прерывания, асинхронный ввод-вывод, виртуальная память, мультипроцессорная обработка.
В основном сегодняшние компьютеры отличаются от прежних лишь стоимостью, надежностью, быстродействием и элементной базой. Концептуальные возможности не претерпели существенных изменений.
При анализе особенностей архитектурных решений возникают следующие вопросы:
· оптимальны ли на все времена архитектурные решения, предложенные в 50–60?х годах?
· достаточные ли изменения претерпела технологическая база (аппаратная и теоретико?концептуальная), чтобы считать оправданными изменения архитектуры компьютеров?
Рассмотрим архитектурные решения, базирующиеся на концепции фон Неймана, и в первую очередь различия принципов, которые лежат в основе современных языков программирования (ЯП) высокого уровня, и принципов, определяющих архитектуру ЭВМ.
Этот феномен известен как семантический разрыв. Как правило, современные компьютеры имеют нежелательно большой семантический разрыв между объектами и операциями, описываемыми в ЯП, и объектами манипулирования и соответствующими операциями, реализуемыми архитектурой ВС. Обобщая, можно говорить о семантическом разрыве между архитектурой машины и средой использования.
Все это порождает ряд проблем: высокая стоимость разработки ПО, его ненадежность, большой объем программ, сложность компиляторов и ОС, наличие отступлений от правил построения ЯП.
Для уяснения семантического разрыва можно проанализировать взаимосвязи между каким?нибудь ЯП (например, ПАСКАЛЬ, С++, DELPHI, PL/1) и архитектурой ЭВМ, скажем с архитектурными решениями наиболее распространенных у нас компьютеров фирмы IВМ, и оценить "расстояние" между принципами, положенными в основу ЯП, и соответствующими принципами, положенными в основу архитектуры ЭВМ.
Попробуем сравнить несколько основополагающих принципов языка PL/1, широко используемых в ВС, с идеологией mainframe и определить адекватность их принципам, заложенным в IВМ 370.
Массивы. Это наиболее часто используемый тип организации данных. PL/1 позволяет использовать многомерные массивы, обращение к отдельным элементам массива посредством индексов, операции над целыми массивами, обращение к отдельным подмассивам внутри массива, защиту от выхода за пределы соответствующего массива. В языке АДА, например, имеется возможность соединения массивов.
Исследование архитектуры IВМ 370 показывает, что в ней нет средств, адекватных описываемым принципам работы с массивами, за исключением разве что примитивного подобия одного из принципов языка – использование индексных регистров. Следовательно, реализация принципа организации данных в виде массива возлагается на компилятор, в распоряжении которого имеется лишь набор команд IВМ 370, весьма далекий по своим возможностям от задач, возникающих при работе с массивами.
Структуры. Это второй из часто используемых типов организации данных в виде наборов разнородных элементов данных (в некоторых ЯП называемых записями). И здесь в системе IВМ 370 отсутствуют средства, адекватные структурам и операциям над ними.
Строки. В PL/1 используются строковые данные (или просто строка). Допустимые операции: слияние, выделение заданной части (подстроки), поиск строки по заданной подстроке, определение длины текущей строки, проверка присутствия одной строки в другой строке. Подобные возможности в системе команд IВМ 370 не предусмотрены. Более того, задача манипулирования строками битов (возможность, предоставляемая PL/1) осложняется еще и тем, что в IВМ 370 допускается адресация к группам из 8 бит, т. е. к байтам. И опять-таки все это надо реализовывать через компилятор, что существенно усложняет его работу.
Процедуры. При вызове процедуры требуется сохранить состояние текущей процедуры, динамически назначить память для локальных переменных вызванной процедуры, передать параметры и инициализировать выполнение вызванной процедуры.
Что есть в архитектуре IВМ 370? Только команда BALR (переход с возвратом). Но вклад этой команды в реализацию операций вызова процедуры настолько мал, что ее отсутствие осталось бы незамеченным. Компилятор мог бы заменить ее двумя командами: LA (загрузка адреса) и BR (переход безусловный).
Ясно, что эти трудности по несоответствию принципов ЯП и архитектуры должны реализовываться за счет сложного компилятора.
Важно также сравнить имеющийся семантический разрыв с частотой использования соответствующих операций, предоставляемых ЯП. Из литературы известно, что 45 % всех арифметических операторов имеют дело с массивом или элементом массива, 16 % всех выполняемых операторов языка высокого уровня – это обращение к подпрограммам?процедурам, подпрограммам?функциям и операторы возврата. Компилятор с ФОРТРАНА, например, тратит до 15 % своего времени на установление связей между подпрограммами. Другие исследования говорят, что 19 % всех операторов программы составляют операторы CALL, RETURN, PROCEDURE.
Подобным образом можно проанализировать семантический разрыв между ЭВМ и операционной системой. В частности, понятие процесса как принципа обработки в системах параллельного действия никак не отражается в архитектуре компьютера, а все вопросы, связанные с синхронизацией процессов, решаемые через семафоры, критические секции, мониторы и передачи сообщений, не нашли своего воплощения в интерфейсе ЭВМ.
Значительный разрыв существует между архитектурой ЭВМ и принципами построения программного обеспечения. Известно, например, что около 50 % всех ресурсов тратится на тестирование и отладку программ, однако архитектура ЭВМ дает ничтожные средства для этого, хотя для надежности аппаратных средств создаются весьма существенные разработки.
Семантический разрыв между архитектурой и организацией памяти программисту заметить труднее. Однако такой вопрос, как разный тип адресации в зависимости от того, где хранятся данные, проанализировать достаточно просто.
Действительно, для оперативной памяти осуществляется линейное смещение, добавляемое к адресу, хранимому в спецрегистре, а для данных на магнитном диске используются номер диска, цилиндра, дорожки и линейное смещение в пределах записи. То же имеем и при выполнении операции. Так, операция умножения может быть выполнена непосредственно, если оба операнда находятся в ОП, если же они на НМД, то необходимо предварительно скопировать их в оперативную память. И так как эти принципы не заложены в архитектуре, то имеющийся разрыв программистам приходится обходить при создании ЯП за счет моделирования организации памяти. Виртуальная память создает лишь иллюзию решения проблемы.
Изложенные и другие проблемы семантического разрыва, не разрешенные в архитектуре ЭВМ, ухудшают надежность программного обеспечения, увеличивают непроизводительные затраты и перекладывают их разрешение на компилятор, а последний, как правило, на плечи прикладного программиста из?за отсутствия удачных и оптимальных решений во время компиляции. Это, например, происходит, если идет обращение к переменной, значение которой не определено, или к элементу массива, один из индексов которого выходит за соответствующие пределы.
Семантический разрыв требует для своего разрешения через компилятор значительных затрат машинного времени и памяти.
Так, компилятор языка PL/1 фирмы IВМ генерирует 17 машинных команд для реализации оператора
C(I,J) = A(I,J) + B(I,J),
где А, В и С – массивы двоичных элементов одинакового размера в форме с фиксированной точкой.
Если подсоединяется средство контроля данной операции, то компилятор генерирует уже 75 машинных команд, а время выполнения оператора вырастает в 3 раза. Такой же контроль может быть выполнен компьютером без затрат дополнительной памяти и времени, если реализовать на более быстродействующей машине аппаратный контроль.
Здесь впору сказать об экономии памяти для хранения сгенерированных компилятором команд (объектного кода), а также обсудить объем пересылок между памятью и процессором.
И хотя бытует мнение, что проблема "памяти" скоро исчезнет, проблема эта существует. Во-первых, из-за ее дороговизны (стоимость основной памяти микропроцессорной системы значительно превосходит стоимость процессора), а во-вторых, потребность в памяти растет пропорционально снижению ее стоимости.
Все изложенное делает очевидным семантический разрыв между архитектурой компьютера и принципами, определяющими построение компиляторов. Чтобы эффективно ликвидировать существующий семантический разрыв, необходимо делать компилятор очень сложным.
Естественно, существующий разрыв можно уменьшить или устранить вообще за счет усложнения архитектуры ЭВМ. Ясно, что если ЭВМ имеет не один, а несколько компиляторов и каждый из них содержит такие средства, как вызов процедур, описание массивов и т. д. (а это почти всегда так), то выгодно ликвидировать этот разрыв один раз за счет соответствующей модификации архитектуры машины, даже если других преимуществ и не будет.
Семантический разрыв порождает и некорректное использование языка программирования. Так, если в PL/1 мы объявляем переменную B как DCL B DECIMAL FIXED (2), т. е. двухразрядной десятичной с фиксированной точкой, а при использовании оператора присваивания напишем В = 200, то естественно ждать сообщение об ошибке. Но его нет. И при выводе на печать значения B мы получим 200. Все дело в том, что система IBM 370 может представлять десятичные числа, имеющие только нечетное количество цифр. Чтобы при полном устранении семантического разрыва не прийти к генерированию неэффективных объектных кодов, компилятор преобразует двухразрядные десятичные переменные в трехразрядные операнды машины. Если бы мы изменили соответствующие правила языка PL/1, то язык стал бы машинно-зависимым, с ориентацией на IBM 370.
Тот же вариант некорректности может возникнуть при работе с десятичными и двоичными числами, использование которых допускает язык PL/1. Программисты иногда применяют двоичные числа вместо десятичных, ибо первые занимают меньше памяти, не требуют преобразования данных, а операции над ними выполняются быстрее, чем над десятичными.
Следовательно, архитектура используемого компьютера приводит к некорректному применению языка программирования.
Подобные некорректности можно найти и в других ЯП. Например в языке ФОРТРАН условный оператор IF имеет три точки перехода: = 0, > 0, < 0. Но это не широкие возможности языка, а зависимость его от архитектуры IBM 704, где встроенная операция сравнения в зависимости от результата своего выполнения передает управление одной из трех последующих команд.
В языке АДА для повышения надежности программирования тоже введен ряд компромиссов и ограничений при использовании современных ЭВМ, чтобы ошибки, появляющиеся, например, из?за применения в арифметических операциях несовместимых операндов или обращения за допустимое адресное пространство, было возможно выявить на стадии компиляции.
Как следствие семантического разрыва – низкая производительность при проектировании программ. Создатель прикладного ПО тратит больше времени на управление памятью и пересылку данных, чем на собственную их обработку. Последние исследования показывают, что каждый 20?й оператор в PL/1?программах – это ввод и вывод информации.
Совершенствование архитектуры компьютера по устранению семантического разрыва также ограничено принципами построения, например, архитектуры процессора. Так, в случае реализации параллелизма при организации процессора используются только два варианта обработки: мультипроцессорный и поточный. Причем мультипроцессорная обработка решает проблему лишь частично из?за сложности выделения независимых фрагментов программы, которые можно выполнять параллельно (задача декомпозиции), трудностей синхронизации взаимодействующих процессов и перекрытия областей памяти.
Схема алгоритма
1. Представление исходной программы в виде графа. Этот процесс достаточно подробно изложен выше.
2. Сведение циклического графа к ациклическому. Большое количество вершин графа G приводит к большому порядку матрицы смежности C. Для уменьшения порядка матрицы произведем сжатие линейных участков программы в отдельные обобщенные операторы, т. е. выделим в исходном графе G линейные подграфы и поставим им в соответствие одну обобщенную вершину графа, не нарушая при этом ни одного из существующих ориентированных циклов. Таким образом, из исходного графа G мы получаем граф G¢. Затем в графе G¢ выделим множество сильносвязных подграфов. Каждый сильносвязный подграф заменим отдельной вершиной. После выполнения указанных действий в общем случае циклический граф G превращается в сжатый ациклический граф G¢¢, представляющий собой модель исходной программы. Вершинами графа G¢¢ будут фрагменты исходной программы в виде линейных участков и сильносвязных областей.
3. Наложение информационных связей, заданных между операторами программы, на связи возможных переходов. До этого момента информационно-логические связи, заданные между операторами программы, не претерпевали существенных изменений. Преобразуем их, учитывая взаимосвязи укрупненных вершин графа G¢¢.
Если в графе G¢¢ существует переход от вершины vi
к вершине vj, то это совсем не означает, что начало выполнения оператора, соответствующего вершине vj, должно тут же следовать за окончанием оператора, соответствующего вершине vi. Однако, если результат оператора vi
является аргументом оператора vj, то в данном случае выполнение оператора vj не может начаться раньше, чем окончится выполнение оператора vi.
После анализа входов и выходов для всех компонент приведенного графа G¢¢ производится наложение информационных связей на связи возможных переходов, т. е. на связи, представленные в матрице смежности графа G¢¢. Для анализа входов и выходов всех компонент графа G¢¢ необходимо составить матрицу H информационной зависимости, элементы которой hij принимают соответственно значения 0 или 1.
При этом
|
ì 1, если j- й оператор зависит от значений переменных, |
|
|
hij = |
í полученных в i-м операторе; |
|
î 0, в противном случае. |
Выполняем этот процесс со всеми изменяемыми переменными первого оператора. Затем выделяем изменяемые переменные второго оператора и повторяем весь процесс сначала, и т. д. до последнего оператора. Число строк и столбцов в матрице информационной зависимости равно числу операторов в программе. Число единиц в столбце матрицы указывает количество операторов, от которых зависит оператор, соответствующий данному столбцу.
В результате выполнения этого этапа граф G¢¢ преобразуется в граф


4. Распределение вершин графа по уравнениям готовности. На данном этапе исходя из графа
операторов и устанавливается между ними отношение предшествования. Е-разделение определяет класс операторов, параллельное выполнение которых должно быть завершено прежде, чем начнут выполняться операторы следующего класса. По выполнению этого этапа все операторы (вершины графа
5. Формирование ветвей решения. На пятом этапе анализируются компоненты каждого уровня. Если анализируемая вершина уровня представляет собой сильносвязный подграф, то в нем выделяются элементарные циклы, компонентами которых являются отдельные линейные фрагменты. Если же исследуемая вершина отображает сжатый линейный участок программы, то анализируются информационные связи внутри этого линейного участка.
В результате указанных действий каждый уровень разбивается на несколько подуровней и производится их согласование. Операторы исходной программы, окончательно распределенные по уровням готовности, объединяются в ветви решения, что и является окончательным результатом рассматриваемой процедуры распараллеливания.
Синхронизация процессов
Процессы, выполняемые в мультипрограммном режиме, можно рассматривать как набор последовательных слабосвязанных процессов, которые действуют почти независимо друг от друга, лишь изредка используя общие ресурсы. Взаимосвязь между такими процессами устанавливается с помощью различных сообщений и так называемого механизма синхронизации, который позволяет согласовывать и координировать работу процессов.
Хотя каждый процесс, выполняемый в мультипрограммном режиме, имеет доступ к общим ресурсам, существует некоторая область, которую в фиксированный момент времени может использовать лишь один процесс. Нарушение этого условия приведет к неизвестному порядку обработки процессов. Назовем такую область критической. При использовании критической области возникают различные проблемы, среди которых можно выделить проблемы состязания (гонок) и тупиков (клинчей).
Условие состязания возникает, когда процессы настолько связаны между собой, что порядок их выполнения влияет на результат операции.
Условие тупиков появляется, если два взаимосвязанных процесса блокируют друг друга при обращении к критической области.
В системах, допускающих перераспределение любых ресурсов в произвольной последовательности, но имеющей и неосвобожденные ресурсы, время от времени должны возникать тупиковые ситуации.
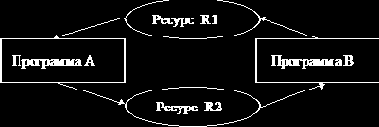 |
Пример. Пусть программе А нужен ресурс R1. Она запрашивает его и получает. Программе В нужен ресурс R2. Она запрашивает его и получает (рис. 7.6). Далее, пусть программа А, не отпуская R1, запрашивает R2, а программа В, не отпуская R2, запрашивает R1. Налицо типичный клинч, если только один из ресурсов R1 или R2 не может быть освобожден до момента завершения обработки соответствующего процесса.
Рис. 7.6. Пример тупиковой ситуации
Для разрешения подобных проблем наиболее часто используют простейшие приемы синхронизации процессов, тесно связанные с аппаратным оборудованием.
Простейший прием – стандартные операции типа WAIT (ЖДАТЬ) и SIGNAL (ОПОВЕСТИТЬ). Операция WAIT позволяет: временно заблокировать процесс, а SIGNAL информирует систему о необходимости разблокирования процесса, задержанного из-за невыполнения условия. Следует отметить такие приемы, как БЛОКИРОВКА ПАМЯТИ (для реализации взаимного исключения одному процессу разрешается выполнить операцию над памятью, а другому ждать, пока первый не завершит работу); ПРОВЕРКА и УСТАНОВКА (аппаратная операция, к которой обращаются с двумя параметрами: ЛОКАЛЬНЫЙ И ОБЩИЙ). Эти приемы хотя и решают задачу взаимного исключения, однако неэффективно используют процессорное время из-за необходимости пребывания в активном состоянии процесса, ожидающего разрешения продолжить работу. Наиболее эффективным и простым средством синхронизации процессов, исключающим состояние "активного" ожидания, является семафор.
Система программирования МВК Эльбрус
Рассмотрим общие программные средства, применяемые для создания приложений в системах программирования МВК Эльбрус.
Системы кодирования данных с отрицательным основанием
Известны компьютеры, работающие в СКД с отрицательными основаниями. Это обычно машины последовательного действия. При выполнении арифметической операции оба операнда поступают на вход одновременно и обязательно младшими разрядами вперед, чтобы легко было осуществлять перенос в старшие разряды.
Целесообразность введения отрицательного основания обусловливается тем, что знак числа органически включается в представление числа, в связи с чем специально его отображать не надо.
Неудобство использования системы состоит в том, что при реализации процесса суммирования на один разряд могут прийтись два переноса, что усложняет схему сумматора.
С точки зрения интервала представимых чисел при отрицательном основании имеет место некоторая несимметричность. Так, при четном m (количестве разрядов) отрицательных чисел может быть представлено больше, чем положительных, а при нечетном наоборот.
Примеры. Пусть основание системы n= -2. Тогда при количестве разрядов m = 4 имеем:
| 0001=+1 | 0110=+2 | 1011=-9 | |||
| 0010=-2 | 0111=+3 | 1100=-4 | |||
| 0011=-1 | 1000=-8 | 1101=-3 | |||
| 0100=+4 | 1001=-7 | 1110=-6 | |||
| 0101=+5 | 1010=-10 | 1111=-5 |
Итак, положительные числа: 1, 2, 3, 4, 5 (их пять), а отрицательные: –1, –2, ..., –10 (их десять).
При m = 3:
| 001= +1 | 100 = +4 | 110 = +2 | |||
| 010= –2 | 101 = +5 | 111 = +3 | |||
| 011= –1 |
Итак, положительные числа: 1, 2, 3, 4, 5, а отрицательные: -1, -2.
Известно, что каждое целое число A
может быть представлено в виде

где при n < –1 имеет место 0 £ Ci < –n–1.
Для дробных чисел верно

Рассмотрим наиболее привычный нам частный случай СКД при n = –2. Здесь Ci Î {0; 1}. Предположим, что m = 5. Тогда таблица представления целых чисел от –10 до 10 будет иметь следующий вид (табл. 5.1).
Таблица 5.1. Представление целых чисел
| Веса | (-2)4 | (-2)3 | (-2)2 | (-2)1 | (-2)0 | Веса | (-2)4 | (-2)3 | (-2)2 | (-2)1 | (-2)0 | ||||||||||||
| Числа | 16 | ?8 | 4 | ?2 | 1 | Числа | 16 | ?8 | 4 | ?2 | 1 | ||||||||||||
| 0 | 0 | 0 | 0 | 0 | 0 | ?10 | 0 | 1 | 0 | 1 | 0 | ||||||||||||
| 1 | 0 | 0 | 0 | 0 | 1 | ?9 | 0 | 1 | 0 | 1 | 1 | ||||||||||||
| 2 | 0 | 0 | 1 | 1 | 0 | ?8 | 0 | 1 | 0 | 0 | 0 | ||||||||||||
| 3 | 0 | 0 | 1 | 1 | 1 | ?7 | 0 | 1 | 0 | 0 | 1 | ||||||||||||
| 4 | 0 | 0 | 1 | 0 | 0 | ?6 | 0 | 1 | 1 | 1 | 0 | ||||||||||||
| 5 | 0 | 0 | 1 | 0 | 1 | ?5 | 0 | 1 | 1 | 1 | 1 | ||||||||||||
| 6 | 1 | 1 | 0 | 1 | 0 | ?4 | 0 | 1 | 1 | 0 | 0 | ||||||||||||
| 7 | 1 | 1 | 0 | 1 | 1 | ?3 | 0 | 1 | 1 | 0 | 1 | ||||||||||||
| 8 | 1 | 1 | 0 | 0 | 0 | ?2 | 0 | 0 | 0 | 1 | 0 | ||||||||||||
| 9 | 1 | 1 | 0 | 0 | 1 | ?1 | 0 | 0 | 0 | 1 | 1 | ||||||||||||
| 10 | 1 | 1 | 1 | 1 | 0 |
Из табл. 5. 1 видно, что знак числа определяется местоположением первой значащей цифры: если старшая значащая цифра стоит в четном разряде, число отрицательное, если в нечетном – положительное.
Рациональные числа
Веса |
(?1/2) |
(?1/2)2 |
(?1/2)3 |
(?1/2)4 |
?1/2 |
¼ |
?1/8 |
1/16 |
|
Числа |
?0,5 |
0,25 |
?0,125 |
0,0625 |
1. Сложение. Пусть ai, bi – разряды слагаемых; Pi-1 – перенос из (i?1)-го разряда на i-й; Pi – перенос из i-го в (i+1)-й. Тогда справедливо соотношение gi + Pi(–2) = ai + bi+Pi-1.
Возможные значения разрядов:
Pi Î{0; 1;

Пример. Пусть gi + Pi(?2) = 2, тогда gi = 0, Pi =?1;
gi + Pi(–2) = –1, тогда gi =1, Pi =1.
Системы кодирования данных с симметричным представлением цифр
В известных позиционных системах кодирования данных (СКД) для изображения положительных и отрицательных чисел используются знаки "+" и "–". В позиционных сокращенных системах кодирования, где разряды числа наряду с положительными могут принимать и отрицательные значения, знак числа явно не указывается.
Особое место среди систем такого рода занимает троичная СКД. В ней введены цифры 0, 1,
Число A в этой системе записывается в виде
A= an an-1 ... a1 a0 a-1 a-2 ...,
где каждое ai может принимать значения {0, 1,
A= an3n+an-13n-1+ ...+ a13+a0+ a-13-1+a-23-2+ ... ,
где 3n, 3n-1, ..., 30, 3-1, 3-2, ... – веса разрядов.
Примеры представления чисел.
| –1= | 1=13 | –10 | = | | |||||
| –2= | 2=1 | 10 | = | 1013 | |||||
| –3= | 3=103 | 0 | = | 03 | |||||
| –4= | 4=113 | 1/3 | = | 0,(3)=0,13 | |||||
| –5= | 5=1 | 32/81 | = | 0,11 |
Замечание. Знак числа определяется знаком старшей значащей цифры троичного изображения числа.
СИСТЕМЫ ПАРАЛЛЕЛЬНОГО ДЕЙСТВИЯ
Исследование разработок по применению персональных компьютеров показывает, что сложилась устойчивая тенденция к усилению их персонализации за счет развития дружественного человеко-машинного интерфейса, с одной стороны, и углублению проблемной ориентации за счет специализации в конкретной сфере деятельности – с другой. Однако наука и практика в последнее время выдвигают ряд жизненно важных задач, которые требуют для своего решения выполнения 1015–1017
операций. Среди таких задач называют задачи обработки изображений, системы динамических испытаний, искусственного интеллекта, ядерной физики, экономики и т. д. Например, задача квантовой хромодинамики, вычисление массы протона и нескольких связанных частиц, требует выполнения 1017 операций.
Поток информации в указанных и других системах настолько возрос, а необходимость в быстрой и экономной ее обработке так жизненно важна, что потребность в их скорейшем разрешении во многом определяет нормальное функционирование общества в целом.
В связи с этим никак нельзя ограничиваться использованием и развитием только персональных компьютеров. Возникает настоятельная потребность в создании мощных высокопроизводительных машин, чаще называемых высокопроизводительными вычислительными системами ВВС.
Специализированные системы программирования
Клу (Clu) – для разработки больших программных комплексов с использованием абстрактных типов данных (АТД). Требование практического программирования в повышении модульности, надежности и наглядности программ позволило в начале 70-х годов Н. Вирту, О. Далу, Ч. Хоару сформулировать принципы АТД. Суть концепции АТД состоит в том, что создание и обработка объектов некоторого (абстрактного) типа возможны лишь через определенный набор операций, связанных с этим типом. Таким образом, программист абстрагируется от конкретного представления объектов данного типа и от реализации операций. Они недоступны (инкапсулированы в определении типа). Аксиоматика, определяющая свойства типа и любой его реализации как элемент концепции АТД, часто описывается неформально, в виде комментариев.
Практическое применение концепции АТД сдерживалось до недавнего времени, видимо, в основном из-за:
· отсутствия реализаций языков с АТД (элементы АТД встречались в языках АДА; МОДУЛА-2 и др.);
· семантического разрыва между языками программирования и архитектурой ЭВМ, что сдерживает реализацию (или делает ее неэффективной) современных средств ЯП, в частности АТД;
· инерции программистов при освоении новых методов программирования. Единственным способом использования концепций АТД является метод моделирования с помощью простых средств: процедур, макроопределений, библиотечных текстовых вставок.
Одним из наиболее емких и сравнительно простых в реализации ЯП с концепцией АТД является язык Clu, созданный коллективом Массачусетского технологического института (США). Это язык модульного программирования. Программа на нем состоит из группы модулей: процедур (абстракций исполнения), кластеров (абстракций данных) и итераторов (абстракций управления). Кластерные модули, к примеру, определяют класс родственных абстрактных типов данных как список с произвольным типом элементов t (параметром кластера). Над АТД данного класса определяются некоторые операции. Массивы в языке Клу могут динамически расширяться и сокращаться с обоих концов, в связи с чем границы массива в обозначении типов не указываются.
для решения задач обработки нечисловой
·
СНОБОЛ-4, РЕФАЛ, ЛИСП, ПЛЭНЕР – для решения задач обработки нечисловой информации.
Язык СНОБОЛ-4 – широко распространенный язык символьной обработки. До Эльбруса он был реализован на ЭВМ IВМ/360 и PDP-11. Основные типы данных в языке СНОБОЛ-4 – строка символов (STRINQ) и образец (PATTЕRN). Набор операций над строками включает конкатенацию, сравнение с образцом, неявное присвоение сопоставленных фрагментов строк, замещение по образцу. Характерно, что смысл и число аргументов любой операции (например, "+") могут быть переопределены исполняемым
оператором.
Язык РЕФАЛ разработан для задач обработки текстов, аналитических выкладок, автоматического доказательства теорем и т. д.
Программа на данном языке определяет, по существу, систему подстановки термов, под управлением которой выполняется вывод из исходного текстового выражения другого текстового выражения. Программа на языке РЕФАЛ представляет собой последовательность предложений (правил вывода):
K | D | E = F,
где K – начальный символ конкретизации (признак начала предложения); D – детерминатив (идентификатор, играющий роль имени функции); E – текстовое выражение (аргумент); F – также текстовое выражение (результат конкретизации).
Пример рефал-программы для "переворачивания слова":
K | П | E1S2 = S2 | П | E1.
Пусть есть строка "течаз". Укажем состояние "поле зрения" после каждого шага вывода:
К|П|ТЕЧАЗ.®3 К|П|ТЕЧА.®3А К|П|ТЕЧ.®...®ЗАЧЕТ К|П| .® ЗАЧЕТ
АБВ – для разработки систем программирования. Это расширенный язык программирования, созданный как базовый язык для разработки трансляторов. Конструкции АБВ-языка делятся на три группы: анализатор (аппарат работы со строками), базу (средства именования и управления) и вычислитель (конструкции низкого уровня для выполнения вычислений, настраиваемые на конкретную ЭВМ). Язык АБВ в системе программирования (автор С.С.
Лавров) играет роль инструментального языка и выходного языка.
Анализатор служит для лексического и синтаксического анализа текстов на входном языке и для генерации выходного текста на АБВ-языке. База используется для выражения семантики аппарата имен, средств типизации и управления входного языка. Вычислитель применяется как подмножество выходного языка для трансляции действий над числовыми и логическими значениями, а также для выполнения вычислений в АБВ-программах.
СОЛ – для решения задач моделирования.
МИС – для автоматизации разработки пакетов прикладных программ. Это адаптированная для МВК Эльбрус версия системы программирования ПРИЗ со входным языком УТОПИСТ.
ФОРТ
(СП на базе расширяемого языка FORTH-83). Язык ФОРТ широко используется для разработки программного обеспечения мини- и микроЭВМ. Он рассчитан на работу в диалоговом режиме. Стандартные слова языка ФОРТ обеспечивают адресную арифметику, доступ к реальным адресам и другие возможности языков ассемблерного типа.
ДИАШАГ
– система для разработки и отладки программ в интерактивном режиме на основе пошагового транслятора с языка АЛГОЛ-60. Основное отличие пошагового транслятора от обычных "пакетных" состоит в том, что текст программы для пошагового транслятора может вводиться и корректироваться шагами – фрагментами программ, разделение на которые осуществляет программист. Шаг программы может состоять из одного или нескольких описаний или операторов и имеет свой номер, который задается при вводе или коррекции шага. Причем коррекция автоматически вызывает его перетрансляцию.
Система программирования МВК Эльбрус – это открытая система. Она пополняется языками C, Prolog и др.
Специфика передачи информации в вычислительных системах
Вычислительные системы с точки зрения задач контроля и возможностей его организации имеют существенные особенности.
1. К достоверности ВС предъявляются более высокие требования. Работа в ВС осуществляется автоматически, без участия человека, как это иногда бывает при приеме текста, и исправить ошибку "по здравому смыс-
лу" нельзя.
2. Помимо передачи информации, в ВС осуществляются длительное ее хранение и обработка, связанная с выполнением большого числа арифметико-логических операций. Здесь методы контроля в КС применимы лишь при хранении и передаче информации (идет проверка на предмет изменения информации). Совсем другая задача при обработке информации, ибо она меняется и при отсутствии ошибок. Используемые методы контроля должны проверять, правильно ли произведены изменения, т. е. выполнились операции. Особенность ВС еще и в том, что каждое передаваемое слово может оказаться результатом других операций. Поэтому несвоевременно обнаруженная даже одиночная ошибка может привести к искажению многих данных. В КС отдельные слова с точки зрения достоверности не связаны друг с другом.
3. В ВС используется обрабатываемая и управляющая информация. С точки зрения контроля эти два вида информации существенно различаются. Ошибка в команде, произошедшая в результате ее хранения, передачи или расшифровки, обычно приводит к более тяжелым последствиям, чем ошибка в операнде, ибо могут уничтожиться результаты многих предыдущих операций (этапов задачи). Особенно это опасно в управляющих машинах, работающих в реальном масштабе времени, т. е. в первую очередь система контроля должна обеспечить защиту программы.
4. Обычно каждой выполняемой операции предшествуют поиск и выборка из ЗУ очередной команды и операнда. Искажение адреса – и будет выполнена не та команда или не над теми операндами. Возникает задача контроля адресного тракта.
5. Все элементы ВС в отличие от КС находятся территориально, как правило, в одном месте. Исправление ошибки может начаться незамедлительно после ее обнаружения.
6. С точки зрения вероятности возникновения ошибок различные устройства ВС тоже неодинаковы. Наиболее слабым местом, нуждающимся в строгом контроле, является внешний накопитель информации на НМД, а также устройства ввода-вывода.
В последнее время производят компьютеры с модульной структурой. В них основные устройства выполнены в виде отдельных модулей, имеющих самостоятельное функциональное значение, т. е. каждое устройство может выполнять свои функции при наличии в его составе лишь одного модуля. В случае подключения нескольких модулей повышаются универсальность и гибкость ВС. Компьютер остается работоспособным и при отказе какого-либо модуля, но на время его восстановления ухудшаются характеристики машины (например, нет совмещения операций, уменьшается скорость обработки и т.д.). Любой подключаемый модуль принимает на себя часть функций, улучшая гибкость ВС. Только глубокий и всесторонний контроль позволяет вовремя изменять структуру вычислительной системы и использовать все преимущества модульных структур.
Способы организации мультипроцессорных систем
Для повышения надежности и уменьшения времени обработки данных создают многопроцессорные вычислительные системы. В ранних МВС все подключаемые дополнительные процессоры имели жестко закрепленные функции, как правило, функции каналов ввода-вывода. Более поздние машины (например, CDC 6600) имели один центральный (главный) процессор и несколько подчиненных процессоров, выполняющих достаточно сложные функции, в частности функции по управлению мониторами. Большое распространение получил принцип компоновки МВС из двух и более одинаковых процессоров (UNIVAC 1108, Burroughs 6700, Эльбрус-2 и т. д.).
Существуют различные способы объединения и использования МВС. Рассмотрим наиболее типичные из них:
· самостоятельные системы;
· объединение на уровне планирования заданий;
· объединение с подчиненными процессорами;
· объединение равноправных процессоров.
Они различаются в основном по сложности управления.
Самостоятельные системы
МВС могут быть логически разделены на несколько самостоятельных систем, каждая со своим процессором, ОП и периферийными устройствами. Так, IBM 360/67 была разделена на две самостоятельные ВС по одному процессору, 512 Кб ОП и 8 накопителей на НМД. Очень быстро ее можно преобразовать в одну ВС, имеющую 1024 Кб оперативной памяти, 16 накопителей на НМД, один процессор (второй процессор использовать в качестве "горячего" резерва).
Такая гибкость позволяет эффективно использовать память, ЦП и периферийные устройства, если одна из компонент выходит из строя например, на время их ремонта.
В МВС, построенных по указанному принципу, отсутствует какое бы то ни было совместное планирование на уровне заданий или процессов.
Объединение на уровне планирования заданий
Этот способ – дальнейшее развитие объединения самостоятельных ВС, создание так называемых слабосвязанных систем. Каждый процессор по-прежнему входит в свою подсистему, выполнение также полностью происходит на одной подсистеме, однако подсистема для выполнения задания выбирается в соответствии с принятой дисциплиной.
задание может направляться на наименее
Например, задание может направляться на наименее загруженную подсистему.
Для равномерной загрузки обеих подсистем планирование заданий для них должно быть скоординировано. Для планирования процессов может быть использован либо специализированный процессор, либо некоторая подсистема операционной системы.
Объединение с подчиненными процессорами
Объединение на уровне общего планирования не устраняет временные диспропорции в использовании ОП и ПУ. Для повышения эффективности использования ресурсов применяются сильно связанные МВС. Здесь память и внешние устройства доступны любому процессору, но они распределяются между процессами, а не между процессорами. Назначение процессоров для обслуживания процессов выполняется планировщиком процессов в соответствии с заданной дисциплиной обслуживания, в распоряжении которого имеется уже несколько процессоров.
При построении МВС по принципу объединения с подчиненными процессорами один главный процессор следит за состоянием процессов и руководит работой подчиненных процессоров. Например, для выполнения выбранного процесса планировщик находит свободный процессор и запускает его командой START PROCESSOR (начать вычисление). Подчиненный процессор начнет выполнять программу по указанному адресу памяти. Если в работе подчиненного процессора встретилась особая ситуация (например, необходим ввод-вывод), он подает сигнал главному процессору и ждет дальнейших указаний. Отметим, что один и тот же процесс в разное время может выполняться на разных процессорах.
Для того чтобы было больше процессов в активном состоянии, в оперативную память помещают только некоторую часть адресного пространства процесса.
Объединение равноправных процессоров
Объединение процессоров в МВС по принципу "главный–подчиненный" иногда перегружает главный процессор, за счет чего возникает недоиспользование многих ресурсов. В связи с этим предпочтительнее объединение процессоров в ВС как равноправных. При этом список процессов хранится в общей области памяти, доступной любому процессору.
Каждый раз, когда выполняющийся процесс приостанавливается по какой-нибудь причине (закончился квант времени, ожидание ввода-вывода и т. д.), выполняющий его процессор обращается к списку процессов, изменяет статус текущего процесса и выбирает себе новый процесс для исполнения. Все процессоры придерживаются одной дисциплины обслуживания.
Здесь необходимо обеспечить хорошие средства связи и координации между процессорами. Важную роль при этом играют методы синхронизации процессов, которые мы рассматривали ранее.
Проблема синхронизации возникает в основном вследствие потребности совместного использования ресурсов МВС. Для правильного использования одних и тех же ресурсов совместно исполняющимися процессами необходимы согласованность действий и координация.
Пример взаимодействующей системы. Диплом об образовании может быть выдан только тогда, когда на "отлично", "хорошо" или "удовлетво-рительно" сданы все дисциплины учебного плана. Учебный отдел переводит студента на следующий курс только тогда, когда соответствующие дисциплины за текущий год сданы, деканат выдает учебные ведомости на сдачу экзамена, когда сданы зачеты по соответствующим дисциплинам, а преподаватели принимают экзамены тогда, когда пришли студенты и имеется экзаменационная ведомость.
Такое же взаимодействие процессов необходимо и в МВС. Существуют две проблемы синхронизации, связанные с распределением процессоров и общением между процессами: состязания (гонки), когда параллельно выпол-
няемые процессы настолько чувствительны к порядку их обслуживания, что это может повлиять на результат вычислений, и клинчи (тупики), при которых два соперничающих процесса блокируют друг друга, ибо каждый процесс пытается получить доступ к ресурсу, монопольно занятому другим процессом.
Способы увеличения эффективности и надежности защиты от копирования
Остановимся на существенных недостатках известных программных механизмов защиты от НСК и укажем основные пути и способы увеличения их эффективности и надежности;
· большинство защитных механизмов является пристыковочными и отрабатывает, как правило, один раз перед передачей управления на исполняемый код защищенной программы;
· отсутствует возможность теоретической оценки надежности системы защиты от НСК. Сегодня качество защитных механизмов того или иного пакета оценивается субъективно по времени, которое требуется для снятия защиты с защищенной программы конкретному человеку;
· в большинстве случаев в системах защиты от НСК используются аппаратные заглушки или специальным образом физически помеченные дискеты. Этот метод недостаточно эффективен, так как сейчас хорошо проработаны способы вскрытия такой защиты;
-для аппаратной заглушки используется способ сканирования компьютеров при помощи подключения через "прозрачную" аппаратную заглушку второго компьютера, который отслеживает все передаваемые между компьтером и заглушкой сигналы;
- для физически испорченной дискеты с помощью специальной резидентной программы осуществляется захват соответствующего аппаратного прерывания от устройства и подмена выдаваемых им кодов возврата на требуемые;
· используемые дефектные секторы на дискете всегда можно определить предварительным тестовым считыванием ключевой дискеты, после чего ключевая дискета уже не нужна.
Важным аспектом разработки защитных механизмов является защита их от исследования под отладчиком и с помощью дизассемблеров. Здесь речь идет о принципиально новом подходе к программированию. В отличие от общепринятого наглядного структурного программирования при программировании защитных механизмов нужно говорить об "изощренном" программировании, создающем сложный и запутанный исполняемый модуль. Защищать исполняемый код защитного модуля от дизассемблеров и отладчиков можно путем динамического изменения кода модуля.
Наличие механизмов защиты от дизассемблеров и отладчиков становится первым и наиболее сложным препятствием для "взломщика".
Задача таких механизмов защиты – недопущение или максимально возможное затруднение анализа исполняемого кода программы.
Наиболее распространенные методы скрытия исходного текста программы от стандартных средств дизассемблирования – шифрование и архивация. Непосредственное дизассемблирование защищенных таким способом программ, как правило, не дает нужных результатов. Но так как зашифрованная или архивированная программа чаще всего выполняет обратную операцию (дешифрацию или разархивирование) в первых же командах, на которые передается управление сразу после запуска программы, то для снятия такой защиты необходимо определить лишь момент дешифрации или разархивирования, а затем программными средствами можно "снять" в файл дамп памяти, занимаемой преобразованной программой, и прогнать этот файл через какой-нибудь дизассемблер.
Для усложнения процесса снятия такой защиты можно использовать поэтапную дешифрацию программы. В этом случае программа будет дешифрироваться не сразу в полном объеме, а отдельными участками в несколько этапов, разнесенных по ходу работы программы.
Предварительная архивация кода программы более эффективна по сравнению с шифрованием, так как решает сразу две задачи: уменьшение размера защищаемого модуля и скрытие кода программы от дизассемблера. Файлы, создаваемые с помощью архиваторов, должны быть самораспаковывающимися.
Еще один способ защиты от дизассемблера – использование самогенерируемых кодов. Самогенерируемые коды – это исполняемые коды программы, полученные в результате выполнения некоторого набора арифметических и/или логических операций над определенным, заранее рассчитанным, массивом данных. Самогенерируемые коды вырабатываются непосредственно защищаемой программой, которая по ходу выполнения как бы сама себя "достраивает". Для большей эффективности в качестве массива исходных данных самогенерируемых кодов можно использовать часть исполняемого кода защищаемой программы.
Следующий способ борьбы с дизассемблером – это применение нестандартных приемов выполнения некоторых команд с нарушением общепринятых соглашений.
Среди них:
· использование нестандартной структуры программы;
· скрытые переходы, скрытые вызовы программ и прерываний;
· переходы и вызовы подпрограмм по динамически изменяемым адресам.
Первый способ основан на предположении, что программа, не имеющая стандартной сегментации, может быть неправильно воспринята дизассемблером. В связи с этим защитные механизмы программ чаще всего располагаются в одном сегменте.
Второй способ предполагает использование нестандартной реализации команд типа JMP, CALL, INT, RET, IRET.
Третий способ подразумевает модификацию байтов адреса перехода или вызова подпрограммы.
Не менее сложная задача для "взломщика" – преодолеть недопущение исследования программ стандартными отладчиками.
Эффективным средством против пошагового выполнения программы отладчиком является назначение стека в тело программы. Если в целях недопущения переназначения стека за пределы исполняемого кода в стек помещены данные, необходимые для работы программы, то проблема вскрытия защиты еще более осложняется. Для повышения эффективности метода можно часто менять местоположение стека в программе. Защитные механизмы, которые будут использовать стек, делают практически невозможным применение стандартных отладочных средств.
Бороться с дизассемблерами и отладчиками можно подсчетом и проверкой контрольных сумм определенных участков программы, что позволяет определить, не установлены ли в теле проверяемого участка точки останова. Для установки точки останова отладчик заменяет код байта программы по указанному адресу (предварительно сохранив его) на код вызова прерывания, чем, конечно же, изменяет контрольную сумму программы. Этот факт и использует метод подсчета и проверки контрольных сумм.
Противодействовать средствам дизассемблирования и отладки можно контролируя время выполнения некоторых участков программы. Пользуясь этим методом, необходимо заранее подсчитать по таймеру время выполнения какого-либо участка программы, а затем в процессе работы программы вычислить его заново, сравнивая с эталоном.
Если программа работает под отладчиком, то очевидно, что время выполнения контрольного участка будет значительно большим, чем время его "чистой" работы. Данный метод эффективен в сочетании с механизмом защиты от НСК, имеющим привязку к аппаратным особенностям машины.
Один из способов затруднения работы "взломщика" при анализе работы программы – это метод использования так называемых "пустышек". В качестве их выделяются участки программы достаточно большого объема, производящие некоторые значительные вычисления, но не имеющие никакого отношения к работе программы. В "пустышки" необходимо включать какие-либо фрагменты, которые могли бы заинтересовать "взломщика". Например, это могут быть вызовы таких прерываний, как 13Н, 21Н, 25Н, 26Н, их перехват и т. п.
Принципиально новый подход к защите программного обеспечения от исследований отладочными средствами и дизассемблерами является метод динамического изменения кода исполняемого модуля. Полное изменение исполняемого кода становится возможным благодаря адекватной замене одной или нескольких команд программы другой последовательностью команд без изменения выполняемых программой функций. Например, команда MOV может быть заменена парой команд PUSH и POP, команда CALL – парой PUSH и YMP и т. д. Всегда можно организовать работу программы так, чтобы при каждом ее выполнении происходила замена исполняемых команд на эквивалентные, которые выбирались бы из специальной таблицы эквивалентных команд, хранящейся в определенном месте программы. При этом необходимо постоянно изменять и саму таблицу эквивалентных команд, переставляя в ней местами эквивалентные команды. Можно также внести в таблицу случайный признак модификации таблицы. В результате после каждого выполнения программы ее код будет изменен до неузнаваемости (случайным образом), однако все свои функции программа будет выполнять точно так же, как и раньше. Единственное, что может при этом изменяться – это время выполнения программы.
Страничная организация памяти
Отображение виртуальной памяти в реальную обычно осуществляется с помощью страничной организации памяти.
Виртуальную память в системе со страничной организацией памяти делят на ряд "блоков" фиксированной длины, равной 2k, где k – целое натуральное число. Так как первая ячейка блока N + 1 примыкает к последней ячейке блока N, то программисту факт разбиения ВП на блоки учитывать не требуется.
Оперативная память компьютера делится на "страницы", а вспомогательная – на "сегменты" такого же размера.
Виртуальную память пользователя можно разделить на три типа:
· "активные" блоки, которые содержат программу и данные, используемые в текущий момент;
· "пассивные" блоки, содержащие программу и данные, которые будут использоваться при выполнении программы;
· "мнимые" блоки, к которым не обращаются на протяжении выполнения программы.
Соотношения между первым и вторым типами блоков ВП в процессе выполнения программы изменяются. Третий тип блоков возможен лишь при наличии очень большой области ВП.
Аппарат виртуальной адресации должен отображать виртуальную среду на реальную, причем так, чтобы "активные" блоки находились в оперативной памяти, "пассивные" – по возможности в оперативной или вспомогательной, а мнимые – нигде.
Наиболее удачной из первых ЭВМ со страничной организацией памяти (СОП) является ATLAS (Ferranti). ВП в ней содержит около 2000 блоков по 512 слов. Оперативная память содержит от 32 до 96 страниц тоже по 512 слов. Если ATLAS выполняет процесс, который запрашивает блок из ВП, то некоторым блокам отводятся страницы из оперативной памяти, остальные блоки помещаются на накопитель на магнитном барабане. Фиксированных соотношений между номерами страниц, блоков и сегментов не существует. Динамическое соотношение между сегментами отражено в соответствующей таблице операционной системы.
 |
Преобразование виртуального адреса в реальный происходит с помощью регистров адресов страниц (РАС).
Структура виртуального адреса
Рис. 1.9. Структура регистра адреса страницы
виртуальный адрес в реальный следующим образом: виртуальный адрес сравнивается одновременно с содержимым всех РАС. Единственным сравнимым с ним РАС будет тот, который содержит тот же номер блока и "1" в разряде активности. РАС определяет номер страницы, с которой он связан. Для получения реального адреса памяти к номеру страницы данного РАС присоединяется номер строки из виртуального адреса (ВА). В последовательной интерпретации процесс отображения ВА в реальный можно представить следующей схемой (рис. 1.10).
 |
Рис. 1.10. Схема отображения ВА в реальный адрес
В разряд использования "1" посылается при очередном обращении к данной странице. Через равные промежутки времени содержимое регистра использования сканируется и записывается в определенную ячейку памяти, тем самым создавая статистику использования данной страницы. Подобная статистика полезна при замещении страниц в ОП.
Для создания РАС требуется очень дорогая ассоциативная память, поэтому в mainframe?компьютерах число РАС меньше количества страниц ОП. В них каждому блоку ВП отводится в ОП одна последовательная ячейка памяти, указывающая, где хранится данный блок (ОП, ВнП или нигде). Имеется небольшое количество ассоциативных регистров для РАС (обычно 8 или 16).
Полный процесс отображения ВП в реальную выполняется за три этапа.
1. Если происходит обращение к блоку ВП, который должен отображаться на страницу ОП, РАС для которой является одним из 8 (16) ассоциативных регистров, то процесс отображения выполняется согласно схеме, приведенной на рис. 1.11.
2. Если обращение происходит к блоку ВП, для которого условия п. 1 не выполняются, то номер виртуального блока служит указателем для обращения к таблице блоков (ТБ) в оперативной памяти. Если из ТБ видно, что искомый блок находится в оперативной памяти, то номер страницы также может быть выбран из ТБ.
Если же нужный блок находится во вспомогательной памяти или отсутствует вообще, то происходит прерывание, и тогда переходим к управляющей процедуре (см. п. 3).
3. Обработка прерывания.
Для эффективной работы системы необходимо, чтобы ассоциативные регистры содержали РАС для наиболее часто используемых страниц.
 |
Рис. 1.11. Схема процесса отображения ВА в РА в ЭВМ ATLAS
Основные стратегии замещения страниц, наиболее часто используемые на практике: циклическое изгнание, случайная выборка, наименьшее число обращений с момента последнего прерывания. Результаты экспериментов показали, что ни в одном случае разница в числе обменов, требуемых конкретной задачей при использовании указанных стратегий, не превышала 10 %.
Перенеся концепцию виртуальной памяти на другие компоненты компьютера, мы придем к концепции виртуального компьютера.
Сжатие цветных изображений
Наряду с пакетами Colorsgueeze фирмы Kodak и PicturePress фирмы Storm Technology рассмотрим программу SuperSgueeze, предназначенную для сжатия неподвижных изображений, фирмы Super Mac Technology.
Программа Colorsgueeze является наиболее простой в обращении из программ, предназначенных для сжатия цветных изображений. При использовании этого изделия, реализующего алгоритм JPEG, можно задать один из трех уровней сжатия – высокое, среднее или нормальное – для исходных файлов в 24-битовом формате PICT или TIFF. В результате получаются файлы, размеры которых составляют соответственно около 1/24, 1/13 и 1/6 размера исходного файла.
При использовании Colorsgueeze разницу между исходным и восстановленным после сжатия изображением можно заметить глазом только для самого высокого уровня сжатия.
При среднем уровне сжатия можно различить "брызги" возле острых краев, а при нормальном уровне разницу заметить практически невозможно, даже рассматривая сильно увеличенные фрагменты изображения. Если вы работаете с графикой и сталкиваетесь с необходимостью хранения большого числа цветных и полутоновых изображений, приобретение Colorsgueeze – самый простой способ освободить место на перегруженном жестком диске.
Хотя пакет PicturePress был разработан для конечных пользователей, это настоящий Диснейленд в отношении возможностей сжатия данных (рис.11.3). Этот пакет представляет все те же возможности, что и ряд других, но предназначен для пользователей, немного лучше разбирающихся в обработке изображений. Кроме выбора одного из четырех стандартных уровней сжатия, PicturePress предлагает в специальном диалоговом окне Custom подобрать весовые коэффициенты в таблицах яркости и цветности.
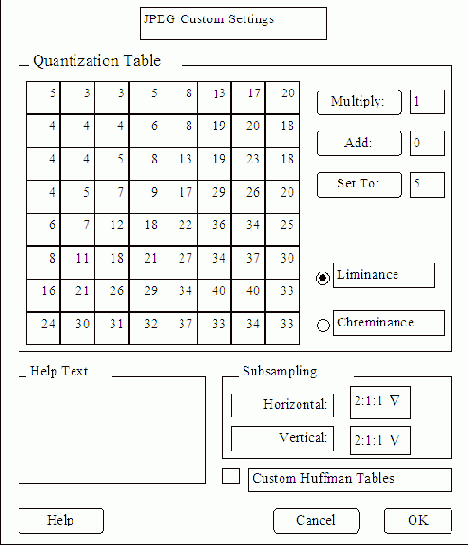 |
Программа PicturePress фирмы Storm Technologies позволяет полностью управлять всеми аспектами сжатия изображения, вплоть до подбора ве-
Рис. 11.3. Возможности пакета PicturePress
совых коэффициентов в таблицах цветности и яркости. Программа позволяет также осуществлять сжатие без потерь и использовать расширения стандар
та JPEG.
Фирма Storm предусмотрела в программе PicturePress несколько интересных расширений по сравнению со стандартом JPEG. Стандарт JPEG++ позволяет задавать разные уровни сжатия для различных частей изображения. Другое расширение стандарта – режим сжатия без потерь, обеспечивающий максимальную экономию места на диске с полным сохранением всей информации (при этом достигается сжатие в 2 – 3 раза). Обычный алгоритм JPEG называется "алгоритмом с потерями", так как при его применении программа намеренно исключает из файла "излишнюю" часть информации.
Фирма Storm Technology выпустила плату PicturePress Accelerator. Плата с интерфейсом NuBus, поставляемая вместе с программой PicturePress, содержит два процессора обработки сигналов, которые выполняют арифметические операции при сжатии. PicturePress автоматически "перепоручает" вычисления процессорам на плате, и таким образом время, требуемое на выполнение сжатия, уменьшается приблизительно в 20 раз. Вычисления все же происходят недостаточно быстро для восстановления видеоизображений. Тем не менее восстановление сжатых образов требует столько же времени, сколько и загрузка с жесткого диска в память исходного несжатого файла или даже меньше.
Фирма C-Cube в свою очередь выпустила систему Compression Master, плата для шины NuBus которой содержит специальную микросхему CL 550, разработанную фирмой и предназначенную для сжатия файлов изображений. В систему входит также утилита DiskDoubler Plus фирмы Salient, используемая для сжатия файлов в форматах PICT и TIFF.
Компания Advent Computer Products также объявила о выпуске платы Neotech Image Compressor на основе микросхемы CL 550.
Сжатие данных
Иногда мы замечаем, что не хватает места на жестком диске. И хотя на страницах компьютерных журналов можно встретить массу всевозможных вариантов решения этой проблемы: быстродействующие дисковые накопители большой емкости, сохранение данных на магнитной ленте, оптические накопители с возможностью перезаписи или с однократной записью (WORM) и другие способы хранения сотен мегабайт информации – всего этого может оказаться недостаточно, если вы работаете со сканером.
Стоит начать считывать сканером цветные или полутоновые изображения размерами в половину машинописной страницы, и диск в 100 Мб окажется заполнен менее чем за час. Более того, размеры файлов, содержащих графические объекты (от 400 Кб до нескольких Мб), таковы, что пересылать коллегам в другой город их можно, только отправив диск по почте. Вы спросите, а как же модем? Модем в этом случае не решает проблемы.
Люди сталкиваются с необходимостью обработки больших объемов данных уже многие годы. Первый пример, который широко известен – спутниковая телеметрия. Представьте себе объем информации, которая содержится в цветном снимке Нептуна и которую необходимо передать на Землю. Теперь проблемы хранения больших объемов информации спустились с небес на Землю, и в поисках решений закрутились колеса коммерции.
Действительно, уже ряд фирм-разработчиков программного обеспечения занимается реализацией на различных компьютерах всевозможных решений проблемы сжатия и восстановления информации. Как только журнал Macworld опубликовал обзор первых попыток в этой области, в распоряжении разработчиков и конечных пользователей появилось несколько новых методик и программ для обработки больших файлов изображений. Это послужило толчком к интенсивным исследованиям в данном направлении.
В настоящее время используют два подхода к сжатию и восстановлению. Первый подход – чисто программный. Для сжатия и восстановления информации применяют либо специализированные автономные программы, либо соответствующие приемы и методы в прикладных программах. Второй подход представляет собой сочетание программных и аппаратных средств. Применение специальных устройств (акселераторов) позволяет сократить время цикла "сжатие–восстановление" с минут до секунд.
Однако сжатие сжатию рознь. Поскольку текстовые файлы, файлы контурных и полутоновых изображений содержат разную информацию, для них требуются и различные архивации.
Таким образом, рассматривая различные схемы сжатия данных, нужно знать, информацию какого типа они подразумевают.
Сжатие документов
Работа телефакса полностью основана на сжатии информации. Если бы образ вашего листа бумаги размером 297 х 210 мм, снятый с разрешением 8 точка/мм, не был сжат, он занял бы 4 Мб памяти, и для его передачи со скоростью 9600 бит/с потребовался бы почти час. На самом деле это занимает значительно меньше времени. Какие же приемы сжатия используют в
факсах?
В самых популярных телефаксах, относящихся к группе III по классификации Международного консультативного комитета по телеграфии и телефонии (МККТТ), используются встроенные статистические таблицы кодирования изображений. В этих таблицах содержится информация не о частоте появления символов и их комбинаций, а о частоте появления черно-белых линий различной длины. Например, в деловой корреспонденции самая распространенная строка – пустая линия длиной 210 мм, поэтому эта строка кодируется короткой последовательностью. Телефакс на приемном конце расшифровывает код и пропускает строку. Более содержательные строки содержат отрезки черного и белого цветов различной длины. Если взглянуть на типичный документ, мы увидим, что число перемен цвета от белого к черному и обратно примерно равно удвоенному числу символов в строке. Сжатая таким образом 80-символьная строка становится набором приблизительно из 160 переходов, а не из 1728 элементов изображения. Если принять во внимание число строк на странице, мы увидим, что это весьма компактная схема кодирования видеоинформации, снятой с разрешением 8 точка/мм (рис. 11.2). Рекомендации МККТТ делают эту схему сжатия еще более эффективной: можно учитывать и взаимосвязи между строками. Предусмотрены, например, короткие кодовые комбинации для "следующая строка такая же, как эта" и "этот фрагмент такой же, как предыдущий", что еще больше повышает эффективность сжатия.
Семизначный код Хемминга
| Десятичное | Простой двоичный | Код Хемминга | |||||||||||||||||||||
| число | код | к | к | к | |||||||||||||||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||||||||||||
| 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | ||||||||||||
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | ||||||||||||
| 3 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | ||||||||||||
| 4 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | ||||||||||||
| 5 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | ||||||||||||
| 6 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | ||||||||||||
| 7 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | ||||||||||||
| 8 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ||||||||||||
| 9 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | ||||||||||||
Пусть передан код числа 6 в виде "0 1 1 0 0 1 1", а приняли в виде "0 1 0 0 0 1 1". Проверочные группы:
| I проверка : | разряды 1, 3, 5, 7 – дает 1 в младший разряд РОШ. | ||
| II проверка : | разряды 2, 3, 6, 7 – дает 0 во второй разряд РОШ. | ||
| III проверка: | разряды 4, 5, 6, 7 – дает 1 в третий разряд РОШ. |
Содержимое РОШ "101", значит ошибка в пятой позиции.
Примечание. В каждый из контрольных разрядов при построении кода Хемминга посылается такое значение, чтобы общее число единиц в его контрольной сумме было четным. РОШ заполняется начиная с младшего разряда.
Вывод. Рост кодового расстояния позволяет увеличить корректирующую способность кода. В то время как d = 2 у кода с проверкой на четность позволяет обнаруживать одиночную ошибку, код Хемминга с d = 3 ис-правлет ее.
Таблица сложения
| ai | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | |||||||||||||||||
| bi | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | |||||||||||||||||
| Pi-1 | 0 | 0 | 0 | 0 | | | | | 1 | 1 | 1 | 1 | |||||||||||||||||
| gi | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | |||||||||||||||||
| Pi | 0 | 0 | 0 | | 1 | 0 | 0 | 0 | 0 | | | |
| Примеры: | 3 | ~ | 0 | 0 | 1 | 1 | 1 | +9 | ~ | 1 | 1 | 0 | 0 | 1 | |||||||||||||||||
| 5 | ~ | 0 | 0 | 1 | 0 | 1 | ?6 | ~ | 0 | 1 | 1 | 1 | 0 | ||||||||||||||||||
| 8 | ~ | 1 | 1 | 0 | 0 | 0 | +3 | ~ | 0 | 0 | 1 | 1 | 1 |
2. Вычитание. Так как a-b = a+b?2b = a+b+b(?2), причем b(?2) – это число b, сдвинутое на один разряд влево, то алгоритм вычитания может быть сформулирован так. Для того чтобы из a вычесть b, необходимо к a прибавить b и прибавить b, сдвинутое на один разряд влево.
Примеры:
| а) | +6 | ~ | 1 | 1 | 0 | 1 | 0 | б) | –5 | ~ | 0 | 1 | 1 | 1 | 1 | в) | –7 | ~ | 0 | 1 | 0 | 0 | 1 | ||||||||||||||||||||||||||||||||
| – | – | – | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| +3 | ~ | 0 | 0 | 1 | 1 | 1 | +4 | ~ | 0 | 0 | 1 | 0 | 0 | –10 | ~ | 0 | 1 | 0 | 1 | 0 | |||||||||||||||||||||||||||||||||||
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | ||||||||||||||||||||||||||||||||||||||||
| 0 | 0 | 1 | 1 | 1 | (+сдвинутое 3) | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | ||||||||||||||||||||||||||||||||||||||||
| 0 | 0 | 0 | 1 | 1 | 1 | = +3 | 0 | 1 | 0 | 1 | 1 | = –9 | 0 | 0 | 0 | 1 | 1 | 1 | = +3 |
3. Умножение Операция умножения осуществляется посредством последовательных сложений и сдвигов.
Примеры.
|
а) |
2 |
~ |
0 |
0 |
1 |
1 |
0 |
б) |
3 |
~ |
0 |
0 |
1 |
1 |
1 |
||||||
|
х |
х |
||||||||||||||||||||
|
5 |
~ |
0 |
0 |
1 |
0 |
1 |
–3 |
~ |
0 |
1 |
1 |
0 |
1 |
||||||||
|
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
||||||||||||
|
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
|||||||||||||
|
0 |
1 |
1 |
1 |
1 |
0 |
= +10 |
0 |
0 |
1 |
1 |
1 |
||||||||||
|
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
= –9 |
4. Деление. Пусть требуется разделить число u на a и получить частное w, т. е. u : a = w.
Введем следующие обозначения:
ak – a, сдвинутое на k разрядов влево;
ui+1=ui – ak,, на каждом шаге алгоритма индекс у ui увеличивается на 1;
N(u) – номер разряда старшей значащей цифры.
Разрядность частного w равна k+1:
(?2)k, (?2)k-1, ..., (?2)0.
Алгоритм деления.
1. Сдвигаем a на k разрядов влево до тех пор, пока старшая значащая цифра у a не станет под старшей значащей цифрой u, таким образом:
a ® ak, т. е. a преобразуется в ak;
u = u0, т. е. u присваивается начальное обозначение u0.
2.
Вычитаем u0 – ak, т. е. u1 = u0+ak+(–2) ak.
3. Если N(ui+1)=N(ak), то записываем "1" в разряд (–2)k
частного и еще раз вычитаем ak.
4. Если N(ui+1)<N(ak), то записываем "1" в разряд (–2)k частного и ak
меняем на ak-1, т. е. сдвигаем ak на 1 разряд вправо и вычитаем ak-1.
5. Если N(ui+1)>N(ak), то записываем "0" в разряд (–2)k
частного, ui+1
заменяем на ui,
ak меняем на ak-1 и производим вычитание.
6. Процесс завершается, если ui+1=0.
Замечание 1. Результат "0" или "1" записывается в разряд частного с весом (–2)k, где k – индекс у a.
Замечание 2. Возможен случай, когда в один и тот же разряд частного записывается несколько значений. Тогда для получения частного необходимо дополнительно выполнить одну операцию сложения.
Пример 1. Пусть необходимо число 14 разделить на число 2, т. е. u0=14, a=2. Тогда 14~10010(–2), 2~110(–2). Для выравнивания делимого и делителя сдвигаем a на два разряда влево, т. е. a® a2 =11000.
Структура частного w:
|
Веса разрядов |
(–2)2 |
(–2)1 |
(–2)0 |
|
|
Частное |
+1 |
+1 |
+1 |
|
|
+1 |
||||
|
110 |
1 |
1 |
= 7 |
Процесс деления:
|
1 |
0 |
0 |
1 |
0 |
u0 |
|||||
|
1 |
1 |
0 |
0 |
0 |
a2 |
|||||
|
Записываем |
1 |
1 |
0 |
0 |
0 |
|||||
|
"1" во второй разряд |
¬ |
0 |
1 |
1 |
0 |
1 |
0 |
u1 |
N(u1)=N(a2) |
|
|
1 |
1 |
0 |
0 |
0 |
a2 |
|||||
|
Записываем |
1 |
1 |
0 |
0 |
0 |
|||||
|
"1" во второй разряд |
¬ |
0 |
0 |
0 |
0 |
1 |
0 |
u2 |
N(u2)<N(a2) |
|
|
1 |
1 |
0 |
0 |
a1 |
||||||
|
Записываем |
1 |
1 |
0 |
0 |
||||||
|
"1" в первый разряд |
¬ |
0 |
0 |
0 |
1 |
1 |
0 |
u3 |
N(u3)<N(a1) |
|
|
1 |
1 |
0 |
a0 |
|||||||
|
Записываем |
1 |
1 |
0 |
|||||||
|
"1" в нулевой разряд |
¬ |
0 |
0 |
0 |
0 |
0 |
0 |
u4 |
N(u4)<N(a0) |
|
Процесс stop, ибо u4=0.
Пример 2. Пусть u0=12, a=2. Тогда 12 ~ 11100(–2), 2 ~ 110(–2).
a® a2 =11000.
Структура частного w:
|
Веса разрядов |
(–2)2 |
(–2)1 |
(–2)0 |
|
|
Частное |
1 |
0 |
1 |
|
|
1 |
||||
|
110 |
1 |
0 |
= 6 |
Процесс деления:
|
1 |
1 |
1 |
0 |
0 |
u0 |
||||||
|
1 |
1 |
0 |
0 |
0 |
a2 |
||||||
|
1 |
1 |
0 |
0 |
0 |
|||||||
|
Записываем |
|||||||||||
|
"1" во второй разряд |
¬ |
0 |
0 |
0 |
1 |
0 |
0 |
u1 |
N(u1)<N(a2) |
||
|
1 |
1 |
0 |
0 |
a1 |
|||||||
|
Записываем |
1 |
1 |
0 |
0 |
|||||||
|
"0" в первый разряд |
¬ |
1 |
1 |
0 |
0 |
0 |
u2 |
N(u2)>N(a1) |
u1 возврат
|
0 |
0 |
1 |
0 |
0 |
u1 |
||||||
|
0 |
1 |
1 |
0 |
a0 |
|||||||
|
Записываем |
0 |
1 |
1 |
0 |
|||||||
|
"1" в нулевой разряд |
¬ |
0 |
0 |
1 |
1 |
0 |
u2’ |
N(u2’)=N(a0) |
|||
|
|
0 |
1 |
1 |
0 |
|
||||||
|
Записываем |
0 |
1 |
1 |
0 |
|||||||
|
"1" в нулевой разряд |
¬ |
0 |
0 |
0 |
0 |
0 |
u3 |
N(u3)<N(a0) |
Процесс окончен, так как u3=0.
Таблица умножения

3. Деление.
Если промежуточное делимое (полученное из остатка путем сноса цифры из делимого) содержит столько же разрядов, сколько делитель, то независимо от того, больше это промежуточное делимое, чем делитель, или нет, в частное пишут "+1", если первые цифры делимого и делителя совпадают, или цифру "
| Пример. | 1 | 0 | 1 | | 0 | | 1 | | | 1 | | | |||||||||||||||||||||
| 1 | 1 | 1 | 0 | 0 | | 0 | 0 | 1 | ||||||||||||||||||||||||
| 1 | | | 1 | | |||||||||||||||||||||||||||||
| 1 | 1 | 1 | | 0 | | 1 | 0 | 0 | 1 | |||||||||||||||||||||||
| 0 | | 0 | | ||||||||||||||||||||||||||||||
| 1 | | | |||||||||||||||||||||||||||||||
| 1 | 1 | |||||||||||||||||||||||||||||||
| 1 | | | |||||||||||||||||||||||||||||||
| 0 | 1 | | | ||||||||||||||||||||||||||||||
| 1 | 1 | |||||||||||||||||||||||||||||||
| 0 |
Замечание. Если есть остаток, т. е. нацело деление не осуществляется, то в частном ставим "," и продолжаем операцию деления дальше.
Преимущества системы:
· нет знакового разряда и знак числа явно не указывается;
· отрицательные числа получаются из равных им по абсолютной величине положительных простой инверсией знаков всех разрядов числа.
Из недостатков можно отметить появление нескольких значений для одного и того же разряда частного.
Эта система кодирования впервые была использована в машине "СЕТУНЬ", разработанной в МГУ (СССР).
Типы параллелизма
Говорят, что задача обладает естественным параллелизмом, если она сводится к операциям над многомерными векторами или над матрицами либо другими аналогичными объектами (например, решетчатыми функциями). Каждый из этих объектов может быть представлен совокупностью чисел, над соответствующими парами которых выполняются идентичные операции. Например, сложение двух векторов состоит из сложения соответствующих компонент векторов. Ясно, что операции могут выполняться параллельно и независимо друг от друга.
Параллелизм множества объектов представляет собой частный случай естественного параллелизма. Задача состоит в обработке информации о различных, но однотипных объектах по одной и той же или почти по одной и той же программе. Здесь сравнительно малый вес занимают так называемые интегральные операции.
Например, вычисление скалярного произведения для n-мерных
векторов

включает два типа операций: попарное произведение компонент векторов и затем "интегральную операцию" (операция над n-мерным вектором) – суммирование между собой всех компонент этого вектора. Исходными операндами интегральных операций являются векторы или функции, или множества объектов, а результатом – число.
Кроме того, при параллелизме множества объектов чаще, чем в общем случае, встречаются ситуации, когда отдельные участки вычислений должны выполняться различно для разных объектов.
Например, надо найти значения функции j (x, y), удовлетворяющей
уравнению

во всех точках внутри некоторой области на плоскости x, y при заданных значениях j (x, y) на границах области.
При решении задачи область покрывается прямоугольной сеткой. Во всех узлах сетки, кроме граничных, задаются некоторые значения функции j (начальное приближение). Для вычисления очередного приближения функции j для каждого узла сетки вычисляется среднее арифметическое из тех значений функции в четырех соседних узлах, которые она имела в предыдущем приближении. Эти вычисления выполняются совершенно одинаково для всех узлов сетки, кроме узлов, расположенных на границе области, где должны всегда сохраняться заданные первоначальные значения (граничные условия).
При параллелизме множества объектов аналогичное положение встречается сравнительно часто.
Основной количественной характеристикой задачи, которую мы желаем решать параллельно, является ранг задачи ® – количество параметров, по которым должна вестись параллельная обработка (например, количество компонент вектора).
Параллелизм независимых ветвей – количество независимых частей (участков, ветвей) задачи, которые при наличии в ВС соответствующих средств могут выполняться параллельно (одновременно одна с другой).
Ветвь программы Y не зависит от ветви X, если:
* между ними нет функциональных связей, т. е. ни одна из входных переменных ветви Y не является выходной переменной ветви X либо какой-нибудь ветви, зависящей от X;
* между ними нет связи по рабочим полям памяти;
* они должны выполняться по разным программам;
* независимы по управлению, т. е. условие выполнения ветви Y не должно зависеть от признаков, вырабатываемых при выполнении ветви X или ветви, от нее зависящей.
Параллелизм смежных операций.
Суть его в следующем.
Если подготовка исходных данных и условий исполнения i-й операции заканчивается при выполнении (i–k)-й операции (где k = 2, 3, 4, ...), то i-ю операцию можно совместить с (i–k + 1)-й, (i–k + 2)-й , ... , (i–1)-й.
На рис. 8.4 продемонстрирован сценарий обработки последовательных и последовательно-параллельных процессов. Из иллюстраций видно, что параллельные ЯП должны иметь средства для явного указания моментов ветвления программ, их объединения, ожидания выполнения некоторого условия, обмена необходимой информацией.
 |
 |
в
Рис.8.4. Сценарий обработки процессов:
а – последовательный процесс; б
– последовательно–параллельный процесс: здесь ® порядок выполнения программы, ¼ – ожидание некоторого условия, – отдельные фрагменты программ;
в – параллельные процессы
Вместе с развитием теории взаимодействующих процессов прослеживаются две концептуальные цепочки проектирования структуры компьютера:
| 1 |
Задача |
® |
последовательный алгоритм |
® |
последовательный язык |
® |
последова-тельное мышление |
® |
последо-вательная ЭВМ |
| 2 |
Задача |
® |
параллель- ный алгоритм |
® |
параллель- ный язык |
® |
нетрадици- онное мышление |
® |
паралель- ные ЭВМ |
Топология локальных сетей
Топология – это конфигурация соединения элементов ЛВС. Основные топологические решения делят, как правило, на два типа:
·
широковещательные, в которых каждый PS (Physical Signalling) передает сигналы, которые могут восприниматься всеми остальными PS. К таким конфигурациям относятся "шина", "дерево" и "звезда с пассивным
центром";
· последовательные, где каждый физический подуровень передает информацию только одному из PS. К таким топологиям относятся "кольцо", "цепочка", "звезда с интеллектуальным центром", "снежинка" и "сетка".

Рис. 3.3. Топология "шина" |
Основной тип конфигурации ЛВС – "шина" (рис. 3.3). Коммуникации между территориально распределенными устройствами в ЛВС в чем-то похожи на коммуникации между модулями в компьютерах: высокая скорость передачи данных, частая смена структуры потока, неравномерная загрузка. Основное их отличие состоит в том, что скорость передачи данных в ЛВС может быть ниже, а длительность "взрывной интенсивности" больше. Наличие высокоскоростного общего канала – наиболее характерная особенность всех новых локальных вычислительных сетей.
Из-за неравномерного характера потока данных последние обычно передаются в форме пакетов, структура которых представлена на рис. 3.4. Так как одно устройство может получать пакеты от нескольких других устройств, то адрес отправителя – неотъемлемая часть структуры пакета.
| Адрес
получателя | Адрес
отправителя | Данные | Контрольная сумма |
Рис. 3.4.
Структура пакета
Возможность широковещательного обращения реализуется резервированием специального адреса получателя для значения "Всем". Предполагается, что пакет с этим адресом будет обрабатываться всеми устройствами.
 |
Эффект от использования шины в ЛВС состоит в том, что внутренние шины компьютера как бы увеличиваются и охватывают целую территорию.
Шины обеспечивают процессору доступ к периферийным устройствам, блокам памяти или другим процессорам, находящимся на значительном расстоянии от ЭВМ, но подключенных к шине (рис. 3.5).
Рис. 3.5. Подключение терминала в ЛВС
Сетевой контроллер управляет использованием шины, а процессор вызовов (ПВ) управляет интерфейсом с терминалами. ПВ отвечает за установку (создание) виртуального канала через сеть к порту ЭВМ и за освобождение этого канала по окончании сеанса связи с терминалом. Во время сеанса ПВ получает данные от терминала, создает пакеты для ЛВС и направляет их сетевому контроллеру, обеспечивающему передачу пакета по шине.
Если, как это принято в UNIX, компьютер реагирует на любой введенный символ, пакет должен приниматься и формироваться для каждого вводимого символа.
Шина обычно представляет собой пассивную среду и поэтому обладает очень высокой надежностью. При использовании конфигурации "шина" возникает ряд проблем:
· каждая станция должна успеть распознать свой адрес за время, меньшее, чем время передачи данных;
· любая станция должна обеспечивать достаточную мощность сигнала, посылаемого в шину, чтобы он мог достичь наиболее удаленных станций;
· так как все станции наблюдают весь трафик, шина принципиально не защищаема, поэтому к секретным данным должны быть применены специальные способы защиты.
 Рис. 3.6. Конфигурация типа "дерево" |
 Рис. 3.7. Конфигурация типа "звезда" |
Широкополосные ЛВС с конфигурацией типа "дерево" обычно имеют корень. Это означает, что сеть обладает особой управляющей позицией, в которой размещаются самые важные компоненты ЛВС. Деревья с корнем уязвимы, так как выход из строя оборудования, размещенного в корне, блокирует работу сети.
Конфигурация типа "звезда" (рис. 3.7) – это дальнейшее развитие конфигурации "дерево с корнем" с ответвлением к каждому подключаемому устройству. Эта топология традиционна в практике обычных коммуникационных систем и дает высокую скорость обмена информацией.
В центре "звезды" размещается коммутирующее устройство, которое должно дублироваться, поскольку является очень важным для жизнедеятельности системы. Иногда в центре "звезды" может находиться пассивный соединитель или активный повторитель (простые и надежные устройства). В сетях ARCNet (фирма Datapoint) используются оба варианта. Эта конфигурация требует значительного расхода кабеля.
Теперь рассмотрим конфигурации последовательного типа. Здесь к передатчикам и приемникам предъявляются более низкие требования, чем в широковещательных конфигурациях.
В конфигурациях типа "кольцо" (рис. 3.8) и "цепочка" (рис. 3.9) для устойчивого функционирования ЛВС требуется постоянная работа всех блоков физической среды PMA (Physical Medium Attachment). Чтобы ослабить это требование, в каждый блок включается реле. В нормальном режиме реле замкнуты и размыкаются в случае потери питания или других неисправностей.
 |
Если передача информации осуществляется по полному кругу, станция-получатель может установить в процессе обработки пакета некий символ, подтверждающий факт получения информации. Например, в ЛВС Cambridge Ring, включающей около 50 станций с кольцом в 2 км, возврат подтверждения осуществляется за 20 – 25 мкс.
 |
 |
Удаление пакетов из сети может осуществляться либо станцией-получателем, либо, по завершении круга, станцией-отправителем.
Существуют специальные программы – "сборщики мусора", которые в случае порчи отдельных станций опознают и уничтожают невостребованные пакеты.
Конфигурация "кольцо" сильно уязвима в отношении отказов, так как выход из строя какого-либо элемента кабеля останавливает работу всей сети. Некоторым выходом является конфигурация "звездообразное кольцо" (рис. 3.10), все "лучи" которой содержат по две линии. Общение между станциями осуществляется через центральный блок (обычно пассивный), который используют для локализации неисправностей.
Достоинство "звездообразного кольца" – простота управления. Отметим некоторые недостатки:
· значительно увеличивается длина кабеля;
· для каждой вновь подключенной машины необходимо прокладывать свой кабель.
Конфигурация типа "цепочка", как и "кольцо", уязвима в отношении отказов и также требует регенерации сигналов каждой станцией. Передача информации через физическую среду здесь должна осуществляться в двух направлениях.
Конфигурация типа "сетка" (рис. 3.11) применяется в глобальных сетях,
 Рис. 3.11. Конфигурация типа "сетка" |
 Рис.3.12. Конфигурация типа "снежинка" |
Конфигурация типа "снежинка" представлена на рис. 3.12.
На сегодняшний день получили распространение различные гибридные конфигурации, вобравшие в себя лучшие свойства ряда перечисленных топологических решений.
Тупик в случае повторно используемых ресурсов
Повторно используемые ресурсы SR (Second hand resource) – это конечное множество одинаковых ресурсов, обладающих следующими свойствами:
* количество единиц ресурсов постоянно;
* каждая единица ресурса или распределена, или доступна только одному процессу;
* процесс может освободить единицу ресурса (или сделать его доступным) при условии, если он ранее получал эту единицу.
Примеры SR-ресурсов: ОП, ВнП, периферийные устройства и, возможно, процессоры, а также такое ПО, как файлы данных, таблицы и "разрешение войти в критическую секцию".
Графы SR. В случае SR-ресурсов граф типа "процесс-ресурс", отображающий состояние OS, называют графом повторно используемых ресурсов. Направленный граф – это пара < N, E >, где N – множество вершин, а E – множество упорядоченных пар (a, b), называемых ребрами, a, bÎN. В случае SR интерпретация графа следующая.
1. Множество N разделено на два непересекающихся класса: P = {p1, p2, ..., pn} – множество вершин для отображения процессов и r = {R1, R2, ..., Rm} – множество вершин для представления ресурсов.
2. Граф является двудольным по отношению к P и r. Каждое ребро e Ì E соединяет вершину из P с вершиной из r. Если e = (pi, Rj), то e – ребро запроса от процесса pi на единицу ресурса Rj. Если же e = (Rj, pi), то e – ребро назначения единицы ресурса Rj процессу pi.
3. Для каждого RiÎr целое неотрицательное число ti, обозначает количество единиц ресурса Ri.
Пусть | (a, b) | – число ребер, направленных от вершины a к вершине b. Тогда система должна работать всегда при следующих ограничениях:
* может быть сделано не более чем ti назначений для Ri, т. е.

* | (Ri, pj) | + | (pj, Ri) | £ ti, для " i, j,
т. е. сумма запросов и распределений для некоторого ресурса не должна превышать количества доступных единиц.
Состояние системы изменяется только в результате запросов, освобождений или приобретений ресурсов одним процессом.
Следует отметить, что процессы являются недетерминированными, так как не существует общего способа узнать заранее, какой ресурс запросит процесс или освободит его в конкретный момент времени.
Чтобы распознать состояние тупика, для каждого процесса необходимо определить, сможет ли он когда-либо снова развиваться. Наиболее благоприятные действия для незаблокированного процесса pi могут представляться сокращением (редукцией) графа SR.
SR-граф сокращается процессом pi через удаление всех ребер, входящих в pi
и выходящих из него. Естественно, процесс pi не должен быть заблокирован и не должен представляться изолированной вершиной в SR-графе. Если процесс интерпретируется как приобретение pi ранее запрошенных ресурсов и затем освобождение всех его ресурсов, тогда pi становится изолированной вершиной.
Граф SR несокращаем, если он не может быть сокращен ни одним процессом. Граф SR полностью сокращаем, если существует последовательность сокращений, которые устраняют все ребра графа. Пример сокращения показан на рис. 7.9.
 |
Теорема. Состояние S есть состояние тупика тогда и только тогда, когда SR-граф в состоянии S не является полностью сокращаемым.
Следствие 1. Если S есть состояние тупика по SR-ресурсам, то по крайней мере два процесса находятся в тупике в S.
Следствие 2. Процесс pi не находится в тупике тогда и только тогда, когда серия сокращений приводит к состоянию, в котором pi
не заблокирован.
Управление процессами в многопроцессорном компьютере
Рассмотрим проекты ВС, включающие три компоненты: среду, процессоры и управление. Отметим, что центральный процессор управляется последовательностью команд, вызываемых откуда-то из среды, а периферийный процессор действует в соответствии с фиксированной, встроенной последовательностью команд.
ПРОЕКТ 1. Предположим, что имеется достаточное количество процессоров различного типа, чтобы обслуживать любой родившийся процесс (рис. 7.3).
 |
Рис. 7.3. Структура МВС (проект 1)
Управление будет состоять из центрального процессора (ЦП), управляемого процедурой, расположенной в памяти. Управляющий процессор соединен линиями связи с другими процессорами, запуская их и получая всю информацию о их состоянии. Обычное состояние ЦП – ожидание какого-нибудь события. При возбуждении управления оно определяет причину возбуждения, обрабатывает ее и, если возможно, запускает этот и/или другой процесс. Закончив обслуживание какого-то устройства, ЦП, прежде чем перейти в режим ожидания, проверяет, пуста ли очередь на обслуживание.
Важной особенностью таких структур является необходимость защиты информации от несанкционированного чтения-записи.
ПРОЕКТ 2. На втором этапе снимем наше предположение о бесконечном количестве процессоров различных типов. Теперь процессы будут выстраиваться в очередь из-за отсутствия свободного процессора. При освобождении очередного процессора управляющий процессор (УП) должен решать, кому его предоставить. Если снабдить УП механизмом прерывания всех процессоров, то УП после сигнала об освободившемся процессоре может перераспределить работу всех процессоров заново. Этот проект оптимальнее предыдущего.
ПРОЕКТ 3. На третьем этапе из-за того, что УП часто простаивает, мы можем функции УП распределять между всеми ЦП. Центральные процессоры, работая в обычном режиме, выполняют какой-то процесс и могут быть прерваны ЦП, работающим в режиме управления. Последний не может быть прерван. Работой всех ЦП в управляющем режиме руководит одна и та же управляющая процедура.
ПРОЕКТ 4. На четвертом этапе предположим, что в управляющем режиме могут работать одновременно несколько ЦП. В этом случае следует принять меры защиты информации при операциях с таблицами состояния процессов.
Возбуждение управляющей процедуры (УП) может происходить одним из следующих способов:
· если процесс, выполняющийся в ЦП, выдает сигнал связи, то этот же ЦП переключается в управляющий режим и выполняет соответствующие действия;
· освободившийся от управления ЦП передает себя какому-нибудь процессу;
· прерывание от периферийного устройства переводит один из ЦП в режим управления. Просмотр всех ЦП происходит поочередно, и если все они находятся в режиме управления, прерывание помещается в очередь.
В целях упрощения реализации можно все прерывания адресовать одному ЦП. Однако при этом увеличивается время обработки каждого события.
Управление процессами в однопроцессорном компьютере
Так как большинство существующих ВС имеет один центральный процессор, то этот случай изучим подробнее.
 |
Рассмотрим абстрактную ВС с ОП, одним ЦП, устройством ввода и устройством печати. Структура такой ВС дана на рис. 7.4.
Рис. 7.4. Структура ВС с одним ЦП
Пусть в исходном состоянии все периферийные устройства (ПУ) находятся в состоянии покоя, а ЦП выполняет процесс Pi, управляемый последовательностью команд. Если в момент ti этот процесс выдает код, возбуждающий процесс в ПУ, то ЦП переходит в управляющий режим и посылает сигнал по линии связи A1, A2 или A3. Затем ЦП возвращается к выполнению своего процесса. По окончании работы одно из ПУ посылает сигнал прерывания по линии Bi, устанавливая тем самым i-й разряд регистра прерываний в соответствующее состояние. ЦП переходит в управляющий режим, анализирует состояние регистра прерываний для опознания ПУ, вызвавшего прерывания,
и выполняет соответствующие действия. До перехода в режим управления ЦП запоминает состояние прерываемого процесса. Если во время обработки прерывания приходит новое прерывание, обработка предыдущего прерывания будет доведена до конца.
На конкретном примере продемонстрируйте семантический
1. Чем различаются понятия "архитектура" и "структура" компьютера?
2. На конкретном примере продемонстрируйте семантический разрыв между современными языками программирования и архитектурными решениями компьютера.
3. Какие пути усовершенствования архитектуры фон Неймана Вам
известны?
4. Разработайте и реализуйте механизм преобразования виртуального адреса в реальный.
5. Разработайте и реализуйте алгоритм управления простейшим технологическим процессом для компьютера, работающего в "замкнутом" цикле.
6. Разработайте алгоритмы взаимодействия основных компонент компьютера с VLIW?архитектурой.
Позаботьтесь о том, чтобы возможность тупика между гостями была исключена.
5. Иногда в системе возникает необходимость передать от процесса к процессу довольно длинное сообщение, например какой-то файл. Обычный аппарат почтовых ящиков здесь, очевидно, был бы неэффективен, поскольку он предусматривает, что сообщение полностью переписывается из одного места оперативной памяти в другое. Укажите способ передачи длинных сообщений при условии, что существует возможность посылать короткие сообщения.
6. Рассмотрим набор процессов, в котором каждому процессу однозначно соответствует целое число. У каждого процесса есть особый участок, в который можно войти только при условии, что сумма всех целых чисел, соответствующих процессам, которые работают в данный момент в своих особых участках, делится на три. Опишите реализацию этих особых участков с помощью семафоров. Дайте краткое описание другой реализации, использующей монитор Хоара. Сравните эти два решения.
7. Рассмотрим сеть вычислительных машин. Опишите аппарат, который можно применить для организации общения между процессами, работающими в различных узлах сети.
что существует возможность построения такого
1. Покажите, что существует возможность построения такого компьютера, что любой заданный алгоритм может быть обработан параллельно.
2. Проанализируйте параметры функционирования вычислительной системы, если комплексирование будет осуществлено на уровне:
· процессоров;
· каналов ввода-вывода;
· оперативной памяти;
· внешней памяти.
3. Промоделируйте работу арифметико-магистральной, командно-магистральной и макромагистральной обработки. Оцените для конкретного класса задач эффективность их конвейерной обработки.
4. Разработайте эффективный (для конкретного класса задач) аппарат тегов и дескрипторов.
и сравните по различным параметрам
1. Проанализируйте особенности RISC? и CISC?архитектур компьютеров.
2. Приведите конкретные примеры воплощения RISC?архитектур в реальных компьютерах.
3. Промоделируйте работу RISC?программы на CISC-компьютере.
4. Проанализируйте и сравните по различным параметрам (быстродействию, памяти, сложности программирования) программы для одно?, двух?, трех? и безадресных компьютеров.
5. Проведите оптимизацию системы команд, если задан конкретный набор решаемых задач.
6. Разработайте микропрограммы выполнения заданных операций для реального компьютера. Проанализируйте целесообразность микропрограм-мной поддержки операций.
7. Разработайте систему команд для компьютера с VLIW?архитектурой.
Опишите функции каждого из уровней
1. Опишите функции каждого из уровней эталонной модели взаимодействия открытых систем.
2. Опишите отличие широковещательных и последовательных конфигураций соединения элементов ЛВС.
3. Сравните по надежности функционирования и скорости передачи информации различные сетевые конфигурации: "дерево", "звезда", "кольцо", "цепочка", "звездообразное кольцо", "сетка", "снежинка".
Поясните семантику основных особенностей процессора
1. Поясните семантику основных особенностей процессора Pentium.
2. Приведите пример масштабируемой процессорной архитектуры.
3. За счет чего достигнута высокая производительность микропроцессора HyperSPARC?
4. Опишите функции конвейера целочисленного устройства процессора PA-RISC.
5. Сравните основные характеристики RISC- и CISC-процессоров.
6. Разработайте алгоритм динамического прогнозирования переходов в программах.
и реализуйте алгоритмы выполнения операций
1. Для способа с симметричным кодированием данных в системе с основанием n=3 разработайте и реализуйте алгоритмы выполнения операций умножения и деления.
2. Для системы кодирования данных с основанием n = –2 разработайте и реализуйте алгоритмы выполнения основных операций (сложение, умноже-ние, деление).
3. Для системы кодирования данных в системе в коде вычетов разработайте и реализуйте алгоритмы основных операций (сложение и умножение).
4. Разработайте и реализуйте алгоритм сравнения чисел в системе в коде вычетов.
5. Разработайте и реализуйте алгоритм поиска ортогональных базисов с единичными весами для системы в коде вычетов.
6. Разработайте алгоритмы выполнения операций сложения и умноже-ния для компьютера с VLIW-архитектурой.
Упражнения
1.Разработайте и реализуйте систему приоритетов между запросами на прерывание и между прерывающими программами.
2. Реализуйте программно алгоритм "последовательного поиска" уровня прерывания.
3. Разработайте несколько нестандартных обработчиков (прерывающих программ) различных запросов прерываний.
4. Разработайте программу распознавания конкретной причины прерывания по его коду для некоторого уровня прерывания.
5. Реализуйте программу сканирования запросов на прерывание и построение адреса входа в прерывающую программу (программу-обработчик).
Рассмотрим набор из восьми частично
1. Рассмотрим набор из восьми частично упорядоченных заданий {A, B, C, D, E, F, G, H}. Задание A должно предшествовать заданиям C, B и E. Задания E и D должны предшествовать заданию F. Задания C и B должны
предшествовать заданию D. Задание F должно предшествовать заданиям
G и H.
a)
Изобразите выполнение этой последовательности заданий в виде программы с помощью элементарных операций "parbegin" и "parend", используя везде, где возможно, параллелизм заданий.
b) Теперь допустим, что добавлено дополнительное ограничение: задание E должно предшествовать заданию C. Можете ли вы по-прежнему найти "максимально использующее параллельность" решение с помощью операций "parbegin" и "parend"?
c) Если бы было разрешено пользоваться семафорами, как бы изменились ваши ответы на вопросы (а) и (б)?
2. Используя защиту памяти, организуйте взаимное исключение между n процессами, у каждого из которых есть один критический участок.
3. Задача о спящем парикмахере (Дейкстра, 1968). Парикмахерская состоит из комнаты ожидания W и комнаты В, в которой стоят парикмахерские кресла. Через раздвижные двери D можно попасть из комнаты В в комнату W, а из комнаты W на улицу. Если парикмахер заходит в комнату W и никого там не обнаруживает, то он идет спать. Если клиент входит в парикмахерскую и находит парикмахера спящим, то он должен его разбудить. В комнате ожидания имеется конечное число стульев n. Запрограммируйте парикмахера и клиентов как процессы. Для синхронизации их работы воспользуйтесь аппаратом пересылки сообщений. Что, если бы были два парикмахера?
4. Пусть дан обеденный стол с пятью стульями и пятью приборами. Около каждого прибора имеется вилка. Чтобы съесть свою порцию спагетти, гостю необходимы две вилки, находящиеся по соседству с его тарелкой. Пусть за столом сидят пятеро гостей, которые попеременно то едят спагетти, то говорят о политике (для разговоров о политике вилок не требуется). Запрограммируйте гостей как набор процессов, используя семафоры для передачи сообщений.
Постройте граф развития заданного процесса
1. Постройте граф развития заданного процесса (например, вычисление некоторого выражения, сортировка слиянием и т. п.).
2. Оцените требуемое минимальное время как функцию n для вычисления выражения
a1 + a2 +…+ an, n³1,
в предположении что:
· параллельно может быть выполнено любое число операций сложения;
· каждая операция (включая выборку операндов и запись результатов) занимает одну единицу времени.
3. Постройте сценарий последовательно-параллельного выполнения алгоритма решения заданной задачи.
Упражнения
1.Опишите подробно алгоритм планирования процессов в какой-нибудь конкретной системе. Связано ли как-либо распределение памяти с алгоритмом планирования?
2.Во что обходится простой центрального процессора в течение 10 % времени в вашей системе? Сравните эти издержки с другими основными расходами на содержание вычислительной машины.
3.Предположим, что у вас есть машина с единственным процессором, причем вытеснения не допускаются. Придумайте алгоритм планирования, который бы минимизировал среднее время ожидания, если потребности в процессорном времени известны заранее. Придумайте другой алгоритм, который будет минимизировать максимальное время ожидания. Если бы были разрешены вытеснения, как это повлияло бы на ваш алгоритм?
4.Во многих теоретических работах принято допущение, что промежутки времени между моментами поступления заданий распределены по экспоненциальному закону. Проделайте эксперимент на своей машине, чтобы проверить эту гипотезу.
5. Рассмотрим множество процессов, в котором взаимное исключение реализовано посредством семафоров. Если процесс Р теряет процессор в момент выполнения критического участка, то все остальные процессы будут блокированы, пока Р не получит процессор вновь. Опишите способ, которым планировщик может избежать остановки процессов в критических участках. Рассмотрите тот же вопрос, используя другие механизмы связи, такие как передача сообщений или мониторы.
и реализуйте алгоритм построения графа
1.Проверьте, удовлетворяет ли требованиям, предъявляемым к языкам параллельного программирования, Р-язык, К-язык, ЯПФ-язык, язык диспозиций, язык ОССАМ.
2. Разработайте и реализуйте алгоритм построения графа информационной зависимости для фрагментов конкретной программы.
3. Разработайте и реализуйте алгоритм преобразования графа
программы при:
· заданном количестве процессоров в вычислительной системе;
· минимальном времени реализации алгоритма при неограниченном количестве процессоров.
4. Разработайте и реализуйте алгоритм наложения информационных связей на связи возможных переходов в графе программы.
5. Разработайте диспозицию D для алгоритма решения конкретной заданной задачи.
6. Выделите и обоснуйте выбор минимально неделимых единиц в программе при ее параллельном выполнении. Осуществите Е-разделение фрагментов программы. Разработайте и реализуйте алгоритм поддержки заданного разбиения в течение некоторого времени.
7. Расширьте заданный язык последовательного программирования средствами описания параллельных процессов и реализуйте их.
Разработайте алгоритм сжатия простого текстового
1. Разработайте n-значный код Хемминга, создайте и реализуйте алгоритм обнаружения и исправления k-кратной ошибки.
2. Разработайте алгоритм сжатия простого текстового документа.
3. Разработайте и реализуйте алгоритм сжатия цветного изображения.
4. Разработайте программу встроенной защиты данных, базирующейся на некоторых специфических особенностях компьютера (временные характеристики, тип микропроцессора, конвейер шины данных и т. п.).
5. Разработайте и реализуйте алгоритм защиты от дизассемблера, используя:
· механизм самогенерируемых кодов;
· метод динамического изменения кода исполняемого модуля.
Вертикальное микропрограммирование
При вертикальном микропрограммировании каждая МИО определяется не состоянием одного разряда, а двоичным кодом, содержащимся в определенном поле МИК. Микрокоманда несколько напоминает формат обычных команд. Отличие состоит в том, что:
· выполняется более элементарное действие – МИО вместо операции;
· адресная часть (в большинстве случаев) определяет не ячейку памяти, а операционный регистр процессора.
 |
Формат МИК при вертикальном микропрограммировании приведен на рис. 2.6.
Рис. 2.6. Формат вертикальной МИК
Поля Р1 и Р2 в адресной части МИК указывают двоичные номера операционных регистров, содержимое которых участвует в одной операции. Одно из полей является одновременно и адресом результата. Таким образом, реализация арифметической или логической МИО, указанной в данной МИК,
может быть выражена формулой
(P1)Ä (P2) ® P1, или (P2) ®P1,
где Ä – символ МИО.
Для МИК обращения к памяти поле P1
указывает регистр, куда принимается информация, а P2 – регистр, содержимое которого является адресом обращения к ЗУ. Указанный формат МИК не единственный.
Каждая МИК выполняет следующие функции:
· указывает выполняемую МИО;
· указывает следующую МИО через задание "следующего адреса";
· задает продолжительность МИК;
· указывает дополнительные действия – контроль и т. д.
Обычно в слове МИК имеются четыре зоны, соответствующие указанным функциям. Вообще говоря, некоторые из зон могут указываться неявно, например выбор очередной МИК может осуществляться из следующей ячейки, продолжительность МИК может быть определена одинаковой для всех МИК и т. д.
Первыми компьютерами с микропрограммным управлением среди отечественных ЭВМ были МИР, НАИРИ, среди зарубежных – IBM/360,
Spectra 70.
Вход в прерывающую программу
Система прерывания программ должна определить допустимый момент прерывания текущей программы и начальный адрес прерывающей программы. Наиболее простыми являются три следующих способа определения допустимого момента прерывания.
Метод помеченного оператора (опорных точек). Суть метода состоит в следующем. В специальные разряды команд, после которых допускается прерывание, записывается определенный знак, разрешающий (например, состояние "1" специального бита команды) или запрещающий (например, состояние "0") прерывание. Тогда вдоль программы можно расставить все опорные точки. Здесь желательно так расставить точки прерывания, чтобы информация, находящаяся в регистрах процессора после выполнения данной команды, дальше не использовалась. Это уменьшает время обслуживания, но увеличивает время реакции.
Покомандный способ. Здесь прерывание допускается после выполнения любой команды. Способ прост в реализации. При этом tр уменьшается, а tобс
увеличивается.
Метод быстрого реагирования. Прерывание допускается во время выполнения любой команды, т.е. после выполнения очередного ее такта. Здесь tр ® min, а tобс ® max, ибо надо запоминать и затем восстанавливать некоторые обычно программно-недоступные элементы (например, счетчик тактов и т. п.).
Из-за простоты и удачного сочетания характеристик прерывания наибольшее распространение получил второй способ, хотя в последних ВС используется и третий. Так, если обнаружено, что адрес операнда сформирован неверно, то целесообразно сразу же прервать выполнение операции, чтобы ошибка не распространилась на другие такты. Это необходимо при мультипрограммной работе, если адресованный операнд в команде принадлежит внешней памяти. Здесь текущая операция не может быть продолжена, пока оперативная память не получит данные из ВнП.
Распознавание начального адреса прерывающей программы можно осуществлять как программным, так и аппаратным способом.
Суть программного распознавания: все линии связи, по которым приходят запросы прерывания, объединяются в схему ИЛИ, формирующую на выходе один и тот же сигнал, который в допустимый момент прерывания поступает в прерывающую программу.
Последняя распознает запросы и разветвляется для их выполнения.
Общая схема работы прерывающей программы приведена на рис. 6.3.
Так как происходит анализ запросов прерывания, то tp и tобс сравнительно велики, что затрудняет приоритетное обслуживание.При аппаратном распознавании причин прерывания каждому источнику прерывания ставится в соответствие свой адрес начала прерывающей программы. Специальная схема при появлении запроса формирует соответствующий адрес перехода к прерывающей программе.
Вход системы прерывания, обладающей способностью формировать собственный адрес начала прерывающей программы, принято называть уровнем прерывания.
Таким образом, система с аппаратным распознаванием причин прерывания может быть названа многоуровневой системой прерывания.
Простейший способ указания начальных адресов состоит в следующем. Каждому уровню присваивается номер и в памяти отводится ячейка, адрес которой, к примеру, равен номеру уровня. В такой ячейке памяти может храниться команда перехода к остальной части прерывающей программы, которая может находиться в любом месте памяти. Набор фиксированных по отношению к своим уровням ячеек памяти образует таблицу входов в прерывающие программы, содержание которых может менять программист.
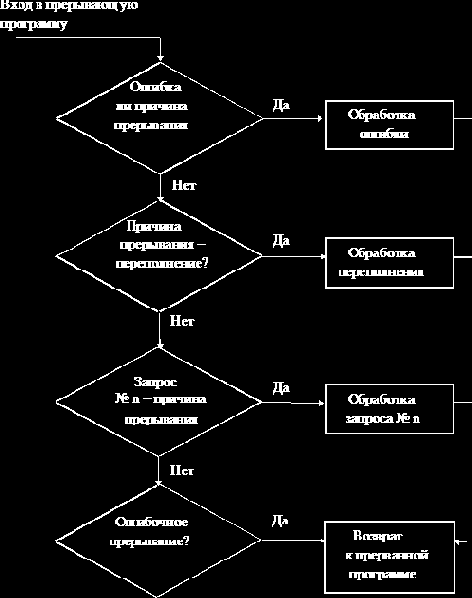 |
Удобный компромисс достигается от сочетания аппаратного и программного методов распознавания причин прерывания. Можно организовать систему, в которой каждый уровень используется для обслуживания нескольких источников прерывания, а физически уровень реализуется в виде некоторого количества прерывающих входов, объединенных схемой ИЛИ. Например, управляющая машина IBM 1800, используя подобный компромисс, имеет 24 уровня прерывания, к каждому из которых может подсоединяться до 16 прерывающих входов. В определенную для данного уровня прерывания ячейку памяти записывается состояние прерывающих входов в момент прерывания.
Вычислительные системы и многомашинные комплексы на базе однопроцессорных ЭВМ
Современные однопроцессорные компьютеры можно комплексировать по следующим четырем уровням:
·
на уровне процессоров для синхронизации и управления;
· на уровне каналов I/О через adapter channel-to-channel (адаптер "канал–канал") – аппаратное устройство, используемое для связи двух каналов, входящих в одну или разные ВС;
· на уровне оперативной памяти (за счет многовходовой памяти);
· на уровне внешней памяти.
Возможны различные сочетания предложенных уровней комплексирования ЭВМ. При этом, как правило, уровень оперативной памяти используется для двухпроцессорных ВС.
Первым экспериментальным двухмашинным комплексом был, пожалуй, комплекс, созданный в 1964 г. из двух ЭВМ SEAC и DESEAC, которые будучи различными по конструкции имели одинаковые системы команд и способы кодирования данных. Комплекс оказался способным решать такие задачи, которые не под силу одной ЭВМ.
В 1966 г. в БССР был создан МК "Минск-222", позволявший соединять от 2 до 16 машин типа "Минск-2(22)" (завод Орджоникидзе г. Минск и СО АН СССР) (рис. 9.1). Связь между машинами осуществлялась через каналы и систему коммутации, образованную из коммутаторов (К), входящих в отдельные машины. Коммутаторы реализуют некоторый набор системных операций, которые позволяют осуществить обмен информацией между данной ЭВМ и ее ближайшим соседом. Все выполняемые системные операции координируются содержимым регистров настройки (РН). Коммутатор ЭВМ и блок системных операций (БОС) составляют элементарную машину. Системные операции позволяют изменять характер взаимодействия ЭВМ за счет изменения содержимого РН, осуществлять обмен информацией и другие
 |
действия. Системные устройства занимают примерно 1 % всего МК.
Рис. 9.1. Структура МК "Минск-222"
"Минск-222" – это система с множественным потоком команд и данных, с низкой степенью связанности и однородной структурой. Межмашинные связи осуществляются с помощью каналов, причем эти связи линейные – между каждой парой соседних ЭВМ.
ВЗАИМОДЕЙСТВИЕ И УПРАВЛЕНИЕ ПРОЦЕССАМИ
Понятие "программа" – недостаточно мощное понятие для описания операционных систем, однако детальное исследование программ позволяет выделить ряд важных концепций, которые проясняют принципы построения операционных систем.
При выполнении программ явно выделяются три объекта:
· последовательность команд или процедура, которая определяет
программу;
· процессор, который выполняет процедуру;
· среда, т. е. та часть окружающего мира, которую процессор может непосредственно воспринимать или изменять.
К среде относятся, например, память, универсальные и управляющие регистры ЭВМ, поскольку они могут и восприниматься, и изменяться
программой.
Можно выделить следующие свойства программы:
* операции, заданные процедурой, выполняются строго последовательно, т. е. следующий шаг не начинается, пока предыдущий полностью не завершится (из определения программы мы исключаем любой процесс, содержащий совмещение операций);
* среда полностью управляется программой, а следовательно, и изменяется только в результате шагов, выполненных программой;
* время выполнения операций, а также временной интервал между выполнением операций не имеют отношения к выполнению программы. Естественно, здесь мы не учитываем, что вся программа должна быть выполнена за разумный интервал времени;
* совершенно не имеет значения, выполняется ли программа целиком на одном процессоре, лишь бы не изменялась среда программы.
Программа в силу указанных свойств предполагает отсутствие внешнего воздействия на ее выполнение. Хорошим приближением такого рода программ являются программы, написанные на языках высокого уровня. Важное свойство таких программ – возможность точного повторения их работы, если только она не имеет доступа к часам реального времени.
Программы, удовлетворяющие указанным свойствам, не могут быть операционными системами, ибо:
* предполагается, что операционная система эффективно использует все ресурсы компьютера, а это требует совмещения операций различных компонент;
* ОС отвечает на поступающие запросы за определенное время, а так как они поступают произвольным образом, то последовательность операций определяется не только самой системой.
Задачи, решаемые виртуальной памятью
Виртуальный адрес– адрес, по которому ссылаются на ячейку виртуальной памяти. Область виртуальных адресов – это множество всех виртуальных адресов.
Использование виртуальной адресации обусловливается следующими обстоятельствами.
1. Однородность области адресов.
Представим себе реальный компьютер без виртуальной памяти. Пусть на нем выполняется параллельно несколько процессов. У каждого процесса будет отдельная локальная среда и каким?то образом распределяемые элементы общей среды. Программисту требуется заранее знать, к каким конкретно частям общей среды его процедура может обращаться. Это затруднительно для пользователей ЭВМ, составляющих свои собственные программы. Отвести наперед фиксированную область среды для каждого процесса невозможно, ибо положение каждой конкретной программы определяется положением всех других программ.
При виртуальной адресации каждый процесс может выполняться в памяти начиная с фиксированной (обычно нулевой) ячейки, имеющей необходимые размеры области ЗУ. Автору безразлично, в каком участке памяти выполняется его программа, так как каждое обращение к виртуальной памяти во время выполнения посредством АПА преобразуется в реальное обращение.
Замечание. АПА работает не во время ассемблирования, а непосредственно во время выполнения обращения.
2. Защита памяти. Общеизвестно, что основная цель защиты памяти состоит в том, чтобы не дать возможности некорректному процессу испортить часть среды, относящуюся к другому процессу. Особенно это важно при защите сред управляющих процедур. Виртуальная адресация здесь используется следующим образом: при каждой ссылке процессом на память проверяется, принадлежит ли она к области виртуальных адресов, отведенных для данного процесса.
3. Изменение структуры памяти.
При проектировании больших программ структура памяти машины с малой ОП явно усложняет проектируемую программу. Применение виртуальной адресации позволяет преобразовать память на разных ступенях иерархии в "одноуровневую память" с одинаковым доступом ко всем элементам и отобразить ее на реальную память.
Для удовлетворения пунктов 1–3 требуется аппарат "страничной" организации памяти, для пунктов 1, 2 достаточно иметь регистры "настройки": регистры "базы" и "границы".
Здесь: – переход; O – место
Иногда функцию инцидентности F как компоненту сети Петри представляют в виде двух функций: PRE: P´T ®
í0,1ý, POST : T´P> {0,1}.
Из вершины pÎP в вершину tÎT дуга ведет тогда и только тогда, когда PRE(p, t) = 1, а из вершины tÎT в вершину pÎP тогда и только тогда, когда POST (t, p) = 1. Разметка изображается точками в местах.
Разметка сети позволяет описывать ее состояние. Функционирование сети Петри происходит посредством перехода от одной разметки к другой. Изменение разметок происходит вследствие срабатывания переходов. Переход t может сработать, если для него выполнено условие
"p (M(p) – PRE (p, t) ? 0),
где M – текущая разметка. В нашем примере такому условию удовлетворяют переходы t1 и t2. Срабатывание перехода t приводит к изменению разметки: входные места перехода теряют по одной метке, а выходные – получают по одной метке.
Разметку M сети называют достижимой из M0, если существует последовательность срабатываний переходов, в результате которой разметка сети из M0 переходит в M. Рассмотрим формальную модель программ, в основу которой положено специальное расширение сетей Петри – ПМ-сети.
Обобщенная сеть Петри – это набор (P, T, F, H, M0), где P – множество мест; T – множество переходов; F: P´T®N?{0} и H: T´P®N?{0} – функция инцидентности; M0: P®N?{0} – начальная разметка; N – множество натуральных чисел.
Определим для сетей два типа меток: плюс-метки и минус-метки, соответственно расширим область значений функции разметки: M: P®{ …, -1, 0, 1, …}. Обозначим P+ = {p| M(p)>0}, P- = {p| M (p) < 0}. Введем функционал (предикатный функционал) C: H?F®{+, -}, т. е. каждая дуга сети помечается либо плюсом, либо минусом.
Изменим в соответствии с введенными дополнениями и правила функционирования сетей. Будем считать, что одновременно в месте не могут находиться плюс- и минус-метки. В связи с этим определим операцию аннигиляции меток, т. е. операцию одновременного уничтожения равного количества плюс- и минус-меток для одного и того же места.
Будем использовать следующие обозначения: *t = {p| F (p, t)>0}; t*=
= {p| H (t, p)>0}; *t+ (*t-) – множество таких мест, что существуют дуги из этих мест в переход и эти дуги помечены плюсом (минусом); t+*(t-*) – множество таких мест, что существуют дуги из перехода t в эти места и эти дуги помечены плюсом (минусом). Отметим, что *t+?*t- = Ø для любого t, т. е. если из места в переход существуют кратные дуги, то они должны быть помечены одним и тем же символом. Иначе из-за операции аннигиляции невозможно включение перехода t и он будет заведомо недостижим от любой начальной разметки сети.
Переход t может сработать, если для него выполнены условия:
а) для "pÎ*t+ имеет место M(p)?F(p, t),
б) для "pÎ*t- имеет место M(p)<0 и |M(p)|?F(p, t).
Срабатывание перехода t приводит к изменению разметки M на M/ по правилам:
1) если pÎt-*, то M/(p) = M(p) – H(t, p);
2) если pÎt+*, то M/(p) = M(p) + H(t, p);
3) если pÎ*t-, то M/(p) = M (p) + F(p, t);
4) если pÎ*t+, то M/(p) = M (p) – F(p, t);
5) если pÎ *t?t*, то M/(p) = M(p).
Сети, введенные выше, назовем ПМ-сетями. Проведем сравнительный анализ выразительных способностей ПМ-сетей с известными расширениями сетей Петри. Сравним семейства формальных языков, генерируемых различными классами сетей Петри.
Будем говорить, что разметка M/ достижима из M в результате последовательности срабатываний t = t1, t2 … tk, где tiÎT, 1 ? i ? k, если существует последовательность следующих друг за другом разметок:


L(N) = {?ÎT*|$M,

где T* – множество всевозможных цепочек, составленных из символов алфавита T.
Введем помечающую функцию s: T®SÈ{l}, где å – некоторый алфавит, а l – пустое слово. Функция s
легко обобщается на последовательности срабатываний gt:

Ll(N) = {s (g)|gÎL(N)} называется l-языком сети N.
Сети N1 и N2
называются эквивалентными (N1~N2), если Ll (N1) = Ll(N2). Говорят, что класс сетей ?1 мощнее класса ?2 (?2 Í?1), если для любой N2Î?2 существует N1Î?1 и N1~N2. Классы сетей ?1 и ?2 называются эквивалентными (?1~?2), если ?1Í?2 и ? 2Í?1.
Известно, что структурированные сети, приоритетные сети, сети с переключателями и дизъюнктивными правилами, ингибиторные сети эквивалентны. Докажем, что введенные здесь ПМ-сети обладают не меньшими выразительными способностями, чем отмеченные выше классы. Обозначим ?(И) – класс ингибиторных сетей, ?(ПМ) – класс ПМ-сетей.
Теорема. Имеет место следующее значение ?(И)Í?(ПМ).
Для доказательства необходимо показать, что по любой N1Î?(И) можно построить эквивалентную сеть N2Î?(ПМ).
Пусть N1 – ингибиторная сеть с начальной разметкой M0 и помечающей функцией s. Разобъем сеть N1 на n фрагментов (n – число мест в сети N1), каждый из которых включает одно место и переходы, инцидентные данному месту. Обозначим pk = {t|H(t, p)>0};


и данными переходами.
Для каждого фрагмента ингибиторной сети будем строить эквивалентный фрагмент ПМ-сети. Если исходный фрагмент не содержит ингибиторных дуг, то он остается без изменений. Если же некоторый k-й фрагмент включает хотя бы одну ингибиторную дугу, то выполняются следующие построения. В новом фрагменте будут соответственно те же переходы и то же место, что и в исходном, по-другому задаются связи между ними и разметка места.
1. Если в исходном фрагменте переход tÎ*pk, то в новом фрагменте каждой исходной дуге из t в pk будут соответствовать две дуги, ведущие из t в pk и помеченные плюсом.
2. Если в исходном фрагменте переход

3. Если в исходном фрагменте переход

4.Если в исходном фрагменте M (pk) = m, то в новом фрагменте M(pk) = = 2m-1.
 |
Рис. 8.7. Ингибиторная сеть и ПМ-сеть
После того как для каждого фрагмента ингибиторной сети построен эквивалентный фрагмент ПМ-сети, остается осуществить сочленение полученных фрагментов по переходам, помеченным одинаковыми символами. Такое построение производится на основе операции наложения. Полученное объединение фрагментов и будет являться ПМ-сетью N2, эквивалентной N1.
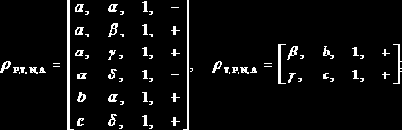 |

= (Ps, Ts,Fs, Hs, M0, s
), где


Назовем сi и di, 1 ? i ? n, выходными местами кортежа R-фрагментов. На множестве R-фрагментов кортежа можно задавать отношения, аналоги которых существуют в реальных программах. Эти отношения задаются в кортежах путем комбинаций дополнительных плюс- и минус-дуг, соединяющих переходы и места различных фрагментов. Пример одного из таких отношений будет рассмотрен ниже.
Будем считать, что объединение кортежей друг с другом может осуществляться лишь с помощью операции à, которая определяется следующим образом. Пусть S1 = (P1, T1, F1, H1, M0,1) и S2 = (P2, T2, F2, H2, M0,2) кортежа R-фрагментов, тогда S1à S2 – сеть S1 = (P/, T/, F/, H/, M/0), у которой P/ = P1?P2, T/ = T1?T2, H/ = H1?H2, F/ – есть объединение F1, F2 и дополнительных плюс-дуг, выходящих из некоторого подмножества выходных мест кортежа S1 и входящих во входной переход кортежа S2. Выбор подмножества выходных мест существенно зависит от отношений, задаваемых на множестве R-фрагментов. Операция à аналогично определяется для кортежа и просто перехода. Переходы, добавленные в СПМ-сеть посредством операции à, называем висячими.
СПМ-сеть определяется следующим образом:
1) кортеж R-фрагментов есть СПМ- сеть;
2) сеть, полученная из СПМ-сети добавлением к одному из составляющих ее кортежей либо кортежа, либо перехода, посредством операции à, является СПМ-сетью.
Сети Петри и их модификации могут успешно применяться в теории параллельного программирования как семантические модели структур параллельных программ, в частности для отображения безусловного уровня управления. СПМ-сети послужили основой для построения модели параллельных программ с большим количеством условных операторов. Безусловный уровень управления в такой модели может быть описан непосредственно СПМ-сетями, условный уровень задается специальными операторами-распознавателями. Каждому R-фрагменту приписан один оператор-распознаватель, связанный плюс-дугой с переходом b и минус-дугой с переходом g (смотрите определение R-фрагмента). Плюс-дуга соответствует выработке оператором-распознавателем значения "истина", минус-дуга соответствует значению "ложь". Таким образом, переход b (переход g ) может сработать, если место a содержит плюс-метку и оператор-распознаватель выработал значение "истина" ("ложь").
Информационно операторы-распознаватели, приписанные R-фрагмен-там одного кортежа, независимы и поэтому могут включаться асинхронно, что и обеспечивается структурой кортежа. Тем не менее в программах может иметь место отношение логической подчиненности этих операторов-распознавателей. Из-за этого при параллельном выполнении кортежа операторов-распознавателей срабатывание одних операторов-распознавателей с определенными результатами может сделать несущественными результаты срабатываний других операторов-распознавателей. Поэтому выполнение последних необходимо либо прервать, либо запретить их включение, если они еще не включались, либо уничтожить результаты их работы, если они уже выполнялись. Это обеспечивается заданием дополнительных плюс- и минус-дуг, соединяющих соответствующие переходы и места различных фрагментов.
Например, пусть выполнение оператора-распознавателя, приписанного Ri-фрагменту, несущественно, если оператор-распознаватель, приписанный Rj-фрагменту, выработал значение "истина". Тогда соединяем переход bj минус-дугой с местом ai, что позволит не включать фрагмент Ri (так как произойдет аннигиляция плюс- и минус-меток), либо, если он уже сработал, сделать разметку его выходных мест нулевой (так как сработает либо переход ai, либо переход di). Таким образом, в данном случае отношение логической подчиненности операторов-распознавателей задает соответственно и отношение на множестве R-фрагментов кортежа.
Подводя итог приведенным выше рассуждениям, можно определить модель параллельных программ как набор R = (W, S, Y, L), где
1) W – множество ячеек памяти (переменных);
2) S – безусловный уровень управления модели, представленный СПМ-сетью с заданными, если необходимо, отношениями (в частности, логической подчиненности) на множествах R-фрагментов кортежей. (Отметим, что места СПМ-сетей можно рассматривать как ячейки памяти специального вида – управляющей памяти W/, причем можно считать, что W/?W = Æ);
3) g – условный уровень управления, заданный операторами-распознавателями, являющимися предикатными термами над W; при этом операторы-распознаватели можно рассматривать как связующее звено между памятью W и управляющей памятью W/
, поскольку входными переменными для них являются элементы из из W, а свои результаты они помещают в W/.
4) L – множество цепочек операторов-преобразователей. Входные и выходные переменные операторов-преобразователей принадлежат множеству W. Мощность множества L равна числу висячих переходов в соответствующей СПМ-сети, поскольку каждому висячему переходу приписывается
одна цепочка операторов-преобразователей из L.
