Монитор Хоара
Монитор – это набор процедур и информационных структур, которыми процессы пользуются в режиме разделения, причем в фиксированный момент времени им может пользоваться только один процесс.
Отличительная особенность монитора в том, что в его распоряжении находится некоторая специальная информация, предназначенная для общего пользования, но доступ к ней можно получить только при обращении к этому монитору.
Монитор не является процессом, это пассивный объект, который приходит в активное состояние только тогда, когда какой-то объект обращается к нему за услугами. Часто монитор сравнивают с запертой комнатой, от которой имеется только один ключ. Услугами этой комнаты может воспользоваться только тот, у кого есть ключ. При этом процессу запрещается оставаться там сколь угодно долго. Другой процесс должен ждать до тех пор, пока первый не выйдет из нее и передаст ключ.
В качестве примера программы-монитора может выступать планировщик ресурсов. Действительно, каждому процессу когда-нибудь понадобятся ресурсы и он будет обращаться к планировщику. Но планировщик одновременно может обслуживать только один ресурс.
Иногда монитор задерживает обратившийся к нему процесс. Это происходит, например, в случае обращения за занятым ресурсом. Монитор блокирует процесс с помощью команды "ЖДАТЬ", а в случае освобождения ресурса выдает команду "СИГНАЛ". При этом освободившийся ресурс предоставляется одному из ожидавших его процессов вместе с разрешением на продолжение работы. Управление передается команде монитора, непосредственно следующей за операцией "ЖДАТЬ".
Мониторы более гибки, чем семафоры. В форме мониторов сравнительно легко можно реализовать различные синхронизирующие примитивы, в частности семафоры и почтовые ящики. Кроме того, мониторы позволяют нескольким процессам совместно использовать программу, представляющую собой критический участок.
Вычислим номера ячеек, в которых записаны адреса входов во все восемь блоков.
1) 000 |
2) 001 |
3) 010 |
4) 011 |
5) 100 |
6) 101 |
7) 110 |
8) 111 |
||||||||||||||||||||
000 |
001 |
010 |
011 |
100 |
101 |
110 |
111 |
||||||||||||||||||||
000 |
011 |
110 |
101 |
1100 |
11111 |
1010 |
1001 |
||||||||||||||||||||
N=0 |
N=3 |
N=6 |
N=5 |
N=12 |
N=15 |
N=10 |
N=9 |
||||||||||||||||||||
N ячейки
<
Вычислим номера ячеек, в которых записаны адреса входов во все восемь блоков.
1) 000 |
2) 001 |
3) 010 |
4) 011 |
5) 100 |
6) 101 |
7) 110 |
8) 111 |
||||||||||||||||||||
000 |
001 |
010 |
011 |
100 |
101 |
110 |
111 |
||||||||||||||||||||
000 |
011 |
110 |
101 |
1100 |
11111 |
1010 |
1001 |
||||||||||||||||||||
N=0 |
N=3 |
N=6 |
N=5 |
N=12 |
N=15 |
N=10 |
N=9 |
||||||||||||||||||||
Направления повышения эффективности компьютеров
Как было отмечено выше, общие подходы к повышению производительности вычислительной техники развиваются в двух основных направлениях: увеличение быстродействия элементной базы и развитие существующих и создание новых архитектур вычислительных средств.
Первый подход ограничен параметрами физических элементов, связанных со скоростью распространения сигнала по физическим линиям связи. Другой путь требует тщательного исследования механизма взаимодействия процессов в системах параллельного действия (СПД), в частности и в однопроцессорных системах при мультиобработке, и на его основе совершенствования логики вычислений, в том числе развития методов параллельной обработки информации.
СПД создаются путем объединения отдельных компонент (модулей) в единую обрабатывающую среду. В качестве компонент такой среды могут выступать вычислительные системы (ВС), отдельные ЭВМ, процессоры общего и специального назначения, транспьютеры ит. д.
Одной из разновидностей высокопроизводительных вычислительных систем (ВВС) являются однородные ВС, где в качестве функциональных модулей используются блоки, имеющие архитектуру ЭВМ. Положенные в их основу такие принципы, как:
· параллельность выполнения большого количества операций,
· автоматическая настраиваемость структуры на решаемую задачу,
· конструктивная однородность,
длительное время использовались различными разработчиками ВВС с целью достичь сколь угодно большой производительности, гибкости в управлении, надежности и высокой технологичности в изготовлении.
Теперь стало ясно, что разумной альтернативой последовательной обработки является создание архитектур, базирующихся на параллельной обработке алгоритма и распределенности данных по многим процессорам.
На сегодня установилась классификация ВВС, базирующихся на порядке поступления потоков команд и данных на обработку. Их структуры образуют следующие четыре класса:
* одиночный поток команд – одиночный поток данных (SISD).
Сюда относятся типичные машины последовательного действия;
* одиночный поток команд – множественный поток данных (SIMD). Это матричные и ассоциативные структуры;
* множественный поток команд – одиночный поток данных (MISD). Он включает конвейерные или магистральные структуры;
* множественный поток команд – множественный поток данных (MIMD). К этому классу принадлежат структуры, включающие несколько процессоров, одновременно выполняющих различные фрагменты одной и той же программы.
На сегодняшний день разработан и функционирует целый спектр ВВС, начиная от машин серии ЕС, ПС, Эльбрус, имеющих производительность от нескольких миллионов и сотен миллионов операций в секунду, до многопроцессорной ВС Suprenum, включающей 256 процессорных узлов общего назначения с максимальной производительностью 5 млрд операций в секунду (оп/с) и машин типа Teraflop-1 с пиковой производительностью 1000 млрд оп/с.
Создание ВВС, промышленный выпуск транспьютеров позволяют формировать единые среды, разрешающие проблему параллельной обработки информации для массового пользователя.
Опыт разработки и исследования конвейерной архитектуры от ЭВМ Star 100, IBM 360/91, Cyber 205 до ETA Systems, Cray Research и ряда других показывает многообразие структурных решений, способствующих значительному увеличению максимальной производительности. Однако существенное увеличение быстродействия на конвейерных ВВС может быть достигнуто лишь для задач, векторизуемых более чем на 90 %. Векторизация в реальных задачах не превышает 70 %. Выход из этой ситуации, как правило, ищут в двух направлениях. С одной стороны, акцентируется внимание на повышении мощности скалярных вычислений в векторных ВВС.
Здесь показательны, например, разработки фирмы Cray Research. Так, если первые ее модели Cray X-HP, Cray-2 имели до четырех процессоров, то Cray-3 содержала 16 процессоров, а Cray-4 уже 64.
Интерес представляет суперкомпьютер Cray T3E/1200
– масштабируемая массово-параллельная система, состоящая из отдельных процессорных элементов (РЕ), которую производит компания Cray Research, подразделение Silicon Graphics. В нем используются процессоры DECchip (DEC Alpha EV5) с тактовой частотой 600 MГц и пиковой производительностью 1200Mflops. СистемыT3E масштабируются до нескольких тысяч процессоров. Каждый процессорный элемент располагает своей памятью (DRAM) объемом от 256Mб до 2Гб. При этом память системы глобально адресуема. Процессорные элементы связаны высокопроизводительной сетью с топологией трехмерного тора и двунаправленными каналами. Скорость обмена достигает 480 Mб/c в каждом направлении. Поддерживается явное параллельное программирование через пакет Cray Message Passing Toolkit (MPT), включающий высокопроизводительные реализации интерфейсов MPI и PVM, а также библиотеку Shmem разработки Cray Research для работы параллельных процессов над общей памятью. Для Фортран-программ возможно также неявное распараллеливание в моделях CRAFT и HPF. Среда разработки включает также набор визуальных средств для анализа и отладки параллельных программ. Компьютер работает под управлением операционной системы UNICOS/mk.
С другой стороны, ищут альтернативный подход к разработке конвейерной архитектуры, так называемое микромультипрограммирование. Предложена альтернативная теория конвейеризации Context Flow, где вычисления рассматриваются как набор логических преобразований на контекстах процессов. Этот подход дает лучшее соотношение производительность–стоимость, чем обычные конвейеры.
При разработке параллельных компьютеров существенную трудность представляет решение задачи разбиения алгоритмов на значительные по объему вычислений фрагменты, которые были бы информационно независимы.
Большое затруднение здесь вызывают условные переходы, встречающиеся через каждые 8–10 команд. Решением проблемы условных переходов стал компилятор планирования трассы Trace Scheduling (фирма Multiflow Computer), который позволяет прогнозировать направление переходов в программах для решения инженерно-технических задач на основе аппарата статистического анализа.
Производство ВВС стимулировало создание теории параллельных вычислений и разработку параллельных алгоритмов решения задач. Теория параллельных вычислений позволяет оценить предельные возможности ВВС и разработать методы адаптации параллельных алгоритмов на конкретные архитектуры параллельных компьютеров.
В последние годы интерес к параллельным вычислениям концентрируется на осмыслении общих закономерностей разработки параллельных алгоритмов.
Работы в указанной области условно можно разбить на три основных направления.
1. Разработка моделей параллельных вычислений и установление соотношений между ними, определение класса задач, допускающих эффективное распараллеливание (класс NC), и класса задач, наиболее трудных для распараллеливания (P-полных задач).
2. Разработка общих методов построения параллельных алгоритмов и распараллеливание последовательных алгоритмов. Исследование сложности параллельных алгоритмов в различных областях применений.
3. Создание методов и средств отображения параллельных алгоритмов на реальные параллельные архитектуры.
Интуитивное представление о параллельных вычислениях имеет много формализаций, которые реализуются в различных моделях параллельных вычислений. Среди них:
* параллельная машина с произвольным доступом к памяти;
* машины Тьюринга;
* машины с управлением потоком данных (data flow);
* модели, базирующиеся на сетях Петри и схемах синхронизации, и т. д.
Предлагаемые модели благодаря абстрагированию от многих специфических особенностей параллельных архитектур позволяют сравнительно просто реализовать параллельные алгоритмы.
Исследуются вопросы сложности моделирования одних типов моделей на других и вычислительные возможности моделей в зависимости от вводимых ограничений на разрешение конфликта по одновременной записи и чтению. Известны исследования о вычислительной силе различных моделей при ограничении на размер используемой памяти и количество процессоров.
В теории параллельных вычислений имеется ряд открытых проблем. Основная из них – это возможность эффективного распараллеливания алгоритмов. Она формулируется как соотношение классов NC и P. Это вопрос такой же важности, как соотношение классов P и NP в теории сложности вычислений, и очень далек от своего решения, ибо предполагает получение сверхполилогарифмических оценок параллельной сложности решения некоторых задач из класса P.
К конкретным задачам, для которых неизвестна их принадлежность ни к NC, ни к P-классу, относится, например, задача возведения целого в степень: для заданных n-битовых чисел a, b
и m вычислить ab mod m.
Нейрокомпьютеры
При проектировании любого вычислительного устройства всегда стоит вопрос о классе задач, который наиболее эффективно будет на нем решен.
Что касается нейрокомпьютеров, то это не только неформализуемые или плохо формализуемые задачи, в алгоритм решения которых включается процесс обучения на реальном экспериментальном материале (как правило, задачи распознавания образов), но и задачи с естественным параллелизмом (например, обработка изображений).
Нейрокомпьютерные архитектуры в будущем будут завоевывать все большее место среди других архитектур. Уже сегодня существенно расширяется интерес к общематематическим задачам, решаемым в нейросетевом компьютерном базисе. Среди таких задач:
·
линейные и нелинейные алгебраические уравнения;
· системы нелинейных дифференциальных уравнений;
· уравнения в частных производных;
· линейное и нелинейное программирование.
На сегодняшний день в основном сформировались три раздела нейроматематики: общий, прикладной и специальный.
Нейроматематика – это раздел вычислительной математики, связанный с решением задач с помощью алгоритмов, представимых в нейросетевом логическом базисе.
Раздел общей нейроматематики представляет собой решение общих математических задач в нейросетевом логическом базисе с целью исключить потери на разработку специальных алгоритмов и повысить эффективность их решения. Даже, казалось бы, такие простые задачи, как извлечение корня, сложение и умножение чисел, пытаются решать на нейрокомпьютерах, ибо при их ориентации на нейросетевую физическую реализацию алгоритмы можно выполнить значительно эффективнее, чем на известных булевских элементах.
Прикладная нейроматематика включает задачи, в принципе не решаемые известными типами вычислительных устройств. Примерами таких задач являются:
* контроль кредитных карточек (диагностика фактической принадлежности карточки владельцу с настройкой нейронной сети в пространстве признаков покупаемых товаров);
* система скрытого обнаружения веществ с помощью устройств на базе типовых нейронов и нейрокомпьютера на заказных цифровых нейрочипах, что необычайно важно в аэропортах при обнаружении наркотиков, ядерных материалов и т. д.
Сюда можно отнести задачи обработки изображений (сжатие с большим коэффициентом с последующим восстановлением, выделение на изображении движущихся целей и т. д.), задачи обработки сигналов (определение координат цели, прогнозирование надежности электродвигателей и т. д.).
Специальная нейроматематика включает задачи повышения качества и увеличения динамических свойств изображения в системах виртуальной реальности, прямые и обратные задачи в системах защиты информации и т. д.
Логической основой нейрокомпьютеров является теория нейронных сетей (НС). Нейронная сеть – это сеть с конечным числом слов из однотипных элементов – аналогов нейронов с различными типами связей между слоями нейронов.
Основные преимущества НС как логического базиса алгоритмов реше-
ния сложных задач являются:
· инвариантность методов синтеза НС по отношению к размерности пространства признаков и размеров НС;
· отказоустойчивость в смысле монотонного, а не катастрофического изменения качества решения задачи в зависимости от числа вышедших из строя элементов.
Развитие технологий в микроэлектронике позволяет реализовать новые идеи в архитектурных решениях. В середине 70-х годов появление СИС породило ЭВМ с архитектурой SIMD, в начале 80-х появление БИС позволило создать транспьютер и компьютер с архитектурой MIMD. Во второй половине 80-х годов, когда появилась возможность в одном кристалле аппаратной реализации каскадируемого фрагмента НС с настраиваемыми или фиксированными коэффициентами стали активно проектироваться нейрокомпьютеры.
Определение нейрокомпьютера наиболее реально давать, рассматривая его с точки зрения конкретной области применения.
С точки зрения вычислительной техники нейрокомпьютер –это вычислительная система с архитектурой MSIMD, в которой реализованы следующие принципиальные решения:
• упрощен до уровня нейрона процессорный элемент однородной структуры;
• резко усложнены связи между элементами;
• программирование вычислительной структуры перенесено на изменение весовых связей между процессорными элементами.
Наиболее общее определение нейрокомпьютера может быть следующим.
Нейрокомпьютер – это вычислительная система с архитектурой программного и аппаратного обеспечения, адекватной выполнению алгоритмов, представленных в нейросетевом логическом базисе.
Некоторые модели параллельных программ
Развитие точных методов в программировании привело к возникновению различных формальных моделей программ, в том числе и моделей параллельных программ.
Рассмотрим модели параллельных программ, прототипом которых явились операторные схемы программ, в частности схемы Янова.
В.Е.Котовым и А.С.Нариньяни была предложена формальная модель параллельных вычислений, названная асинхронной моделью.
Асинхронная программа над памятью M (A-программа) представляет собой множество X блоков и массивов блоков. Блок x образован парой (y, 0), где y – предикат над MCÌM, MC – управляющая память, O – оператор над памятью M. С O-оператором связаны входные и выходные наборы переменных из М. По входному набору О-оператор вычисляет значение переменных выходного набора. Предикат y – спусковая функция блока x.
Кроме асинхронной программы, в понятие асинхронной модели входит и асинхронная система. Асинхронная система представляет собой совокупность правил, позволяющих для заданной асинхронной программы X и заданного начального значения памяти M осуществить некоторый процесс вычислений.
Чтобы получить более формальное определение пары "программа–система", вводится конструкция метасистемы, которая сопоставляет каждому начальному состоянию памяти некоторое множество вычислительных процессов. Приведем некоторые понятия и обозначения.
Пусть A – множество операторов над памятью M.
Для каждого момента t множество операторов вычислительного процесса можно разбить на 4 непересекающихся множества:
+At – включающиеся в t;
-At – выключающиеся в t;
pAt – находящиеся во включенном состоянии;
0At – находящиеся в выключенном состоянии.
Q = {q} – множество состояний метасистемы, q0 – начальное состояние.
F – функция, однозначно сопоставляющая каждому множеству

y – функция, ставящая в соответствие каждому набору


включительно).
Каждому оператору aiÎA сопоставляется счетчик ci с начальным значением Æ.
Текущее значение счетчика ci фиксирует разность между числом имевших место включений и числом имевших место выключений
оператора ai.
Тогда модель Котова–Нариньяни можно записать в виде рекурсивных соотношений:
qt = Y(M0, P||t-1); |
At=At-1\+At-1È-At-1; |
*At=F1(0At, qt); |
+At Í *At; |
рAt=рAt-1\-At-1È +At; |
-At Í рAt. |
1. М – множество ячеек памяти.
2. A={a,b,...} – конечное множество операторов; для каждого оператора из А заданы:
K(a) – количество символов выключения оператора a (целое положительное число);
Д (а) £ М – множество входных ячеек оператора а;
Т (а) £ М – множество выходных ячеек оператора а.
3.Четверка Г = (а, q0,S,t) – управление схемы,
где q0 – выделенное начальное состояние.
При этом каждому оператору а сопоставлены один символ включения


где


t – функция переходов – частичная функция из QxS в Q, всюду определенная на QxSt.
Управление Г формирует последовательность выполнения операторов. Элементы из Si обозначают акты включения операторов, элементы из St – акты выключения. Включение оператора а допустимо лишь в таком состоянии q, что значение t
(q, a) определено. После включения оператора завершение его работы допустимо в произвольном состоянии, поскольку функция t всюду определена на QxSt. При включении оператор а использует значения ячеек из Д (а), при выключении он засылает свои результаты в ячейки из Т(а) и формирует символ выключения, который соответствует одному из K(а) направлений условной передачи.
Полезным для эффективного распознавания свойств параллельных схем программ является класс счетчиковых схем.
Счетчиковой схемой называется схема R=(M, A, Г ), для которой управление Г задается следующим образом.
Пусть k – целое неотрицательное число;
S – конечное множество;
S – множество с выделенным элементом S0;
pÎNk, где Nk – множество неотрицательных целых чисел;
v – функция из S в Nk, такая, что если sÎSt, то v(s)³0;
q: SxS®S – частичная функция, всюду определенная на SxSt.
Полагая, что значение t((S,x),s) определено, если определено q(S,s) и выполнено x+v(s)³0. Если значение определено, то полагается
t((S,x),s)=(q(S,s), x+v(s)).
Более простыми и наглядными являются параллельные операторные схемы – частный случай счетчиковых схем.
Параллельной операторной схемой называется произвольная счетчиковая схема, обладающая следующими свойствами:
1) S = {S0};
2) для каждого sÎS значение q(S0,s) определено;
3) если s – символ выключения, то каждая компонента вектора v(s) равна 0 или 1;
4) если s – символ включения, то каждая компонента вектора v(s) равна 0 или -1;
5) для любых двух неравных символов включения s, s¢ из
v(s)i= -1 следует v(s¢)i=0.
Параллельную операторную схему можно представить в виде ориентированного графа с операторными вершинами Оа, Оb, Оc,... и вершинами-счетчиками d1, d2, ..., dk. Каждый счетчик di помечается числом pi, которое является начальным значением этого счетчика. Дуги графа направлены либо от операторных вершин к счетчикам, либо от счетчиков к операторным вершинам. Дуги сопоставлены ненулевым компонентам векторов v(s).
Если (v(aj))i=1, то выключение оператора а с символом выключения aj увеличивает значение счетчика i на 1. Если (v(

Пример. Пусть необходимо перемножить матрицу


а результат поместить в (с1, с2).
Графовое представление некоторой интерпретированной операторной схемы, задающей алгоритм умножения, будет иметь следующий вид
(рис. 8.5).
Рассмотрим теперь другие модели программ, которые в меньшей мере опираются на понятие операторных схем программ.
В качестве модели программы иногда предлагается пара R=(M,C), где M определяет ее информационную, а С – управляющую структуру. Для представления информационной структуры М используются простые вычислительные модели, а для представления управляющей структуры – сети Петри. Сеть Петри – двудольный граф, множество вершин которого состоит из переходов tjÎT и позиций piÎP. Кроме того, заданы две функции инцидентности:
|
F : PxT®{0,1}; |
|
B : TxP®{0,1}. |
"p(N¢(p)=N(p)–F(p,t)+B(p,t)).
Переходы срабатывают последовательно, но недетерминированно. Сеть останавливается, если при некоторой разметке ни один из переходов не может срабатывать.
Сети Петри используются также для описания различных типов управления. Здесь тип управления задает семейство регулярных абстрактных структур управления. По уровням рассматриваются базовые средства управления следующих классов:
 |
· безусловные, которые не зависят от текущих значений переменных в исполняемой программе;
· условные, которые принимают во внимание текущие значения
данных.
Для исследования операционных проблем параллельного программирования удобной явилась модель UCLA-граф. UCLA-граф представляет собой ориентированный граф, вершины которого соответствуют операторам параллельной программы, дуги – управляющим или информационным связям между операторами.С каждой вершиной связаны входное управление и выходное управление, каждое из которых может быть двух типов – конъюнктивное и дизъюнктивное. При дизъюнктивном входном управлении выполнение оператора может начаться в том случае, если "активизируется" одна и только одна из дуг, входящих в эту вершину – оператор. В случае конъюнктивного входного управления выполнение оператора может начаться в том случае, если активизированы все дуги, заходящие в вершину. После завершения исполнения вершины с дизъюнктивным входным управлением активизируется одна и только одна из дуг, исходящая из вершины. В случае конъюнктивного выходного управления активизируются все дуги, исходящие из вершины. Существенным недостатком UCLA-графов является требование развертки циклов.
Некоторые способы совершенствования архитектуры
Архитектура компьютеров чаще всего совершенствуется за счет введения дополнительных средств. Рассмотрим некоторые из них.
Некоторые задачи реализации RISC-процессоров
Нас будет в основном интересовать выбор оптимального набора операций. При его решении мы можем по некоторой джентльменской смеси задач, для выполнения которой предназначен компьютер, выбрать пакет контрольных программ и построить для них профиль их выполнения либо использовать метод статических или динамических измерений параметров самих программ.
При профилировании программы определяется доля общего времени центрального процессора, затрачиваемого на выполнение каждого оператора (операции) программы. Анализ полученных результатов позволит выявить характерные особенности профилируемой программы.
При статических или динамических измерениях подсчитывается, сколько раз в программе встречается тот или иной оператор (операция) или как часто признаки принимают положительные или отрицательные значения в тексте программы (статика) либо в результате выполнения (динамика).
Сочетание результатов, полученных в ходе предложенных исследований, дает общую картину анализируемой программы. Вот результаты одного из таких измерений в статике, проведенные для программ-компиляторов: операторы присваивания– 48 %; условные операторы – 15; циклы – 16; операторы вызова-возврата – 18; прочие операторы – 3 %.
Измерение трехсот процедур, используемых в программах – операционных системах в динамике показали следующие измерения типов операндов: константы – 33 %; скаляры – 42; массивы (структуры) – 20 и прочие – 5 %.
При этом статистика среди команд управления потоком данных следующая. В разных тестовых пакетах программ команды условного перехода занимают от 66 до 78 %, команды безусловного перехода – от 12 до 18 %, частота переходов на выполнение составляет от 10 до 16 %.
Отсюда можно сделать вывод, что операторы присваивания занимают основную часть в программах-компиляторах, а операнды типа константа и локальные скаляры составляют основную часть операндов в процедурах, к которым происходит обращение в процессе выполнения программы.
Подобные количественные и качественные измерения образуют основу для оптимизации процессорной архитектуры.
Так, если операторы присваивания занимают 48 % всех операторов, то ясно, что операцию доступа к операндам следует реализовать аппаратно. Особенно это важно, если речь идет о нечисловых задачах, в которых операции вычислительного плана, как правило, просты. В условных операторах, операторах цикла и вызова-возврата производятся манипуляции над множеством операндов, что также подтверждает необходимость аппаратной реализации операции доступа к операндам.
При анализе типов операндов мы учитывали три категории:
* константы – не меняются во время выполнения программы и имеют, как правило, небольшие значения;
* скаляры – обращение к ним происходит, как правило, явно по их имени. Их обычно немного, и они описываются в процедурах как локальные;
* обращение к элементам массивов и структур происходит посредством индексов и указателей, т. е. через косвенную адресацию. Этих элементов, как правило, много.
Для осуществления доступа к операнду необходимо вначале определить физический адрес ячейки, где хранится операнд, а затем осуществить доступ к операнду. Если операнд – константа, ее можно указать в команде. Доступ к ней может быть осуществлен немедленно после обращения. В других случаях все зависит от типа памяти, где хранится операнд. Регистровые блоки и кэш-память мало отличаются по емкости, скорости доступа и стоимости, однако существенно отличаются по накладным расходам на адресацию. Обращение к кэш-памяти осуществляется при помощи адресов полной длины, которые требуют более высокой полосы пропускания каналов обмена. Как правило, этот адрес приходится формировать во время выполнения программы, что как минимум требует полноразрядного сложения или обращения к регистру либо и того, и другого.
Регистровые блоки адресуются короткими номерами регистров, которые обычно указываются в команде, что упрощает их декодирование. Однако регистровая память может хранить только определенные типы данных, в то время как кэш-память может использоваться и как основная. В связи с этим распределение скалярных переменных по регистрам необычайно важно, ибо существенно влияет на скорость обработки.
Необходимо решить вопрос с размером регистровых окон, ибо в обычной архитектуре окна однорегистровые, что требует операции запоминания-восстановления при каждом вызове-возврате.
При вызовах процедур необходимо запоминать содержимое регистров, а при возвращении – восстанавливать их, на что тратится значительное время. Вызовы процедур в современных структурированных программах делаются довольно часто, при этом суммарные накладные расходы на выполнение команд вызова и возврата из процедур на стандартных процессорах доходит до 50 % всех обращений к памяти в программе. Чтобы уменьшить время передачи данных между процедурами-родителями и процедурами-дочерьми (в случае, когда глубина их вложенности больше единицы), можно создать блок регистров, предоставив и родителям, и дочерям доступ к некоторым из них. Другими словами, необходимо создать перекрывающиеся блоки регистров. Такая возможность реализуется через перекрывающиеся "окна", накладываемые на блок регистров. Этот механизм реализован в RISC-архитектуре. Многие измерения показывают, что около 97 % процедур имеют не более шести параметров, что требует, чтобы перекрытие соседних окон шло где-то на пять регистров.
Процессор всегда содержит указатель текущего окна с возможностью его модификации в рамках реализованной глубины вложения процедур. Если глубина переполняется, часть содержимого окон направляется в основную память, чтобы иметь место для новых процедур. Для простоты реализации в ОП направляется содержимое целого окна. Это говорит о целесообразности введения многооконного механизма с заданным размером окна.
Размер окна определяется количеством передаваемых параметров, а количество окон – допустимой вложенностью процедур.
Среди достоинств применения больших регистровых блоков можно выделить высокую скорость доступа к блокам и увеличение частоты вызова процедур. Среди недостатков – высокая стоимость большого регистрового блока, организуемого в ущерб другим функциональным блокам на кристалле.
Аппаратная реализация механизма перекрытия окон должна вводиться, если получаемый выигрыш перекрывает затраты.
Так как значительная часть процедур требует от трех до шести параметров, то следует подумать об оптимизации использования окон. Во-первых, пересылать в ОП в случае переполнения регистрового блока можно не все окна, а только содержимое регистров, используемых для данной процедуры, и, во-вторых, применять механизм с окнами переменных размеров, определяемых во время выполнения.
Перспективной разновидностью RISC-архитектуры явилась архитектура SPARC (Scalable Processor Architecture).
Замечание. Scaling – масштабирование, т. е. способность представлять данные таким образом, чтобы и они, и результат проводимых с ними вычислений находились в диапазоне чисел, которые могут обрабатываться в рамках данного процесса или на данном оборудовании.
Новая серия SPARCSTATIONS фирмы Sun Microsystems базируется на SPARC-архитектуре. Первые модели этой фирмы были изготовлены уже в 1989 г. Операционной средой для всех станций фирмы Sun является SunOS – разновидность OS Unix, снабженная многооконным графическим интерфейсом Open Look.
Для повышения скорости обработки данных используются компьютеры с VLIW (Very Long Instruction Word)-архитектурой. Структура команды таких компьютеров наряду с кодом операции и адресами операндов включает теги и дескрипторы. Наряду с существенным ускорением обработки данных такая архитектура позволяет экономить память при достаточном количестве обращений к командам и сокращать общее количество команд в системе команд.
Области санкционированного доступа
Средства доступа используются для защиты данных, например, области ОС от ревизии пользователя. Как правило, имеющиеся средства защиты не охраняют процесс от самого себя или одну программную секцию от другой, или программы пользователя от программного обеспечения.
Для защиты памяти выделяются домены – области санкционированного доступа как локальное адресное пространство, определяющее адреса, которые могут формироваться или использоваться некоторым набором команд. Имеется в виду, что область памяти защищается и от случайного обращения, и от преднамеренного ввиду секретности хранимой информации.
Появилась мысль придать каждой программной секции (это обычно отдельно компилируемая программная единица) домен – отдельное адресное пространство, доступное только ее (секции) локальным переменным. Передача фактических параметров подпрограмм (секции), занимающей некоторый домен, можно рассматривать как временное его расширение и решение проблемы передачи данных. Как только доступ к данным (обмен) закончился, расширение "домен-секция" исчезает. Для большей защиты домена данных программной секции может быть предоставлена только конкретная точка входа (или несколько), а не доступ к любому слову (рис. 1.8).
 |
Рис. 1.8. Временное расширение домена
Использование доменов имеет ряд достоинств:
· улучшается отладка программ. Сфера действия любой ошибки ограничивается размерами домена, в котором она произошла, что увеличивает вероятность ее обнаружения;
· повышается надежность защиты программ. Информация, принадлежащая одной секции, защищается от воздействия других секций. Например, если модуль A вызывает модуль B для выполнения некоторых функций, то последний, будучи присоединенным к A, может анализировать все данные модуля A, хотя они должны быть защищены от подобных действий. Если же модуль A разделен на домены, возможности адресации модуля B ограничены только фактическими параметрами, которые передаются ему во время вызова. То же характерно и для вызываемого модуля B.
Чтобы исключить доступ ко всем данным исходной программы, ее сегментируют.
Для решения аппарата доменов, естественно, необходимы изменения и в архитектуре ЭВМ, например включение механизма, не разрешающего при выборе одного значения из домена доступ к другим его данным. Необходим механизм защиты от несанкционированных точек входа в модуль.
Очереди с обратной связью
Основной алгоритм FB (feedback) очередей с обратной связью использует n очередей, каждая из которых обслуживается в порядке поступления. Новый процесс поступает в первую очередь, затем после получения кванта времени он переходит в очередь со следующим номером и так далее после очередного кванта времени. Время процессора планируется таким образом, что он обслуживает непустую очередь с наименьшим номером. В методе FB каждый, вновь поступающий на обслуживание процесс получает (в неявном виде безусловно и в соответствии со стратегией обслуживания) высокий приоритет и выполняется подряд в течение такого количества квантов времени, пока не придет следующий процесс. Но если приход нового процесса задерживается, то текущий процесс не может проработать большее количество квантов, чем предыдущий процесс.
Процессы, требующие мало времени на обслуживание, обеспечиваются здесь лучше, чем при круговороте. Однако большое число очередей может увеличить накладные расходы.
Для уменьшения числа очередей можно разрешить каждому процессу фиксированное, большее единицы число раз проходить цикл, прежде чем переходить в очередь с другим номером. При этом очереди, упорядоченные по FB, обслуживаются по правилу круговорота внутри каждой очереди и по тому же правилу распределяется время процессора между очередями.
Для лучшего использования выгоды от метода FB пользователи могут свои процессы разбить на мелкие. Основное преимущество очередей FB и RR по сравнению с обслуживанием по наивысшему приоритету в том, что FB и RR позволяют хорошо обслуживать короткие задания, не требуя предварительной информации о времени выполнения процесса.
Если мы желаем использовать информацию о приоритетах, то можно применить круговорот со смещением, когда каждому процессу выделяется квант времени ЦП в зависимости от внешнего приоритета.
Одноуровневая память
Программист по-разному адресует память в зависимости от того, данные расположены в оперативной или внешней памяти. На программиста возлагается обязанность по явному заданию перемещения данных (операции ввода-вывода). В связи с ограниченным объемом оперативной памяти необходимо прибегать к другим принципам организации памяти, например к файловым структурам. Все это повышает стоимость программирования.
Данные в программу поступают обычно через передачу фактических параметров или через ввод-вывод (имеющий, например, файловую структуру). Эта разная организация данных может быть неприемлемой для одного и того же модуля. Кстати, организация файлов на накопителях на магнитных лентах (НМЛ) отличается от организации их на НМД.
Решение указанных проблем требует унификации всего разнообразия ЗУ, чтобы программист имел одинаковую адресацию вне зависимости от организации ЗУ. Теперь файлы станут элементами одноуровневой памяти, функции перемещения данных между различными уровнями ЗУ возлагаются на ЭВМ. Это в чем?то напоминает виртуальную память. Однако одноуровневая память в отличие от виртуальной распространяется на все запоминающее пространство системы, а не только на вопросы, связанные с недостатком оперативной памяти. Кроме того, обслуживающий набор виртуальной памяти– это модель, исчезающая при завершении работы.
Достоинства одноуровневой памяти:
· сравнительно низкая стоимость программного обеспечения;
· независимость адресации от принципа организации памяти.
Трудности, возникающие при этом:
· создание встроенного в архитектуру ЭВМ механизма иерархии ЗУ;
· восстановление памяти;
· переносимость объектов на другие системы с традиционной орга-низацией архитектуры.
Операции P и V над семафорами
В 1968 г. Э. Дейкстра предложил удобную форму механизма захвата/освобождения ресурсов, которую он назвал операциями P и V над считающими семафорами. Считающим семафором называют целочисленную переменную, выполняющую те же функции, что и байт блокировки. Однако в отличие от последнего она может принимать кроме "0" и "1" и другие целые положительные значения.
Семафоры – это часть абстракции, поддерживающая очередь постоянно ожидающих процессов.
Операции P и V над семафором S могут быть определены следующим образом.
P(S):
1. Уменьшить значение S на 1, т. е. S: = S – 1.
2. Если S < 0, выполнить ОЖИДАНИЕ (S).
V(S):
1. Увеличить значение S на 1, т. е. S : = S + 1.
2. Если S ³ 0, выполнить ОПОВЕЩЕНИЕ (S).
Операция ОЖИДАНИЕ (S) (WAIT) блокирует обслуживание процесса, делает соответствующую отметку об этом и связывает процесс со значением переменной S.
Операция ОПОВЕЩЕНИЕ (S) (SIGNAL) просматривает связанный с переменной S список блокированных процессов. Если в списке есть процессы, ожидающие освобождения некоторого ресурса, управляемого (сигнализируемого) S, один из них переводится в состояние готовности, а в соответствующей ему записи делается отметка. С этого момента процесс становится опять доступным планировщику.
По определению, ожидание, связанное с операцией P(S), не является ожиданием "зависания", так как ожидающие процессы не используют центральный процессор. Так как несколько процессов могут ожидать операцию P(S) над отдельным семафором, во время приращения должен быть осуществлен выбор, какую контрольную точку процесса сделать доступной. Алгоритм выбора не определен, за исключением требования равнодоступности процессов, т. е. никакой процесс не может быть "забыт".
Типичным примером использования алгоритма семафоров является задача производитель/потребитель. Задается максимальная емкость хранилища. Производитель не должен переполнять его, а потребитель не должен пытаться брать продукцию из пустого хранилища.
Наиболее употребительные операции над семафорами:
· создать семафор;
· запросить состояние семафора;
· изменить состояние семафора;
· уничтожить семафор.
Операции над семафорами в силу своей неделимости позволяют блокировать или активизировать процессы при освобождении или запросах ресурсов любого типа (памяти, процессоров, устройств ввода-вывода и т. п.).
Наиболее показательно аппарат семафоров можно применить на следующей задаче.
Три курильщика сидят за столом. У одного есть табак, у другого – бумага, у третьего – спички. На столе могут появиться извне два из трех упомянутых предмета. Появившиеся предметы забирает тот курильщик, у которого будет полный набор предметов. Он сворачивает папиросу, раскуривает ее и курит. Новые два предмета могут появиться на столе только после того, как он кончит курить. Другие курильщики в это время не могут начать курение.
Задание. Описать с помощью P и V – операций над семафорами – систему процессов, которая моделирует взаимодействия этих курильщиков.
Указание. Выделить шесть процессов, три из которых соответствуют трем курильщикам X, Y, Z, а три других имеют следующее назначение: А – поставляет спички и бумагу, В – табак и спички, С – бумагу и табак.
Требование. Процессы-поставщики не знают, какие предметы находятся у курильщиков.
Проблема взаимоисключения включает в себя нахождение протокола, который может использоваться отдельными процессами в момент входа в критический раздел или выхода из него.
Рассмотренные приемы синхронизации просты и сравнительно эффективны, однако их использование приводит порой к сложным и труднопостижимым конструкциям, которые чувствительны к незначительным изменениям. Рассмотрим более простые в реализации приемы, которые дают уверенность программисту в правильности написанной программы. Но сначала рассмотрим еще один способ представления процессов.
Оптимизация системы команд
Важным вопросом построения любой системы команд является оптимальное кодирование команд. Оно определяется количеством регистров и применяемых методов адресации, а также сложностью аппаратуры, необходимой для декодирования. Именно поэтому в современных RISC-архитектурах используются достаточно простые методы адресации, позволяющие резко упростить декодирование команд. Более сложные и редко встречающиеся в реальных программах методы адресации реализуются с помощью дополнительных команд, что, вообще говоря, приводит к увеличению размера программного кода. Однако такое увеличение программы с лихвой окупается возможностью простого увеличения частоты RISC-процессоров. Этот процесс мы можем наблюдать сегодня, когда максимальные тактовые частоты практически всех RISC-процессоров (Alpha, R4400, HyperSPARC и Power2) превышают тактовую частоту, достигнутую процессором Pentium.
Общую технологию проектирования системы команд для новой ЭВМ можно обозначить так: зная класс решаемых задач, выбираем некоторую типовую СК для широко распространенного компьютера и исследуем ее на предмет присутствия всего разнообразия операций в заданном классе задач. Вовсе не встречающиеся или редко встречающиеся операции не покрываем командами. Все частоты встреч операций для задания их в СК всякий раз можно определить из соотношений "стоимость затрат – сложность реализации – получаемый выигрыш".
Второй путь проектирования СК состоит в расширении имеющейся системы команд. Один из способов такого расширения – создание макрокоманд, второй – используя имеющийся синтаксис языка СК, дополнить его новыми командами с последующим переассемблированием, через расширение функций ассемблера. Оба эти способа принципиально одинаковы, но отличаются в тактике реализации аппарата расширения.
Так, система команд для ПК IBM покрывает следующие группы операций: передачи данных, арифметические операции, операции ветвления и циклов, логические операции и операции обработки строк.
Разработанную СК следует оптимизировать. Один из способов оптимизации состоит в выявлении частоты повторений сочетаний двух или более команд, следующих друг за другом в некоторых типовых задачах для данного компьютера, с последующей заменой их одной командой, выполняющей те же функции. Это приводит к сокращению времени выполнения программы и уменьшению требуемого объема памяти.
Мы можем исследовать и часто генерируемые компилятором некоторые последовательности команд, убирая из них избыточные коды.
Оптимизацию можно проводить и в пределах отдельной команды, исследуя ее информационную емкость. Для этого можно применить аппарат теории информации, в частности для оценки количества переданной информации – энтропию источника. Тракт "процессор – память" можно считать каналом связи.
Замечание. Энтропия – это мера вероятности пребывания системы в данном состоянии (в статистической физике).
ОРГАНИЗАЦИЯ СИСТЕМЫ ПРЕРЫВАНИЯ
Появление системы прерывания в компьютерах конца 50-х годов позволило существенно продвинуться в разработках ЭВМ, по-новому переосмыслив их возможности и среды применения. Действительно, уже на первых ЭВМ, обладающих этим свойством, появилась возможность автономной работы периферийных устройств после их запуска центральным устройством управления. По окончании работы или в связи с другой причиной периферийное устройство смогло через прерывание заставить центральный процессор обратить на себя внимание. Это открыло путь к широкому совмещению операций, что повлекло за собой естественное усложнение математического обеспечения. Современные операционные системы полностью разрабатываются и базируются на развитой системе прерывания.
Организация возврата к прерванной программе
Для осуществления возврата к прерванной программе необходимо полностью восстановить ее начальное состояние. Информацию, которую следует сохранять при прерывании программы, можно разделить на основную (которая запоминается всегда) и дополнительную (необходимость запоминания которой зависит от содержания прерывающей программы).
В основную информацию можно включить:
*
содержимое счетчика адреса команд, т. е. адрес первой невыполненной команды прерванной программы;
* триггер состояния системы: "рабочее" или состояние "ожидания";
* маска прерывания, устанавливаемая каждой новой программой;
* код прерывания – двоичное число, отдельное для каждого уровня, объединяющего прерывание от нескольких источников, по которому прерывающая программа опознает конкретный источник прерывания.
Так как код прерывания обычно находится в общем для всех уровней регистре, то, если предыдущий код полностью себя не исчерпал (а это почти всегда так), с приходом новой прерывающей программы его надо запомнать.
Указанная информация образует так называемое "слово состояния программы" (ССП) (иногда его называют вектором состояния программы), которое хранится в некотором поле памяти компьютера. В момент прерывания старое ССП, относящееся к прерванной программе, заменяется ССП прерывающей программы, а в конце прерывания старое ССП восстанавливается прерывающей программой. Для ускорения процесса замены ССП эту процедуру выполняют обычно аппаратным путем.
Замечание. В период сохранения и восстановления ССП прерывания любого уровня запрещены.
К дополнительной информации относят содержимое:
* арифметических регистров;
* индексных регистров;
* прочих программно-доступных регистров, общих для всех программ, и т. п.
Сохранение дополнительной информации увеличивает время обслуживания. Поэтому программисту надо тщательно продумать, что из дополнительной информации следует запоминать в каждом конкретном случае. Более того, момент прерывания следует выбирать так (если это возможно), чтобы дополнительной информации для сохранения было как можно меньше.
Основные определения и характеристики
Работу вычислительной системы можно представить как последовательность программно-определяемых (порождаемых программой и возможные моменты появления которых известны) и программно-независимых (вызванных посторонними от программы источниками или моменты возникновения которых неизвестны) событий.
События, происходящие вне процессора, как правило, программно-независимые (выход параметров объекта за дозволенные пределы, запросы оператора и т. д.) и происходят асинхронно. То же относится и к периферийным устройствам, работающим одновременно с выполнением программы в процессоре, хотя начало их работы и задает процессор, однако окончание ее и последовательность операций неизвестны.
События, происходящие внутри процессора, могут быть двух типов. Последовательность арифметических операций определяется программой, в то время как особые ситуации (переполнение, попытка деления на нуль и т.д.) зависят от сочетания операндов и предусмотреть их во время программирования практически невозможно. ВС, вообще говоря, должна реагировать на любые события, которые могут повлиять на процесс вычислений. В случае программно-определяемых событий для этого достаточно иметь специальный набор команд (переход по нулю, по знаку и т. д.). Если же события программно-независимые, то, как правило, неэффективно использовать обычные программные методы для их опознания.
Предположим, что мы ввели команду перехода по какому-нибудь программно-независимому событию, тогда
* неясно, когда это событие произойдет;
* неясно, как часто следует вставлять в программу команду перехода по данному событию.
Повторение периодической проверки выполнения требуемого условия называют "сканированием входов". Если сканирование производится, например, через 25 команд, то объем памяти для программы увеличивается на 4 %, а реакция на событие может произойти с большой задержкой (максимум через 25 команд).
При большом количестве проверяемых условий это сильно затрудняет работу программиста.
Чтобы ВС могла реагировать на программно-независимые события при минимальных усилиях программиста и максимально возможном быстродействии, ее надо снабдить дополнительными аппаратно-логическими средствами, совокупность которых называют системой прерывания программ (СПП).
Определение. Прерывание программы – это свойство ВС при возникновении особых событий временно прекратить выполнение текущей программы и передать управление программе, специально предусмотренной для обработки данного события.
 |
Рис 6.1. Временная диаграмма прерывания
Так как функции по сохранению и восстановлению состояния прерванной программы возлагаются на саму прерывающую программу, то последняя должна состоять из трех частей: подготовительной и восстановительной, обеспечивающих переход к нужной программе, и собственно прерывающей программы.
По окончании работы прерывающей программы переход может быть осуществлен либо к прерванной программе, либо к другой прерывающей программе.
Так как всевозможные запросы на прерывание вырабатываются независимо и асинхронно, то возможны такие ситуации:
* приход запросов последовательный;
* одновременный приход нескольких запросов;
* приход запроса во время выполнения прерывающей программы.
Следовательно, должен быть организован порядок, в котором поступившие запросы удовлетворяются. Если в ВС имеются средства для обслуживания запросов в порядке присвоенного им приоритета, то такие системы прерывания называются приоритетными.
СПП, как правило, выполняют следующие основные функции:
· организуют вход в прерывающую программу;
· осуществляют приоритетный выбор между запросами прерывания;
· обеспечивают возврат к прерванной программе и программное изменение приоритетов программ.
Основные подходы к проектированию языков параллельного программирования
Средства описания вычислительного процесса, заложенные в большинстве языков программирования, носят, как правило, последовательный характер. Все дело в том, что применяемое понятие алгоритма (уточнение с помощью нормального алгоритма Маркова или одноголовочной машины Тьюринга) использует пошаговый процесс его реализации. Даже такие высокоразвитые и широко применяемые языки, как ФОРТРАН и ПАСКАЛЬ, базируются на последовательном характере записи алгоритма. Однако в связи с созданием и эксплуатацией многопроцессорных систем и многомашинных комплексов назрела и постепенно начала воплощаться в жизнь идея описания алгоритмов в последовательно-параллельной форме, что позволило явно указывать в программе элементы, допускающие их параллельное выполнение.
Программирование задач для таких вычислительных установок получило название параллельного программирования, а соответствующие языки называют языками параллельного программирования. Под параллельным программированием будем понимать создание объектов – параллельных программ, каждая из которых есть организованная совокупность модулей с возможностями одновременного выполнения и взаимодействия.
Рассмотрим основные пути, по которым идут при создании ЯПП.
Можно выделить два подхода к проектированию ЯПП. При так называемом параллельно-последовательном подходе ЯПП должен иметь средства для явного указания параллельных ветвей и порядка следования участков параллельности. При выполнении программы управление переходит от одного участка параллельности к другому, каждый раз ветвясь на требуемое число независимых управлений. Переход между участками программы осуществляется только тогда, когда все независимые управления достигнут конца
своих ветвей.
При асинхронном подходе параллельные ветви явно не задаются, и лишь в некоторые моменты времени при выполнении программы выясняется возможность (готовность) выполнения отдельного фрагмента задачи независимо от других фрагментов.
При проектировании ЯПП работа ведется как в направлении создания дополнительных средств в существующих последовательных языках, так и в плане создания ЯПП на совершенно новых принципах.
Популярность языков программирования может определяться различными причинами: изощренной реализацией на компьютере, имеющимися приложениями, традицией использования и т. д. Однако проектирование ЯП всегда должно сопровождаться определенными требованиями. Язык программирования – это формальный язык связи человека с компьютером, предназначенный для описания данных и алгоритмов их обработки. В отличие от языка общения между людьми он не должен допускать двусмысленностей и неопределенностей. Вот некоторые требования к ЯП:
· ясность, простота и согласованность понятий языка с простыми и регулярными правилами их конструирования;
· ясность структуры программы, написанной на ЯП, с возможностями их модификации;
· естественность в приложениях: иметь для реализации задачи подходящие структуры данных, операции, управляющие структуры и естественный синтаксис;
· легкость расширения за счет моделирования простыми средствами сложных структур, имеющихся в конкретных задачах;
· богатое внешнее обеспечение: средства тестирования, отладки, редактирования, хранения;
· эффективность создания, трансляции, тестирования, выполнения и использования программ.
Однако следует отметить, что проблема удобства и простоты некоторого ЯП для создания программ "с нуля" сегодня менее актуальна. Уже написаны программы для решения такого количества задач (некоторые из них по много раз на различных ЯП и в разных программных средах), что следует только в соответствии с поставленной задачей отобрать необходимые компоненты (программы), настроить их и проинтегрировать, т. е. объединить в одну систему. Такие действия адекватны технологии крупноблочного проектирования, в основе которой лежит понятие компонентной объектной среды (КОС). КОС – это современный фундамент для накопления и использования знаний. Она базируется на компонентной объектной модели и включает готовые компоненты и инструментальное окружение, позволяющее выбирать необходимые компоненты, настраивать их и связывать между собой, создавая необходимое приложение.
КОС обладает всеми свойствами, присущими объектно-ориентированному подходу:
· инкапсуляция объектных компонент скрывает от пользователя сложности их реализации, делая видимым лишь предоставляемый интерфейс;
· наследование позволяет совершенствовать компоненты, не нарушая целостности объектной оболочки;
· полиморфизм, по сути, позволяет группировать объекты, характеристики которых в некотором плане можно считать сходными.
Что касается языков параллельного программирования, то к ним могут быть предъявлены дополнительные требования. В частности, ЯПП должен:
· иметь средства максимального выражения в программе присущего данной задаче естественного параллелизма;
· быть независимым от структуры конкретного компьютера, в частности от числа процессоров, доступных для программ, от времени выполнения отдельных ветвей программы и т. д.;
· обладать простотой диспетчеризации параллельных программ, записанных на нем;
· обеспечить простоту записи (преобразования) программ на ЯПП по заданным последовательным алгоритмам.
При расширении последовательных ЯП обычно используются операторы for-join,
parbegin-parend, cobegin-coend – аналог операторных скобок в обычных ЯП, окаймляющих фрагменты параллельного выполнения.
Типичным примером расширения возможностей последовательных ЯП служит дополнение языков АЛГОЛ-60 и ФОРТРАН операторами типа fork< список меток > и join < список меток >. Оператор fork открывает участок параллельности в заданной программе, а оператор
join закрывает его. После выполнения каждой ветви с заданной в операторе fork меткой управление передается оператору join. Последний не передает управление на продолжение программы до тех пор, пока управление от всех сегментов, метки которых указаны в операторе join, ему не переданы.
Чтобы ЯП АЛГОЛ-60 обладал необходимыми свойствами языка параллельного программирования, его можно дополнить (кроме fork и join) операторами типа:
terminate < список меток > – оператор блокировки фрагментов программы (если он предшествует оператору join, то блокируется выполнение фрагментов программы с общими у обоих операторов метками);
obtain < список переменных >, который блокирует использование переменных, участвующих в вычислительном процессе;
release < список переменных >, снимающего блокировку с указанных в нем переменных.
Если, например, нам в программе встретилась запись
k) join S1, S2, S7
k + 1) for i = 1 step
1 until N do,
то управление от оператора k будет передано оператору k + 1 только в том случае, если выполнятся фрагменты с метками S1, S2, S7. Если, например, необходимо одновременно выполнить целый массив параллельных ветвей, то в параллельном ЯП следует организовать некоторый специальный цикл. Синтаксически он напоминает обычный цикл в ЯП.
Основные принципы RISC-архитектуры
В компьютерной индустрии наблюдается настоящий бум систем с RISC-архитектурой. Рабочие станции и серверы, созданные на базе концепции RISC, завоевали лидирующие позиции благодаря своим исключительным характеристикам и уникальным свойствам операционных систем типа UNIX, используемых на этих платформах.
В самом начале 80-х годов почти одновременно завершились теоретические исследования в области RISC-архитектуры, проводившиеся в Калифорнийском, Стэнфордском университетах, а также в лабораториях фирмы IBM. Особую значимость имеет проект RISC-1, который возглавили профессора Давид Паттерсон и Карло Секуин. Именно они ввели в употребление термин RISC и сформулировали четыре основных принципа RISC-архитектуры:
* каждая команда независимо от ее типа выполняется за один машинный цикл, длительность которого должна быть максимально короткой;
* все команды должны иметь одинаковую длину и использовать минимум адресных форматов, что резко упрощает логику центрального управления процессором;
* обращение к памяти происходит только при выполнении операций записи и чтения, вся обработка данных осуществляется исключительно в регистровой структуре процессора;
* система команд должна обеспечивать поддержку языка высокого уровня. (Имеется в виду подбор системы команд, наиболее эффективной для различных языков программирования.)
Со временем трактовка некоторых из этих принципов претерпела изменения. В частности, возросшие возможности технологии позволили существенно смягчить ограничение состава команд: вместо полусотни инструкций, использовавшихся в архитектурах первого поколения, современные RISC-процессоры реализуют около 150 инструкций.
Однако основной закон RISC был и остается незыблемым: обработка данных должна вестись только в рамках регистровой структуры и только в формате команд "регистр – регистр –регистр".
В RISC-микропроцессорах значительную часть площади кристалла занимает тракт обработки данных, а секции управления и дешифратору отводится очень небольшая его часть.
Аппаратная поддержка выбранных операций, безусловно, сокращает время их выполнения, однако критерием такой реализации является повышение общей производительности компьютера в целом и его стоимость. Поэтому при разработке архитектуры необходимо проанализировать результаты компромиссов между различными подходами, различными наборами операций и на их основе выбрать оптимальное решение.
Развитие RISC-архитектуры в значительной степени определяется успехами в области проектирования оптимизирующих компиляторов. Только современная технология компиляции позволяет эффективно использовать преимущества большого регистрового файла, конвейерной организации и высокой скорости выполнения команд. Есть и другие свойства процесса оптимизации в технологии компиляции, обычно используемые в RISC-процессорах: реализация задержанных переходов и суперскалярная обработка, позволяющие в один и тот же момент времени посылать на выполнение несколько команд.
Особенности архитектуры Alpha компании DEC
В настоящее время семейство микропроцессоров с архитектурой Alpha представлено несколькими кристаллами, имеющими различные диапазоны производительности, работающие с разной тактовой частотой и рассеивающие разную мощность.
Первым на рынке появился 64-разрядный микропроцессор Alpha (DECchip 21064). Он представляет собой RISC-процессор в однокристальном исполнении, в состав которого входят устройства целочисленной и плавающей арифметики, а также кэш-память емкостью 16 Кб. Кристалл проектировался с учетом реализации передовых методов увеличения производительности, включая конвейерную организацию всех функциональных устройств, одновременную выдачу нескольких команд для выполнения, а также средства организации симметричной многопроцессорной обработки.
В кристалле имеются два регистровых файла по 32 64-битовых регистра: один– для целых чисел, второй – для чисел с плавающей точкой. Для обеспечения совместимости с архитектурами MIPS и VAX архитектура Alpha поддерживает арифметику с одинарной и двойной точностью как в соответствии со стандартом IEEE 754, так и в соответствии с внутренним для компании стандартом арифметики VAX.
В конце 1993 г. появилась модернизированная версия кристалла – модель 21064А, имеющая на кристалле кэш-память удвоенного объема и работающая с тактовой частотой 275 МГц.
Затем были выпущены модели 21066 и 21068, оперирующие на частоте 166 и 66 МГц. Отличительной особенностью этой ветви процессоров Alpha является реализация на кристалле шины PCI. Отличительная особенность модели 21068 – низкая потребляемая мощность (около 8 Вт). Основное предназначение этих двух новых моделей – персональные компьютеры и од
 |
ноплатные ЭВМ.
На рис. 4.8 представлена схема микропроцессора 21066.
Рис. 4.8. Основные компоненты процессора Alpha 21066
Кэш-память команд представляет собой кэш прямого отображения емкостью 8 Кб. Команды, выбираемые из этой кэш-памяти, могут выдаваться попарно для выполнения в одно из исполнительных устройств.
Кэш-память данных емкостью 8 Кб также реализует кэш с прямым отображением. При выполнении операций записи в память данные одновременно записываются в этот кэш и в буфер записи. Контроллер памяти или контроллер ввода-вывода шины PCI обрабатывает все обращения, которые проходят через расположенные на кристалле кэш-памяти первого уровня.
Контроллер памяти прежде всего проверяет содержимое внешней кэш-памяти второго уровня, которая построена на принципе прямого отображения и реализует алгоритм отложенного обратного копирования при выполнении операций записи. При обнаружении промаха контроллер обращается к основной памяти для перезагрузки соответствующих строк кэш-памяти. Контроллер ввода-вывода шины PCI обрабатывает весь трафик, связанный с вводом-выводом.
 |
Рис. 4.9. Пример построения системы на базе микропроцессора Alpha 21066
Конструкция поддерживает до четырех банков динамической памяти, каждый из которых может управляться независимо, что дает определенную гибкость при организации памяти и ее модернизации. Один из банков может заполняться микросхемами видеопамяти (VRAM) для реализации дешевой графики. Контроллер памяти прямо работает с видеопамятью и поддерживает несколько простых графических операций. Мостовая микросхема интерфейса ISA позволяет подключить к системе низкоскоростные устройства типа модема, флоппи-дисковода и т. д.
Модернизированная версия этого микропроцессора, новый кристалл Alpha 21066A, помимо интерфейса PCI, содержит на кристалле интегрированный контроллер памяти и графический акселератор.
Эти характеристики позволяют значительно снизить стоимость реализации систем, базирующихся на Alpha 21066A, и обеспечивают простой и дешевый доступ к внешней памяти и периферийным устройствам. Alpha 21066A имеет две модификации в соответствии с частотой 100 МГц и 233 МГц.
Микропроцессор Alpha 21164 представляет собой вторую реализацию архитектуры Alpha. Микропроцессор 21164, представленный в сентябре 1994 г., выполняет до четырех инструкций за такт. На кристалле микропроцессора 21164 размещено около 9,3 млн транзисторов, большинство из которых образуют кэш. Кристалл построен на базе 0,5-микронной КМОП технологии компании DEC.
Ключевыми моментами для реализации высокой производительности являются суперскалярный режим работы процессора, обеспечивающий выдачу для выполнения до четырех команд в каждом такте, высокопроизводительная неблокируемая подсистема памяти с быстродействующей кэш-памятью первого уровня, большая, размещенная на кристалле, кэш-память второго уровня и уменьшенная задержка выполнения операций во всех функциональных устройствах.
На рис. 4.10 представлена схема процессора, который включает пять
функциональных устройств: устройство управления потоком команд (IBOX); целочисленное устройство (EBOX); устройство плавающей точки (FBOX); устройство управления памятью (MBOX) и устройство управления кэш-памятью и интерфейсом шины (CBOX). На рисунке представлены три вида кэш-памяти. Кэш-память команд и кэш-память данных представляют собой первичные кэши, реализующие прямое отображение.
Множественно-ассоциативная кэш-память второго уровня предназначена для хранения команд и данных. Длина конвейеров процессора 21164 варьируется от 7 ступеней для выполнения целочисленных команд и 9 ступеней для реализации команд с плавающей точкой до 12 ступеней при выполнении команд обращения к памяти в пределах кристалла и переменного числа ступеней при выполнении команд обращения к памяти за пределами кристалла.
Устройство управления потоком команд осуществляет выборку и декодирование команд из кэша команд и направляет их для выполнения в соответствующие исполнительные устройства после разрешения всех конфликтов по регистрам и функциональным устройствам.
Оно управляет выполнением программы и всеми аспектами обработки исключительных ситуаций, ловушек и прерываний. Кроме того, обеспечивает управление всеми исполнительными устройствами, контролируя все цепи обхода данных и записи в регистровый файл.
Целочисленное исполнительное устройство выполняет целочисленные команды, вычисляет виртуальные адреса для всех команд загрузки и записи, обрабатывает целочисленные команды условного перехода и другие команды управления. Оно включает в себя регистровый файл и несколько функциональных устройств, расположенных на четырех ступенях двух параллельных конвейеров. Первый конвейер содержит сумматор, устройство логических операций, сдвигатель и умножитель. Второй конвейер содержит сумматор, устройство логических операций и устройство выполнения команд управления.
Устройство плавающей точки состоит из двух конвейерных исполнительных устройств: конвейера сложения, который выполняет все команды плавающей точки, за исключением команд умножения, и конвейер умножения, который выполняет команды умножения с плавающей точкой.
 |
Устройство управления памятью выполняет все команды загрузки, записи и барьерные операции синхронизации. Оно содержит полностью ассоциативный 64-строчный буфер преобразования адресов (DTB), 8 Кб кэш-память данных с прямым отображением, файл адресов промахов и буфер записи.
Отличительной особенностью микропроцессора 21164 является размещение на кристалле вторичного трехканального множественно-ассоциа-тивного кэша емкостью 96 Кб. Вторичный кэш резко снижает количество обращений к внешней шине микропроцессора. Кроме вторичного кэша, на кристалле поддерживается работа с внешним кэшем третьего уровня.
Особенности архитектуры POWER
Существенное развитие RISC-архитектуры в компании IBM произошли при разработке архитектуры POWER в конце 80-х. Архитектура POWER (и ее поднаправления POWER2 и PowerPC) в настоящее время являются основой семейства рабочих станций и серверов RISC System /6000 компании IBM.
Развитие архитектуры шло в следующих направлениях: воплощение концепции суперскалярной обработки; улучшение архитектуры как целевого объекта компиляторов; сокращение длины конвейера и времени выполнения команд и, наконец, приоритетная ориентация на эффективное выполнение операций с плавающей точкой.
Архитектура POWER во многих отношениях придерживается наиболее важных отличительных особенностей RISC: фиксированной длины команд, архитектуры регистр – регистр, простых способов адресации, простых (не требующих интерпретации) команд, большого регистрового файла и трехоперандного (неразрушительного) формата команд. Однако архитектура POWER имеет также несколько дополнительных свойств, которые отличают ее от других RISC-архитектур.
Во-первых, набор команд был основан на идее суперскалярной обработки. В базовой архитектуре команды распределяются по трем независимым исполнительным устройствам: устройству переходов, устройству с фиксированной точкой и устройству с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, где они могут выполняться одновременно и заканчиваться не в порядке поступления. Для увеличения уровня параллелизма, который может быть достигнут на практике, архитектура набора команд определяет для каждого из устройств независимый набор регистров. Это минимизирует связи и синхронизацию, требуемые между устройствами, позволяя тем самым исполнительным устройствам настраиваться на динамическую смесь команд. Любая связь по данным между устройствами должна анализироваться компилятором, который может ее эффективно спланировать. Но это только концептуальная модель. Любой конкретный процессор с архитектурой POWER может рассматривать любое из концептуальных устройств как множество исполнительных устройств для поддержки дополнительного параллелизма команд.
Но существование модели приводит к согласованной разработке набора команд, который, естественно, поддерживает степень параллелизма, по крайней мере равную трем.
Во-вторых, архитектура POWER расширена несколькими "смешанными" командами для сокращения времен выполнения. Возможно, единственным недостатком технологии RISC по сравнению с CISC, является то, что иногда она использует большее количество команд для выполнения одного и того же задания. Было обнаружено, что во многих случаях увеличения размера кода можно избежать путем небольшого расширения набора команд, которое вовсе не означает возврат к сложным командам, подобным командам CISC. Например, значительная часть увеличения программного кода была обнаружена в кодах пролога и эпилога, связанных с сохранением и восстановлением регистров во время вызова процедуры. Чтобы устранить этот фактор, IBM ввела команды "групповой загрузки и записи", которые обеспечивают пересылку нескольких регистров в память – из памяти с помощью единственной команды. Соглашения о связях, используемые компиляторами POWER, рассматривают задачи планирования, разделяемые библиотеки и динамическое связывание как простой, единый механизм. Это было сделано с помощью косвенной адресации посредством таблицы содержания (TOC – Table Of Contents), которая модифицируется во время загрузки. Команды групповой загрузки и записи были важным элементом этих соглашений о связях.
Архитектура POWER обеспечивает также другие способы сокращения времени выполнения команд, такие, как обширный набор команд для манипуляции битовыми полями, смешанные команды умножения-сложения с плавающей точкой, установку регистра условий в качестве побочного эффекта нормального выполнения команды и команды загрузки и записи строк (которые работают с произвольно выровненными строками байтов).
Третьим фактором, который отличает архитектуру POWER от многих других RISC-архитектур, является отсутствие механизма "задержанных переходов". Обычно этот механизм обеспечивает выполнение команды, следующей за командой условного перехода, перед выполнением самого перехода.
Этот механизм эффективно работал в ранних RISC-машинах для заполнения "пузыря", появляющегося при оценке условий для выбора направления перехода и выборки нового потока команд. Однако в более продвинутых суперскалярных машинах этот механизм может оказаться неэффективным, поскольку один такт задержки команды перехода может привести к появлению нескольких "пузырей", которые не могут быть покрыты с помощью одного архитектурного слота задержки. Архитектура переходов POWER была организована для поддержки методики "предварительного просмотра условных переходов" (branch-lockahead) и методики "свертывания переходов" (branch-folding).
Методика реализации условных переходов, используемая в архитектуре POWER, является четвертым уникальным свойством по сравнению с другими RISC-процессорами. Архитектура POWER определяет расширенные свойства регистра условий. Проблема архитектур с традиционным регистром условий заключается в том, что установка битов условий как побочного эффекта выполнения команды ставит серьезные ограничения на возможность компилятора изменить порядок следования команд. Кроме того, регистр условий представляет собой единственный архитектурный ресурс, создающий серьезное затруднение в машине, которая параллельно выполняет несколько команд или выполняет команды не в порядке их появления в программе. Некоторые RISC-архитектуры обходят эту проблему путем полного исключения из своего состава регистра условий и требуют установки кода условий с помощью команд сравнения в универсальный регистр либо путем включения операции сравнения в саму команду перехода. Последний подход потенциально перегружает конвейер команд при выполнении перехода.
Архитектура POWER предусматривает: a) специальный бит в коде операции каждой команды, что делает модификацию регистра условий дополнительной возможностью, и тем самым восстанавливает способность компилятора реорганизовать код, и б) (восемь) регистров условий для того, чтобы обойти проблему единственного ресурса и обеспечить большее число имен регистра условий так, что компилятор может разместить и распределить ресурсы регистра условий, как он это делает для универсальных
регистров.
Другой причиной выбора модели расширенного регистра условий является то, что она согласуется с организацией машины в виде независимых исполнительных устройств. Концептуально регистр условий является локальным по отношению к устройству переходов. Следовательно, для оценки направления выполнения условного перехода не обязательно обращаться к универсальному регистровому файлу. Для той степени, с которой компилятор может заранее спланировать модификацию кода условия (и/или загрузить заранее регистры адреса перехода), аппаратура может заранее просмотреть и свернуть условные переходы, выделяя их из потока команд. Это позволяет освободить в конвейере временной слот (такт) выдачи команды, обычно занятый командой перехода, и дает возможность диспетчеру команд создавать непрерывный линейный поток команд для вычислительных исполнительных устройств.
Первая реализация архитектуры POWER появилась на рынке в 1990 г. Затем компания IBM представила на рынок еще две версии процессоров POWER2 и POWER2+, обеспечивающих поддержку кэш-памяти второго уровня и имеющих расширенный набор команд.
По данным IBM, процессор POWER требует менее одного такта для выполнении одной команды по сравнению с примерно 1,25 такта у процессора Motorola 68040, 1,45 такта у процессора SPARC, 1,8 такта у Intel i486DX и 1,8 такта Hewlett Packard PA-RISC. Тактовая частота архитектурного ряда в зависимости от модели меняется от 25 до 62 МГц.
Процессоры POWER работают на частоте 33, 41,6, 45, 50 и 62,5 МГц. Архитектура POWER включает раздельную кэш-память команд и данных (за исключением рабочих станций и серверов рабочих групп начального уровня, которые имеют однокристальную реализацию процессора POWER и общую кэш-память команд и данных), 64- или 128-битовую шину памяти и 52-битовый виртуальный адрес. Она также имеет интегрированный процессор плавающей точки, что очень важно для научно-технических приложений с интенсивными вычислениями, хотя текущая стратегия RS/6000 нацелена и на коммерческие приложения.
RS/ 6000 показывает хорошую производительность на плавающей точке: 134.6 SPECp92 для POWERstation/POWERserver 580. Это меньше, чем уровень моделей Hewlett Packard 9000 Series 800 G/H/I-50, которые достигают уровня 150 SPECfp92.
Для реализации быстрой обработки ввода-вывода в архитектуре POWER используется шина Micro Channel, имеющая пропускную способность 40 или 80 Мб/с. Шина Micro Channel включает 64-битовую шину данных и обеспечивает поддержку работы нескольких главных адаптеров шины. Такая поддержка позволяет сетевым контроллерам, видеоадаптерам и другим интеллектуальным устройствам передавать информацию по шине независимо от основного процессора, что снижает нагрузку на процессор и соответственно увеличивает системную производительность.
Многокристальный набор POWER2 состоит из восьми полузаказных микросхем (устройств):
· блока кэш-памяти команд (ICU) – 32 Кб, имеет два порта с 128-битовыми шинами;
· блока устройств целочисленной арифметики (FXU) – содержит два целочисленных конвейера и два блока регистров общего назначения (по 32 32-битовых регистра). Выполняет все целочисленные и логические операции, а также все операции обращения к памяти;
· блока устройств плавающей точки (FPU) – содержит два конвейера для выполнения операций с плавающей точкой двойной точности, а также 54 64-битовых регистра плавающей точки;
· четырех блоков кэш-памяти данных – максимальный объем кэш-памяти первого уровня составляет 256 Кб. Каждый блок имеет два порта. Устройство реализует также ряд функций обнаружения и коррекции ошибок при взаимодействии с системой памяти;
· блока управления памятью (MMU).
Набор кристаллов POWER2 содержит порядка 23 млн транзисторов на площади 1217 мм2 и изготовлен по технологии КМОП с проектными нормами 0,45 мк. Рассеиваемая мощность на частоте 66,5 МГц составля-
ет 65 Вт.
Компания IBM распространяет влияние архитектуры POWER в направлении малых систем с помощью платформы PowerPC. Архитектура POWER в этой форме может обеспечивать уровень производительности и масштабируемость, превышающие возможности современных персональных компьютеров.
PowerPC базируется на платформе RS/6000 в простой конфигурации. В архитектурном плане основные отличия этих двух разработок состоят лишь в том, что системы PowerPC используют однокристальную реализацию архитектуры POWER, изготавливаемую компанией Motorola, в то время как большинство систем RS/6000 используют многокристальную реализацию. Первым на рынке был объявлен процессор 601, предназначенный для использования в настольных рабочих станциях компаний IBM и Apple. За ним последовали кристаллы 603 для портативных и настольных систем начального уровня и 604 для высокопроизводительных настольных систем. Наконец, процессор 620 разработан специально для серверных конфигураций, и ожидается, что со своей 64-битовой организацией он обеспечит исключительно высокий уровень производительности.
При разработке архитектуры PowerPC для удовлетворения потребностей трех различных компаний (Apple, IBM и Motorola) при сохранении совместимости с RS/6000 в архитектуре POWER были сделаны изменения в следующих направлениях:
· упрощение архитектуры в целях приспособления ее для реализации дешевых однокристальных процессоров;
· устранение команд, которые могут стать препятствием повышения тактовой частоты;
· устранение архитектурных препятствий суперскалярной обработке и внеочередному выполнению команд;
· добавление свойств, необходимых для поддержки симметричной многопроцессорной обработки;
· добавление новых свойств, считающихся необходимыми для будущих прикладных программ;
· обеспечение длительного времени жизни архитектуры путем ее расширения до 64-битовой.
Архитектура PowerPC поддерживает ту же базовую модель программирования и назначение кодов операций команд, что и архитектура POWER. В тех местах, где были сделаны изменения, которые могли потенциально препятствовать процессорам PowerPC выполнять существующие двоичные коды RS/6000, были расставлены "ловушки", обеспечивающие прерывание и эмуляцию с помощью программного обеспечения.
Микропроцессор PowerPC 601 выпускает как компания IBM, так и компания Motorola.
Он представляет собой процессор среднего класса и предназначен для использования в настольных вычислительных системах малой и средней стоимости. Двоичные коды RS/6000 выполняются на нем без изменений, что дало дополнительное время разработчикам компиляторов для освоения архитектуры PowerPC, а также разработчикам прикладных систем, которые должны перекомпилировать свои программы, чтобы полностью использовать возможности архитектуры PowerPC. Процессор 601 базировался на однокристальном процессоре IBM, который был разработан к моменту создания альянса трех ведущих фирм. В Power 601 реализована суперскалярная обработка, позволяющая выдавать на выполнение в каждом такте три команды, возможно, не в порядке их расположения в программном коде.
PowerPC 603 является первым микропроцессором в семействе PowerPC, полностью поддерживающим архитектуру PowerPC (рис. 4.11).
 |
Он включает пять функциональных устройств: устройство переходов; целочисленное устройство; устройство плавающей точки; устройство загрузки-записи и устройство системных регистров. Поскольку PowerPC 603 – суперскалярный микропроцессор, он может подавать в исполнительные уст-
ройства и завершать выполнение до трех команд в каждом такте. Кроме того, он обеспечивает программируемые режимы снижения потребляемой мощности, которые дают разработчикам систем гибкость реализации различных технологий управления питанием.
В процессоре команды распределяются по пяти исполнительным устройствам в порядке, заданном программой. Если отсутствуют зависимости по операндам, команды выполняются немедленно. Целочисленное устройство выполняет большинство команд за один такт. Устройство плавающей точки имеет конвейерную организацию и выполняет операции с плавающей точкой, как с одинарной, так и с двойной точностью. Команды условных переходов обрабатываются в устройстве переходов. Если условия перехода доступны, то решение о направлении перехода принимается немедленно, иначе выполнение последующих команд продолжается условно.
Наконец, пересылки данных между кэш-памятью данных, с одной стороны, и регистрами общего назначения и регистрами плавающей точки, с другой стороны, обрабатываются устройством загрузки-записи.
В случае промаха при обращении к кэш-памяти обращение к основной памяти осуществляется с помощью 64-битовой высокопроизводительной шины, подобной шине микропроцессора MC 88110. Для максимизации пропускной способности кэш-память взаимодействует с основной памятью главным образом посредством групповых операций, которые позволяют заполнить строку кэш-памяти за одну транзакцию.
Результаты выполнения команды направляются в буфер завершения команд (completion buffer) и затем последовательно записываются в соответствующий регистровый файл по мере изъятия команд из буфера завершения. Для минимизации конфликтов по регистрам в процессоре PowerPC 603 предусмотрены отдельные наборы из 32 целочисленных регистров общего назначения и 32 регистров плавающей точки.
Суперскалярный процессор PowerPC 604 обеспечивает одновременную выдачу до четырех команд. При этом параллельно в каждом такте может завершаться выполнение до шести команд. Процессор включает шесть исполнительных устройств, которые могут работать параллельно:
· устройство плавающей точки (FPU);
· устройство выполнения переходов (BPU);
· устройство загрузки-записи (LSU);
· три целочисленных устройства (IU):
· два однотактных целочисленных устройства (SCIU);
·
одно многотактное целочисленное устройство (MCIU).
Такая параллельная конструкция в сочетании со спецификацией команд PowerPC, допускающей реализацию ускоренного выполнения команд, обеспечивает высокую эффективность и большую пропускную способность процессора. Применяемые в процессоре 604 буфера переименования регистров, буферные станции резервирования, динамическое прогнозирование направления условных переходов и устройство завершения выполнения команд существенно увеличивают пропускную способность системы, гарантируют завершение выполнения команд в порядке, предписанном программой,
и обеспечивают реализацию модели точного прерывания.
В процессоре 604 имеются отдельные устройства управления памятью и отдельные по 16 Кб внутренние кэши для команд и данных. В нем реализованы два буфера преобразования виртуальных адресов в физические TLB (отдельно для команд и для данных), содержащие по 128 строк. Оба буфера являются двухканальными множественно-ассоциативными и обеспечивают переменный размер страниц виртуальной памяти. Кэш-памяти и буфера TLB используют для замещения блоков алгоритм LRU.
Процессор 604 обеспечивает как одиночные, так и групповые пересылки данных при обращении к основной памяти.
Процессор PowerPC 620 в отличие от своих предшественников полностью 64-битовый процессор. При работе на тактовой частоте 133 МГц его производительность оценивается в 225 единиц SPECint92 и 300 единиц SPECfp92, что соответственно на 40 % и 100 % больше показателей процессора PowerPC 604.
Подобно другим 64-битовым процессорам, PowerPC 620 содержит 64-битовые регистры общего назначения и плавающей точки и обеспечивает формирование 64-битовых виртуальных адресов. При этом сохраняется совместимость с 32-битовым режимом работы, реализованным в других моделях семейства PowerPC.
Особенности функционирования управляющей ЭВМ
Для автоматизации управления сложным производственным или технологическим процессом в контур управления включают компьютер, т.е. управляющую вычислительную машину (УВМ). Наиболее часто в качестве управляющей ЭВМ используют цифровую ЭВМ благодаря следующим ее качествам:
· наличию больших и высоконадежных ЗУ различного типа;
· возможности решения на них сложных вычислительных и логичес-
ких задач;
· гибкости (за счет программы);
· надежности и быстродействию.
В общем случае система автоматического управления с УВМ определяет собой замкнутый контур (рис. 1.12).
Здесь
· x1, x1, …, xn – измеряемые параметры:
·· нерегулируемые (характеристики исходного продукта);
·· выходные параметры, характеристики качества продукции;
·· выходные параметры, по которым непосредственно или путем расчета определяется эффективность производственных процессов (производительность, экономичность), или ограничения, наложенные на условия его протекания;
· y1, y2, …, yn – регулируемые параметры, которые могут изменяться исполнительными механизмами (ИМ) – регуляторами и оператором;
· f1, f2, …, fn – нерегулируемые и неизмеряемые параметры (например, химический состав сырья).
На вход УВМ от датчика Д (термопар, расходомеров) идет измерительная информация о текущем значении параметров x1, x2, …, xn. Согласно алгоритму управления, УВМ определяет величину управляющих воздействий U1, U2, …, Un, которые необходимо приложить к ИМ для изменения регулируемых параметров y1, y1, …, yn с тем, чтобы управляющий процесс протекал оптимально. Измерительные датчики вырабатывают непрерывный сигнал (напряжение, ток, угол поворота), а ЦВМ работает в дискретной форме, поэтому 2 раза идет преобразование из непрерывной формы в дискретную (Н/Д) и наоборот (Д/Н).
 |
Рис. 1.12. Принцип действия УВМ
Для уменьшения оборудования преобразователи Н/Д и Д/Н выполнены многоканальными. Посредством коммутатора преобразователь поочередно подключается к каждому датчику и осуществляется преобразование Н/Д.
Поступившее управляющее воздействие U сохраняется в цепи до выработки следующего управляющего воздействия в УВМ.
Теперь наибольшее распространение получил синхронный принцип связи УВМ с объектом, при котором процесс управления разбивается на циклы равной продолжительности тактирующими импульсами электронных часов.
Цикл начинается с приходом тактирующего импульса на устройство прерывания. В начале каждого цикла проводятся последовательный опрос и преобразование в цифровую форму сигналов датчиков.
После выработки управляющих воздействий Ui и преобразования их в непрерывную форму УВМ останавливается до прихода нового тактирующего импульса или выполняет какую-нибудь вспомогательную работу.
Для установления более тесной связи объекта с УВМ используют асинхронный принцип связи с объектом. Вместо тактирующих импульсов в УВМ поступают импульсы от датчиков прерывания (ДП), непосредственно связанных с объектом (например, конечных выключателей аварийного состояния). Каждый импульс прерывания эквивалентен требованию о прекращении производимых вычислений и переходе к выполнению подпрограммы, соответствующей данному каналу прерывания. УВМ реагирует на импульсы прерывания с учетом приоритета одних сигналов прерывания над другими.
В некоторых системах применяют комбинированный способ – синхронизацию "плюс" датчики аварийного состояния, переводящие УВМ на режим
аварийной работы. В замкнутом контуре (см. рис. 1.12) УВМ прямо воздействует на ИМ, непосредственно управляя производственным процессом. Это режим прямого цифрового управления.
Однако для сложных систем, а также для комплексов агрегатов, связанных между собой технологическим процессом, система управления строится так, что отдельные параметры процесса регулируются соответствующими автоматическими регуляторами, а УВМ обрабатывает измерительную информацию, рассчитывает и устанавливает оптимальные настройки регуляторов. Это повышает надежность системы, так как ее работоспособность сохраняется и при отказах УВМ.При такой схеме УВМ может быть более простой, так как снижается требование к ее быстродействию.
УВМ в разомкнутой цепи используется:
· в системах автоматического программного управления;
· в системах, где УВМ выполняет функции советчика.
В первом случае уменьшается объем первоначально вводимой информации в УВМ для расчета оптимальных настроек регуляторов. Детальный расчет программы управления с заданной точностью производится самим вычислительным устройством, которое в соответствии с этой программой вырабатывает необходимые управляющие воздействия.
В режиме советчика УВМ обрабатывает измерительную информацию с объекта и рассчитывает управляющие воздействия для оптимизации процесса. Эта информация служит рекомендацией оператору, управляющему процессом.
Особенности процессоров с архитектурой SPARC компании Sun Microsystems
Масштабируемая процессорная архитектура компании Sun Micro-systems (SPARC– Scalable Processor Architecture) является наиболее широко распространенной RISC-архитектурой, отражающей доминирующее положение компании на рынке UNIX-рабочих станций и серверов.
Первоначально архитектура SPARC была разработана в целях упрощения реализации 32-битового процессора. Впоследствии по мере улучшения технологии изготовления интегральных схем она постепенно развивалась, и в настоящее время имеется 64-битовая версия этой архитектуры.
В отличие от большинства RISC-архитектур SPARC использует регистровые окна, которые обеспечивают удобный механизм передачи параметров между программами и возврата результатов. Архитектура SPARC была первой коммерческой разработкой, реализующей механизмы отложенных переходов и аннулирования команд. Это давало компилятору большую свободу заполнения времени выполнения команд перехода командой, которая реализуется в случае выполнения условий перехода и игнорируется в случае, если условие перехода не выполняется.
Первый процессор SPARC был изготовлен компанией Fujitsu на основе вентильной матрицы, работающей на частоте 16,67 МГц. На основе этого процессора была разработана первая рабочая станция Sun-4 с производительностью 10 MIPS, объявленная осенью 1987 г. (до этого времени компания Sun использовала в своих изделиях микропроцессоры Motorola 680X0). В марте 1988 г. Fujitsu увеличила тактовую частоту до 25 МГц, создав процессор с производительностью 15 MIPS.
Позднее тактовая частота процессоров SPARC была повышена до 40 МГц, а производительность – до 28 MIPS.
Дальнейшее увеличение производительности процессоров с архитектурой SPARC было достигнуто за счет реализации в кристаллах принципов суперскалярной обработки компаниями Texas Instruments и Cypress. Процессор SuperSPARC компании Texas Instruments стал основой серии рабочих станций и серверов SPARCstation/SPARCserver 10 и SPARCstation/SPARCserver 20. Имеется несколько версий этого процессора, позволяющего в зависимости от смеси команд обрабатывать до трех команд за один машинный такт, отличающихся тактовой частотой.
Процессор SuperSPARC (рис. 4.1) имеет сбалансированную производительность на операциях с фиксированной и плавающей точкой. Он имеет внутренний кэш емкостью 36 Кб (20 Кб – кэш команд и 16 Кб – кэш данных), раздельные конвейеры целочисленной и вещественной арифметики и при тактовой частоте 75 МГц обеспечивает производительность около 205 MIPS. Процессор SuperSPARC применяется также в серверах SPARCserver 1000 и SPARCcenter 2000 компании Sun.
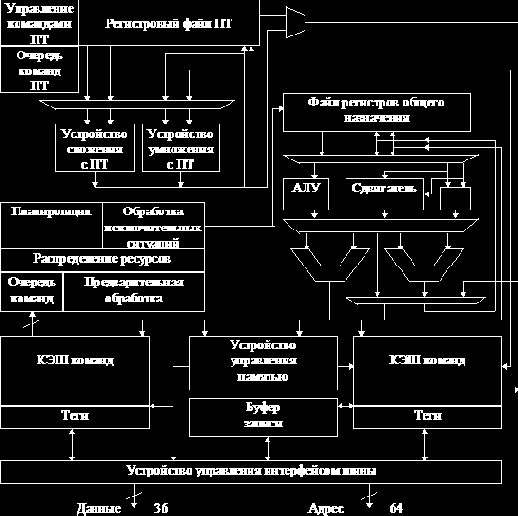 |
Конструктивно кристалл монтируется на взаимозаменяемых процессорных модулях трех типов, отличающихся наличием и объемом кэш-памяти второго уровня и тактовой частотой. Модуль Mbus SuperSPARC, используемый в модели 50, содержит SuperSPARC процессор с тактовой частотой 50 МГц с внутренним кэшем емкостью 36 Кб (20 Кб кэш команд и 16 Кб кэш данных). Модули Mbus SuperSPARC в моделях 51, 61 и 71 содержат по одному процессору SuperSPARC, работающему соответственно на частоте 50, 60 и 75 МГц, одному кристаллу кэш-контроллера (так называемому SuperCache), а также внешний кэш емкостью 1 Мб. Модули Mbus в моделях 502, 612, 712 и 514 содержат два SuperSPARC процессора и два кэш-контроллера каждый, а последние три модели – и по одному (1 Мб) внешнему кэшу на каждый процессор. Использование кэш-памяти позволяет модулям CPU работать с тактовой частотой, отличной от тактовой частоты материнской платы; пользователи всех моделей поэтому могут улучшить производительность своих систем заменой существующих модулей CPU вместо того, чтобы производить upgrade всей материнской платы.
Компания Texas Instruments разработала также процессор MicroSPARC с тактовой частотой 50 МГц и со встроенным кэшем емкостью 6 Кб, который ранее широко использовался в ранних моделях рабочих станций SPARCclassic и SPARCstation LX. Sun совместно с Fujitsu создали также новую версию кристалла MicroSPARC II с встроенным кэшем емкостью 24 Кб. На его основе построены рабочие станции и серверы SPARCstation/ SPARCserver 4 и SPARCstation/SPARCserver 5, работающие на частоте 70, 85 и 110 МГц.
В конце 1994 – начале 1995 г. на рынке появились микропроцессоры HyperSPARC, однопроцессорные и двухпроцессорные рабочие станции с тактовой частотой процессора 100 и 125 МГц. К середине 1995 года тактовая частота процессоров SuperSPARC была доведена до 90 МГц. Позже появились 64-битовые процессоры UltraSPARC I с тактовой частотой от 167 МГц, в конце 1995 – начале 1996 – процессоры UltraSPARC II с тактовой частотой от 200 до 275 МГц, а в 1997 – 1998 гг. – процессоры UltraSPARC III с частотой 500 МГц.
 |
Риc 4.2. Набор кристаллов процессора HyperSPARC
Процессорный набор HyperSPARC с тактовой частотой 100 МГц построен на основе технологического процесса КМОП с тремя уровнями металлизации и проектными нормами 0.5 мк. Внутренняя логика работает с напряжением питания 3.3 В.
Центральный процессор RT620 состоит из целочисленного устройства, устройства с плавающей точкой, устройства загрузки-записи, устройства переходов и двухканальной множественно-ассоциативной памяти команд емкостью 8 Кб. Целочисленное устройство включает АЛУ и отдельный тракт данных для операций загрузки-записи, которые представляют собой два из четырех исполнительных устройств процессора.
Устройство переходов обрабатывает команды передачи управления, а устройство плавающей точки реально состоит из двух независимых конвейеров – сложения и умножения чисел с плавающей точкой. Для увеличения пропускной способности процессора команды плавающей точки, проходя через целочисленный конвейер, поступают в очередь, где они ожидают запуска в одном из конвейеров плавающей точки. В каждом такте выбираются две команды. В общем случае, до тех пор, пока эти две команды требуют для своего выполнения различных исполнительных устройств при отсутствии зависимостей по данным, они могут запускаться одновременно. RT620 содержит два регистровых файла: 136 целочисленных регистров, сконфигурированных в виде восьми регистровых окон, и 32 отдельных регистра плавающей точки, расположенных в устройстве плавающей точки.
Кэш-память второго уровня в процессоре HyperSPARC строится на базе RT625 CMTU, который представляет собой комбинированный кристалл, включающий контроллер кэш-памяти и устройство управления памятью, поддерживающее разделяемую внешнюю память и симметричную многопроцессорную обработку. Контроллер кэш-памяти поддерживает кэш емкостью 256 Кб, состоящий из четырех RT627 CDU. Кэш-память имеет прямое отображение и 4Кб тегов. Теги в кэш-памяти содержат физические адреса, поэтому логические схемы для соблюдения когерентности кэш-памяти в многопроцессорной системе, имеющиеся в RT625, могут быстро определить попадания или промахи при просмотре со стороны внешней шины без приостановки обращений к кэш-памяти со стороны центрального процессора. Поддерживается как режим сквозной записи, так и режим обратного копирования.
Устройство управления памятью содержит в своем составе полностью ассоциативную кэш-память преобразования виртуальных адресов в физические (TLB), состоящую из 64 строк, которая поддерживает 4096 контекстов. RT625 содержит буфер чтения емкостью 32 байта, используемый для загрузки, и буфер записи емкостью 64 байта, используемый для разгрузки кэш-памяти второго уровня.
Размер строки кэш- памяти составляет 32 байта. Кроме того, в RT625 имеются логические схемы синхронизации, обеспечивающие интерфейс между внутренней шиной процессора и SPARC MBus при выполнении асинхронных операций.
RT627 представляет собой статическую память 16Кб (32Кб), специально разработанную для удовлетворения требований HyperSPARC. Она организована как четырехканальная статическая память в виде четырех массивов с логикой побайтной записи, входными и выходными регистрами-защелками. RT627 для ЦП является кэш-памятью с нулевым состоянием ожидания без потерь (т. е. приостановок) на конвейеризацию для всех операций загрузки и записи, которые попадают в кэш-память. RT627 был разработан специально для процессора HyperSPARC, в связи с чем для соединения его с RT620 и RT625 не нужны никакие дополнительные схемы.
Набор кристаллов позволяет использовать преимущества тесной связи процессора с кэш-памятью. Конструкция RT620 допускает потерю одного такта в случае промаха в кэш-памяти первого уровня. Для доступа к кэш-памяти второго уровня в RT620 отведена специальная ступень конвейера. Если происходит промах в кэш-памяти первого уровня, а в кэш-памяти второго уровня имеет место попадание, то центральный процессор не останав-
ливается.
Команды загрузки и записи одновременно генерируют два обращения: одно к кэш-памяти команд первого уровня емкостью 8 Кб и другое к кэш-памяти второго уровня. Если адрес команды найден в кэш-памяти первого уровня, то обращение к кэш-памяти второго уровня отменяется, и команда становится доступной на стадии декодирования конвейера. Если же во внутренней кэш-памяти произошел промах, а в кэш-памяти второго уровня обнаружено попадание, то команда станет доступной с потерей одного такта, который встроен в конвейер. Такая возможность позволяет конвейеру продолжать непрерывную работу до тех пор, пока имеют место попадания в кэш-память либо первого, либо второго уровня, которые составляют соответственно 90 % и 98 % для типовых прикладных задач рабочей станции.
С целью достижения архитектурного баланса и упрощения обработки исключительных ситуаций целочисленный конвейер и конвейер плавающей точки имеют по пять стадий выполнения операций. Такая конструкция позволяет RT620 обеспечить максимальную пропускную способность, не достижимую в противном случае.
Эффективная с точки зрения стоимости конструкция не может полагаться только на увеличение тактовой частоты. Экономические соображения заставляют принимать решения, основой которых является массовая технология. Системы MicroSPARC обеспечивают высокую производительность при умеренной тактовой частоте путем оптимизации среднего количества команд, выполняемых за один такт. Это требует эффективного управления конвейером и иерархией памяти. Среднее время обращения к памяти должно сокращаться либо должно возрастать среднее количество команд, выдаваемых для выполнения в каждом такте, увеличивая производительность на основе компромиссов в конструкции процессора.
 |
Рис. 4.3. Блок-схема процессора МicroSparc II
Основными свойствами целочисленного устройства МicroSPARC II
являются:
· пятиступенчатый конвейер команд;
· предварительная обработка команд переходов;
· поддержка потокового режима работы кэш-памяти команд и данных;
· регистровый файл емкостью 136 регистров (8 регистровых окон);
· интерфейс с устройством плавающей точки;
· предварительная выборка команд с очередью на четыре команды.
Целочисленное устройство использует пятиступенчатый конвейер команд с одновременным запуском до двух команд. Устройство плавающей точки обеспечивает выполнение операций в соответствии со стандартом IEEE 754.Устройство управления памятью выполняет четыре основные функции. Во-первых, оно обеспечивает формирование и преобразование виртуального адреса в физический. Эта функция реализуется с помощью ассоциативного буфера TLB. Кроме того, устройство управления памятью реализует механизмы защиты памяти. И наконец, оно выполняет арбитраж обращений к памяти со стороны ввода-вывода, кэша данных, кэша команд и TLB.
Процессор MicroSPARC II имеет 64-битовую шину данных для связи с памятью и поддерживает оперативную память емкостью до 256 Мб. В процессоре интегрирован контроллер шины SBus, обеспечивающий эффективную с точки зрения стоимости реализацию ввода-вывода.
Особенности системы прерывания в современных ЭВМ
Наибольшее распространение в компьютерах получили шесть уровней прерывания:
* ввод-вывод;
* обращение к супервизору;
* программный сбой;
* внешние прерывания;
* прерывание повторного пуска;
* прерывание от схем контроля.
Прерывания от ввода-вывода, идущие от каналов и периферийных устройств, сигнализируют системе о нормальном (или ненормальном) окончании операции.
Прерывание при обращении к супервизору позволяет пользователю направлять работу супервизора на реализацию нужных действий (выделить дополнительную область памяти, запустить операцию ввода-вывода и т. п.).
Программный сбой возникает в результате различного типа ошибок в программе: переполнение разрядной сетки, нарушение защиты, появление привилегированной команды в состоянии "задача" и т. п.
Внешние прерывания происходят от внешних по отношению к компьютеру объектов: от оператора путем нажатия определенной кнопки, от датчика времени и т. п.
Прерывание повторного пуска – это средство, которое позволяет оператору или какому-нибудь процессору вызвать выполнение требуемой программы.
Прерывание от схем контроля сигнализирует о неисправности оборудования и обеспечивает ее локализацию и исправление.
Каждый уровень прерывания может обслуживать несколько причин. Конкретная причина прерывания внутри уровня определяется программным путем по "коду прерывания" и некоторой дополнительной информации, которая запоминается каждый раз в оперативной памяти при возникновении прерывания.
В качестве примера дополнительной информации может быть слово состояния канала при прерываниях от ввода-вывода.
Каждому уровню прерываний соответствуют два ССП: новое и старое, которые хранятся в специальных полях реальной памяти. Общее назначение ССП – управление последовательностью выборки команд, запоминание и идентификация текущего состояния аппаратных средств относительно программы, выполняемой в фиксированный момент времени, и некоторые другие функции. Если мы желаем частично изменить состояние процессора, то необходимо загружать только требуемую часть нового ССП. Однако при прерываниях любого уровня происходит полная смена содержимого старого ССП на новое, которое становится текущим. Если в конце программы, которой было передано управление по прерыванию, стоит команда ВОС-СТАНОВИТЬ СТАРОЕ ССП, то процессор восстанавливает состояние, предшествующее прерыванию, и прерванная программа продолжает свое выполнение.
В ходе вычислительного процесса одновременно может возникнуть несколько событий, вызывающих прерывания. Одновременно появившиеся запросы на прерывание удовлетворяются в наперед установленном порядке, в соответствии с их приоритетами. Такая же ситуация наблюдается и с приоритетами между прерывающими программами. Чаще всего прерывание от схем контроля имеет наивысший приоритет.
Общая схема обработки прерываний дана на рис. 6.5.
Порядок приоритета может быть изменен программным путем через изменение маски прерывания. Чаще всего состояние "1" разряда маски разрешает прерывание данного уровня, а в состоянии "0" запрещает прерывание.
Если по каким-то причинам стандартные обработчики прерываний программиста не устраивают, он может подготовить свои обработчики.
 |
О наличии своих обработчиков операционная система должна знать заранее. Иногда этот вопрос решается во время генерации системы.
Особенности защиты информации в компьютерных сетях
В последнее время в связи с широким распространением локальных и глобальных компьютерных сетей необычайно остро встала проблема защиты информации при передаче или хранении в сети. Дело в том, что разработанные программы и подготовленные данные для отдельного компьютера и предназначенные для локального использования, практически не содержали средств защиты. Теперь, когда любой пользователь сети может попытаться заглянуть в чужой файл, защита информации в сети необычайно актуально. Особенно это важно в распространенной сегодня технологии типа "клиент–сервер".
Работа в сети на принципах "клиент–сервер" необычайно привлекательна своей открытостью. Однако построение систем защиты информации в них усложняется тем, что в одну сеть объединяется разнообразное ПО, построенное на различных аппаратно-программных платформах. Поэтому система защиты должна быть такой, чтобы владелец информации мог быстро ею воспользоваться, а не имеющий соответствующих полномочий испытывал значительные затруднения в овладении информацией. Системы защиты информации в них тоже различны. Даже простой вариант смены паролей требует согласования, ибо ПО защиты типа RACF для мейнфреймов требует смены пароля с периодичностью в 30 дней, а сетевая ОС – ежеквартально. Для доступа к информации требуется преодолеть несколько охранных рубежей. В связи с этим возникает задача синхронизации работы средств безопасности всех платформ, т. е. создание своеобразного "зонта безопасности" для всей компьютерной системы.
Работа в распределенных вычислительных средах в связи с наличием различных точек входа: рабочие станции, серверы баз данных, файл-серверы LAN – усложняет решение проблемы безопасности.
Многие разработчики баз данных (БД) перекладывают функции контроля доступа к данным на ОС, чтобы упростить работу пользователя ПК. Особенно это показательно для ОС Unix, где реализована надежная защита информации. Однако такой подход позволяет хакерам, маскируясь под клиентов Unix, иметь доступ к данным.
Более того, распределенные системы имеют, как правило, несколько БД, функционирующих по принципу локальной автономии и позволяющих иметь собственный механизм защиты. В распределенных системах однотипная информация может быть размещена в различных (территориально удаленных) БД или информация из одной (по семантике) таблицы может храниться на различных физических устройствах. Однако для головного пользователя распределенной системы необходимо организовать работу так, чтобы по одному запросу он мог получить полную информацию по всем дочерним фирмам, т. е. с точки зрения пользователя должен соблюдаться принцип географической прозрачности.
В БД Oracle, например, принцип географической прозрачности и фрагментарной независимости реализуется через механизм связей (links) и синонимов (synonyms). Посредством связей программируется маршрут доступа к данным: указываются реквизиты пользователя (регистрационное имя и пароль), тип сетевого протокола (например, TCP/IP) и имя БД. К сожалению, все эти параметры приходится описывать в тексте сценариев (scripts). Чтобы засекретить указанную информацию, пароли можно хранить в словаре данных в зашифрованном виде.
Наличие нескольких БД в распределенных системах в некоторой степени усложняет работу пользователей, не имеющих соответствующих полномочий по доступу к данным, ибо код должен преодолевать автономные защиты данных в различных БД.
Защита информации в распределенной среде многоуровневая. Чтобы прочесть пользователю необходимые данные, например, с помощью штатных программ администрирования, ему необходимо сначала попасть в компьютер (уровень защиты рабочей станции), потом в сеть (сетевой уровень защиты), а уже затем на сервер БД. При этом оперировать конкретными данными пользователь сможет лишь при наличии соответствующих прав доступа (уровень защиты БД). Для работы с БД через клиентское приложение придется преодолеть еще один барьер – уровень защиты приложения.
В арсенале администратора системы “клиент – сервер” имеется немало средств обеспечения безопасности, в частности встроенные возможности БД и различные коммерческие продукты третьих фирм.Важность внутренних средств защиты состоит в том, что контроль доступа происходит постоянно, а не только в момент загрузки приложения.
Каждый пользователь системы имеет свои полномочия по работе с данными. В широко известных базах данных Sybase и Microsoft SQL Server, например, тип доступа регулируется операторами GRANT и REVOKE, допускающими или запрещающими операции чтения, модификации, вставки и удаления записей из таблицы, а также вызова хранимых процедур. К сожалению, во многих БД минимальным элементом данных, для которого осуществляется контроль доступа, является таблица. Во многих практических задачах контроль доступа требуется осуществлять даже по отдельным полям или записям. Эта задача может быть реализована либо с помощью табличных фильтров (на уровне приложения), либо путем модификации структуры БД через денормализацию таблиц.
Отличительные черты RISC- и CISC- архитектур
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники, являются архитектуры CISC и RISC. Основоположником CISC-архитектуры– архитектуры с полным набором команд (CISC – Complete Instruction Set Computer) можно считать фирму IBM с ее базовой архитектурой IBM/360, ядро которой используется с 1964 г. и дошло до наших дней, например, в таких современных мейнфреймах, как IBM ES/9000.
Лидером в разработке микропроцессоров с полным набором команд считается компания Intel с микропроцессорами X86 и Pentium. Это практически стандарт для рынка микропроцессоров.
Простота архитектуры RISC-процессора обеспечивает его компактность, практическое отсутствие проблем с охлаждением кристалла, чего нет в процессорах фирмы Intel, упорно придерживающейся пути развития архитектуры CISC. Формирование стратегии CISC-архитектуры произошло за счет технологической возможности перенесения "центра тяжести" обработки данных с программного уровня системы на аппаратный, так как основной путь повышения эффективности для CISC-компьютера виделся, в первую очередь, в упрощении компиляторов и минимизации исполняемого модуля. На сегодняшний день CISC-процессоры почти монопольно занимают на компьютерном рынке сектор персональных компьютеров, однако RISC-процессорам нет равных в секторе высокопроизводительных серверов и рабочих станций.
Основные черты RISC-архитектуры с аналогичными по характеру чертами CISC-архитектуры отображаются следующим образом (табл. 2.1):
Таблица 2.1. Основные черты архитектуры
| CISC?архитектура | RISC-архитектура | ||||||||||||||
Отношение предшествования процессовВ научной литературе исследуются различные подходы к выделению и описанию параллельных процессов. В связи с этим рассмотрим различные типы параллелизма. Впервые, по-видимому, мы услышали о параллельном программировании в 1958 г. после выхода статьи Гилла (S. Gill) "Параллельные программы". Если система имеет только одну начальную (В) и только одну конечную (F) вершину (арех), то отношения предшествования, которые возможны между процессами p1, p2, ... , pn, показаны на рис. 8.1. Каждый граф на рис. 8.1 описывает трассу развития процесса во времени и указывает на отношение предшествования. Такие графы называют графами развития процесса. Пример 1. Вычислить значение выражения
Если точность вычисления значения выражения или другие побочные эффекты не предполагают иного порядка выполнения операций, то вычисления могут производиться параллельно. Рис. 8.1. Граф развития процесса:
а – последовательные процессы;б – параллельные процессы; в – последовательно-параллельные процессы
Н. Вирт (1966) предложил для описания параллелизма использовать простую конструкцию and. Тогда предложения программы для вычисления выражения (1) (рис. 8.3) могут быть следующими: begin S1: = a + b and S2: = c + d and S4: = e/f; S3: = S1 • S2; S5: = S3 – S4 end. С логической точки зрения каждый процесс имеет собственный процессор и программу. Реально два различных процесса могут разделять одну и ту же программу или один и тот же процессор. Например, для вышеприведенной задачи два разных процесса используют одну и ту же программу "сложить (+)". Таким образом, процесс не эквивалентен программе. В качестве упражнения полезно построить граф развития процесса для примеров 2 и 3 и решить пример 4. Пример 2. Сортировка слиянием. Во время i-го прохода в стандартной сортировке слиянием второго порядка пары сортируемых списков длины 2i–1 сливаются в списке длины 2i. Все слияния в пределах одного прохода могут быть выполнены параллельно. Пример 3. Умножение матриц. При выполнении умножения матриц A = B • C, все элементы матрицы A могут быть вычислены одновременно. Пример 4. Оценить требуемое минимальное время как функцию n для вычисления выражения a1 + a2 + ... + an , n ³ 1, в предположении, что: * параллельно может быть выполнено любое число операций сложения; * каждая операция (включая выборку операндов и запись результата) занимает одну единицу времени. P-языкПожалуй, одним из первых ЯПП был матричный P-язык, разработанный в ИМ с ВЦ СО АН СССР. Программа, записанная на этом языке, представляет собой матрицу, элементами которой являются операторы, среди которых имеются операторы настройки, производящие изменение коммутаторов элементарных машин (ЭМ) либо параметров, управляющих структурой ЭМ; операторы обмена информацией между ЭМ и "пустые" операторы, пропускающие выполнение одного шага вычислений. Каждый столбец матрицы включает независимые операторы, которые можно выполнять параллельно. Процесс выполнения программы сводится к последовательному прохождению всех столбцов матрицы. Основной принцип последовательного программирования – явное указание порядка выполнения операций – в Р-языке остается, однако здесь вводится двухкоординатная система записи, где одна координата указывает последовательность выполнения операций во времени, другая – распределение операций между ветвями вычислений. Р-язык, однако, не позволяет сохранить природную асинхронность задач и требует учитывать структуру конкретной вычислительной системы. Статус процесса указывает, готов ли… |
Статус процесса |


Рис. 7.5. Структура записи процесса
Статус процесса указывает, готов ли процесс к обработке или он ждет выполнения некоторого условия.
Действия управляющей процедуры сводятся к обработке этих записей. Рассмотрим некоторые события процесса и действия управляющей процедуры на эти события (табл. 7.1)
Таблица 7.1. Примеры действий управляющей процедуры
|
№ п/п |
Событие процесса |
Параметры эффективности системы прерыванияДля сравнения различных СПП используются чаще всего следующие параметры их функционирования: * время реакции – время между появлением запроса на прерывание и началом выполнения первой команды прерывающей программы (tр). Так как tр зависит от приоритета программы, то для характеристики системы используют время реакции для программы с наивысшим приоритетом; * время обслуживания прерывания – разность между полным временем выполнения прерывающей программы (tпр) и временем выполнения всех полезных команд (tп), т. е. tобс = tз + tв; * удельный вес прерывающих программ  * глубина прерывания – максимальное число программ, которые могут прерывать друг друга. Возможны случаи: - только один запрос воспринимается системой; - глубина прерывания фиксирована (n0); - программы могут сколько угодно раз прерывать друг друга. Схема прерывания при выполнении прерывающих программ изображена на рис. 6.2.
Рис. 6.2. Запросы прерывания: а – система с нулевой глубиной прерывания; б – система с глубиной прерывания, равной 2 Ясно, чем больше глубина прерывания, тем лучше можно учесть приоритетное обслуживание. Так, если при глубине прерывания n0 пришла n0+1-я программа, когда выполняется n-е прерывание, причем n0+1-я программа с наивысшим приоритетом, то она будет принята к исполнению только после выполнения n0-й программы; · насыщение системы прерывания. Если tp или tп запроса настолько велики, что запрос окажется необслуженным к моменту прихода нового запроса от того же устройства, то возникает явление, называемое насыщением системы прерывания. В этом случае факт посылки предыдущего запроса от данного источника будет утрачен. Параметры системы должны быть так согласованы, чтобы насыщение системы не наступило. Pentium | 25
25 25 33 20 25 33 33 50 50 66 75 100 60 66 90 100 120 133 | 39
41 49 68 78 100 136 166 231 249 297 319 435 510 567 735 815 1000 1200 |

реализация была рассчитана на работу с тактовой частотой 60 и 66 МГц. Но позже появились процессоры Pentium, работающие с тактовой частотой 75, 90, 100 и 120 МГц. Процессор Pentium по сравнению со своими предшественниками обладает целым рядом улучшенных характеристик. Главными его особенностями являются:
· двухпотоковая суперскалярная организация, допускающая параллельное выполнение пары простых команд;
· наличие двух независимых двухканальных множественно-ассо-циативных кэшей для команд и для данных, обеспечивающих выборку данных для двух операций в каждом такте;
· динамическое прогнозирование переходов;
· конвейерная организация устройства плавающей точки с 8 ступенями;
· двоичная совместимость с существующими процессорами семей-
ства 80x86.
Прежде всего новая микроархитектура этого процессора базируется на идее суперскалярной обработки (с некоторыми ограничениями). Основные команды распределяются по двум независимым исполнительным устройствам (конвейерам U и V). Конвейер U может выполнять любые команды семейства x86, включая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная – в конвейер V. Такая попарная выдача команд возможна только для ограниченного подмножества целочисленных команд. Команды арифметики с плавающей точкой не могут запускаться в паре с целочисленными командами. Одновременная выдача двух команд возможна только при отсутствии зависимостей по регистрам. При остановке команды по любой причине в одном конвейере, как правило, останавливается и второй конвейер.
Остальные устройства процессора предназначены для снабжения конвейеров необходимыми командами и данными. В отличие от процессоров i486 в процессоре Pentium используется раздельная кэш-память команд и данных емкостью по 8 Кб, что обеспечивает независимость обращений. За один такт из каждой кэш-памяти могут считываться два слова. При этом кэш-память данных построена на принципах двукратного расслоения, что обеспечивает одновременное считывание двух слов, принадлежащих одной строке кэш-памяти. Кэш-память команд хранит сразу три копии тегов, что позволяет в одном такте считывать два командных слова, принадлежащих либо одной строке, либо смежным строкам для обеспечения попарной выдачи команд, при этом третья копия тегов используется для организации протокола наблюдения за когерентностью состояния кэш-памяти. Для повышения эффективности перезагрузки кэш-памяти в процессоре применяется 64-битовая внешняя шина данных.
В процессоре предусмотрен механизм динамического прогнозирования направления переходов. С этой целью на кристалле размещена небольшая кэш-память, которая называется буфером целевых адресов переходов (BTB), и две независимые пары буферов предварительной выборки команд (по два 32-битовых буфера на каждый конвейер). Буфер целевых адресов переходов хранит адреса команд, которые находятся в буферах предварительной выборки. Работа буферов предварительной выборки организована таким образом, что в каждый момент времени осуществляется выборка команд только в один из буферов соответствующей пары. При обнаружении в потоке команд операции перехода вычисленный адрес перехода сравнивается с адресами, хранящимися в буфере BTB. В случае совпадения предсказывается, что переход будет выполнен, и разрешается работа другого буфера предварительной выборки, который начинает выдавать команды для выполнения в соответствующий конвейер. При несовпадении считается, что переход выполняться не будет и буфер предварительной выборки не переключается, продолжая обычный порядок выдачи команд.
Это позволяет избежать простоев конвейеров при правильном прогнозе направления перехода. Окончательное решение о направлении перехода, естественно, принимается на основании анализа кода условия. При неправильно сделанном прогнозе содержимое конвейеров аннулируется и выдача команд начинается с необходимого адреса. Неправильный прогноз приводит к приостановке работы конвейеров на 3 – 4 такта.
Следует отметить, что возросшая производительность процессора Pentium требует и соответствующей организации системы на его основе. Компания Intel разработала и поставляет все необходимые для этого наборы микросхем. Прежде всего для согласования скорости с динамической основной памятью необходима кэш-память второго уровня. Контроллер кэш-памяти 82496 и микросхемы статической памяти 82491 обеспечивают построение такой кэш-памяти объемом 256 Кб и работу процессора без тактов ожидания. Для эффективной организации систем Intel разработала стандарт на высокопроизводительную локальную шину PCI. Выпускаются наборы микросхем для построения мощных компьютеров на ее основе.
В настоящее время компания Intel разработала новый процессор, продолжающий архитектурную линию x86. Этот процессор получил название P6. Число транзисторов в новом кристалле составляет 4 – 5 миллионов, что обеспечивает повышение производительности до уровня 200 MIPS (66 МГц Pentium имеет производительность 112 MIPS). Для достижения такой производительности используются технические решения, широко применяющиеся при построении RISC-процессоров:
· выполнение команд не в предписанной программой последовательности, что устраняет во многих случаях приостановку конвейеров из-за ожидания операндов операций;
· использование методики переименования регистров, позволяющей увеличивать эффективный размер регистрового файла (малое количество регистров – одно из самых узких мест архитектуры x86);
· расширение суперскалярных возможностей по отношению к процессору Pentium, в котором обеспечивается одновременная выдача только двух команд с достаточно жесткими ограничениями на их комбинации.
Кроме того, в разработку нового поколения процессоров x86 включились компании, ранее занимавшиеся изготовлением Intel-совместимых процессоров. Это компании Advanced Micro Devices (AMD), Cyrix Corp и NexGen. С точки зрения микроархитектуры наиболее близок к Pentium процессор М1 компании Cyrix. Так же как и Pentium, он имеет два конвейера и может выполнять до двух команд в одном такте. Однако в процессоре М1 число случаев, когда операции могут выполняться попарно, значительно увеличено. Кроме того, в нем применяется методика обходов и ускорения пересылки данных, позволяющая устранить приостановку конвейеров во многих ситуациях, с которыми не справляется Pentium. Процессор содержит 32 физических регистра (вместо 8 логических, предусмотренных архитектурой x86) и применяет методику переименования регистров для устранения зависимостей по данным. Как и Pentium, процессор M1 для прогнозирования направления перехода использует буфер целевых адресов перехода емкостью 256 элементов, но, кроме того, поддерживает специальный стек возвратов, отслеживающий вызовы процедур и последующие возвраты.
Основа процессоров К5 компании AMD и Nx586 компании NexGen – очень быстрое RISC-ядро, выполняющее высокорегулярные операции в суперскалярном режиме. Внутренние форматы команд (ROP у компании AMD и RISC86 у компании NexGen) соответствуют традиционным системам команд RISC-процессоров. Все команды имеют одинаковую длину и кодируются в регулярном формате. Обращения к памяти выполняются специальными командами загрузки и записи. Как известно, архитектура x86 имеет очень сложную для декодирования систему команд. В процессорах K5 и Nx586 осуществляется аппаратная трансляция команд x86 в команды внутреннего формата, что дает лучшие условия для распараллеливания вычислений. В процессоре К5 имеется 40, а в процессоре Nx586 – 22 физических регистра, которые реализуют методику переименования. В процессоре К5 информация, необходимая для прогнозирования направления перехода, записывается прямо в кэш команд и хранится вместе с каждой строкой кэш-памяти.
В процессоре Nx586 для этих целей используется кэш-память адресов переходов на 96 элементов.
Таким образом, компания Intel больше не обладает монополией на методы конструирования высокопроизводительных процессоров x86, и можно ожидать появления новых процессоров, не только не уступающих, но и, возможно, превосходящих по производительности процессоры компании, стоявшей у истоков этой архитектуры. Следует отметить, что сама компания Intel заключила стратегическое соглашение с компанией Hewlett Packard на разработку следующего поколения микропроцессоров, в которых архитектура x86 будет сочетаться с архитектурой очень длинного командного слова (VLIW-архитектурой). Появление этих микропроцесоров ожидается в ближайшие годы.
С 1999 г. в качестве настольных процессоров базового уровня планируется использовать процессоры Celeron (фирма Intel), начиная с частоты 366 МГц. В массовых персональных компьютерах, рабочих станциях и серверах предполагается применение процессоров Katmai и Tanner с частотой 500 МГц, а затем ожидается переход на процессоры Cascades и Coppermine, исполненные по новой 0,18-мкм технологии.
В связи с развитием e-mail и Internet фирма Intel остается на переднем крае разработки процессоров, высокий уровень производительности которых будет отвечать растущим требованиям различных современных приложений.
Планирование по наивысшему приоритету
В этом методе HPF (highest priority first) процессор предоставляется тому процессу, который имеет наивысший приоритет. И если не допускается вытеснение процесса, то он выполняется до тех пор, пока не выполнится или не будет заблокирован. Если вытеснение разрешено, то поступивший процесс с более высоким приоритетом прервет выполняющийся процесс и ему будет передано управление на выполнение. Вытесненный процесс перейдет в очередь готовых процессов. Если процессор освободился, то ему из Ог назначается процесс с наивысшим приоритетом.
Если очередь Ог рассортирована по приоритетам, то выбрать первый элемент просто. Если же такой сортировки нет (а при динамическом изменении приоритетов ее всегда нет), необходимо по истечении некоторого времени T проводить сортировку всей очереди Ог или его некоторой части. Здесь возможны различные модификации.
В стратегии HPF необходимо задать те параметры, которые лягут в основу формирования приоритета. Иногда выбирается первым самое короткое задание SJF (shortest job first). Здесь, как правило, используется ожидаемое время выполнения процесса, ибо точное время известно очень редко. При этом надо помнить, что некоторые пользователи занижают время выполнения процесса.
В SJF возможны также варианты с вытеснением. В этом случае надо следить, чтобы не слишком часто процессы вытесняли друг друга, ибо и на вытеснение нужно процессорное время. Кроме того, если до завершения процесса осталось мало времени, то его вытеснять не рекомендуется. Однако здесь (особенно если разрешено вытеснение) особое внимание должно быть обращено на выполнение частично обработанных процессов.
В задачах планирования необходимо предусмотреть обеспечение занятости внешних устройств. С этой целью процессам можно присваивать высокий приоритет в периоды интенсивного использования ими ввода-вывода.
Количество различных правил вычисления приоритета неограничено. Стратегия дает многим процессам хорошее обслуживание, тем не менее процессы с низким приоритетом могут ждать очень долго. Это во многих случаях неприемлемо, например, при работе в режиме реального времени.
Планирование в мультипрограммных системах
Все задания (процессы), находящиеся в системе с мультипрограммированием, конкурируют из-за процессорного времени. Кроме процессов пользователя, имеются и системные процессы, для выполнения которых нужно процессорное время. Имеются, как правило, две очереди процессов:
· очередь готовых процессов – активные процессы, ожидающие кванта времени ЦП (Ог);
· очередь заблокированных процессов, ожидающих выполнения какого-нибудь события (Об).
 |
Пусть P – процессор, тогда схема планирования ресурса-процессора выглядит следующим образом (рис. 12.3).
Рис. 12.3. Схема планирования ресурса
Каждый процесс Pi
может находиться в одном из состояний: готовом, заблокированном или выполняемом. Если piÎ Ог и ему выделен квант tpi
процессорного времени, то он будет выполняться, пока не произойдет одно из событий:
· истечет его квант времени;
· процесс будет заблокирован;
· процесс будет вытеснен более приоритетным процессом;
· процесс будет завершен.
Если произошло одно из указанных событий, процесс переводится либо в очередь Ог, либо в очередь Об, либо оставляет систему. По окончании блокировки процессы переводятся из очереди Об в Ог. Алгоритм планирования для такой системы включает в себя способ выбора готового процесса из заданной совокупности процессов и способ вычисления величины кванта tpi
для него.
Каждому pi Î Ог поставлен в соответствие приоритет – целое число, учитывающее важность процесса pi, занимаемый им объем памяти, срочность выполнения и объем I/О, а также внешний приоритет, назначаемый пользователем. На определение приоритета влияют также и динамические характеристики: общее время ожидания; ресурсы, находящиеся в распоряжении процесса; процессорное время, полученное в последний раз; общее время нахождения процесса в системе и т. д. Отсюда следует, что приоритет процесса может перевычисляться несколько раз за время его жизни.
Внешний приоритет играет важную роль при переводе pi в активное состояние и распечатке полученных результатов.
Такие системные процессы, как учет, управление стандартными программами, выполняются так же, как и задания пользователей. Но многие из них (например, управление освободившимся внешним устройством, перекачка страниц памяти, обслуживание прерываний и некоторые другие) должны иметь привилегии, позволяющие им быстрее получать процессорное время. Все алгоритмы планирования должны учитывать привилегированные процессы, а также тот факт, что ни один процесс в системе не должен ждать бесконечно долго. Система должна планировать процессы так, чтобы свести к минимуму средние потери или ограничить максимальные потери по всем заданиям, что не всегда согласуется с эффективным использованием всех компонент системы.
Почтовые ящики
Почтовый ящик – это информационная структура с заданием правил, описывающих его работу. Она состоит из главного элемента, где располагается описание почтового ящика, и нескольких гнезд заданных размеров для размещения сообщений.
Если процесс p1 желает послать процессу p2 некоторое сообщение, он записывает его в одно из гнезд почтового ящика, откуда p2 в требуемый момент времени может его извлечь. Иногда оказывается необходимым процессу p1 получить подтверждение, что p2 принял переданное сообщение. Тогда образуются почтовые ящики с двусторонней связью. Известны и другие модификации почтовых ящиков, в частности порты, многовходовые почтовые ящики ит. д. Для установления связей между процессами широко используются почтовые ящики. Примером такого применения может служить операционная система IPMX86 ВС фирмы Intel для вычислительных комплексов на основе микропроцессоров IAPX86 или IAPX88. Для целей синхронизации разрабатываются специальные примитивы создания и уничтожения почтовых ящиков, отправки и запроса сообщений.
Можно выделить три типа имеющихся в системе запросов: с ожиданием (ограниченным и неограниченным) или без ожидания. В случае ограниченного ожидания процесс, издавший запрос, если почтовый ящик пуст, ожидает некоторое время поступления сообщения. Если по истечении заданного кванта времени сообщение в почтовый ящик не поступило, процесс активизируется и выдает уведомление, что запрос не обслужен. В случае запроса без ожидания, если почтовый ящик пуст, указанные действия выполняются немедленно. Если время ожидания неограничено, процесс не активизируется до поступления сообщения в почтовый ящик.
Очевидно, что почтовые ящики позволяют осуществлять как обмен информацией между процессами, так и их синхронизацию.
ПОНЯТИЕ АРХИТЕКТУРЫ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ
Появление серийно выпускаемых сверхбольших надежных и дешевых интегральных схем, массовое производство микропроцессоров, возобновившийся интерес к разработке языков программирования и программного обеспечения порождают возможность при проектировании компьютеров качественно продвинуться вперед за счет улучшения программно?аппаратного интерфейса, т.е. семантической связи между возможностями аппаратных средств современных ЭВМ и их программного обеспечения. Организация вычислительной системы (ВС) на этом уровне лежит в основе понятия "архитектура". Для неспециалистов в области программного обеспечения термин "архитектура" ассоциируется, как правило, со строительными объектами. И здесь, как увидим далее, есть много общего.
Действительно, архитектура компьютера, характеризующая его логическую организацию, может быть представлена как множество взаимосвязанных компонент, включающих, на первый взгляд, элементы различной природы: программное обеспечение (software), аппаратное обеспечение (hardware), алгоритмическое обеспечение (brainware), специальное фирменное обеспечение (firmware) – и поддерживающих его слаженное функционирование в форме единого архитектурного ансамбля, позволяющего вести эффективную обработку различных объектов.
С другой стороны, архитектура может быть задана как абстрактное многоуровневое представление физической системы с точки зрения программиста, с закреплением функций за каждым уровнем и установлением интерфейса между различными уровнями.
Знание особенностей разнообразных архитектурных решений дает возможность пользователям компьютеров эффективно распоряжаться всеми предоставляемыми ресурсами, осуществляя их направленный выбор и тем самым повышая эффективность обработки данных.
Понятие мультипрограммирования
Требования, которые предъявляются различными заданиями к ресурсам, необычайно разнообразны. Оптимально использовать их даже при тщательном планировании заданий невозможно. Скажем, если речь идет об оперативной памяти, то любая ее часть, не занятая какими-то системными блоками или текущим заданием, это уже потерянные ресурсы. В случае же раздельных процессоров – центрального и ввода-вывода для заданий с ограниченным вводом-выводом или небольшими вычислениями, процессоры могут простаивать. Выход из создавшегося положения позволяет найти одновременное присутствие в компьютере в активном состоянии нескольких заданий и распределение имеющихся ресурсов между этими заданиями. Тогда, если какое-то задание требует процессора ввода-вывода, то центральный процессор может быть переключен на обработку другого задания. При такой организации несколько заданий по частям выполняется одновременно в системе, а центральный процессор какие-то кванты времени тратит на выполнение каждого из них. Такая схема работы называется мультипрограммированием. Главная цель такой схемы – компенсировать различие в скоростях работы между центральным процессором и процессором ввода-вывода.
Пример. Пусть в системе с мультипрограммированием присутствуют три задания P1, P2, P3 c параметрами
P1 (C1,I/O1, M1), P2 (C2, I/O2, M2), P3(C3, I/O3, M3),
где Сi – процессорное время; I/Oi – время ввода-вывода; Mi – требуемая ОП.
Пусть общий объем ОП для выполнения трех заданий равен 100 К.
Если бы при заданных ресурсах выполнялось только задание P1, то мы не использовали бы 80 К памяти, кроме того, центральный процессор (ЦП) простаивал бы в течение времени I/O1. В случае же обработки трех процессов память используется полностью, а при выполнении I/O1 мы ЦП передали бы второму процессу, затем третьему, и, следовательно, максимальный простой ЦП достигал бы лишь t = I/O1-(C2 + C3) вместо I/О1. Таким образом, за время, необходимое для выполнения одного процесса в однопрограммном режиме, мы можем выполнить два и более заданий в режиме мультипрограммирования.
Однако такая ситуация возникает лишь для простой модели, описанной на рис. 12.1. В общем случае при обработке процессов время работы ЦП и I/О регулярно перемежается, что создает более трудные взаимодействия
 |
Рис. 12.1. Простое взаимодействие процессов
Рис. 12.2. Сложное взаимодействие заданий
На рис.12.2 представлена ситуация сложного взаимодействия заданий. Как только процесс P1 захочет выполнить ввод-вывод I/О14, то окажется, что процесс P2 ждет ввод-вывод I/О23. Таким образом, удалось совместить I/О12 с C21, C13 с I/О22, но ЦП будет простаивать, пока не завершится I/О14
или I/О23. Естественно, обобщенная модель ВС должна простаивать только в том случае, если все находящиеся в активном состоянии процессы одновременно запросили ввод-вывод. Ясно, что чем больше процессов одновременно находится в активном состоянии, тем меньше вероятность потери производительности ВС из-за ожидания ввода-вывода. Однако, чтобы процессы находились в активном состоянии, они должны быть в оперативной памяти, объем которой ограничен. Это следует учитывать при выборе стратегий распределения памяти.
Пусть Ma – множество процессов, находящихся в активном состоянии. При наполнении Ma
необходимо стремиться к тому, чтобы среди них были процессы с большой "вычислительной" частью, занимающие мало памяти (или легко поддающиеся сегментации), использующие НМД и НМЛ, что позволит оптимальнее обеспечить занятость всех компонент системы. Однако оптимальное решение этой задачи известно только для некоторых простых случаев.
Понятие процесса и состояния
Создавать современные операционные системы без теоретической базы стало затруднительно, так как невозможно повторить условия, приведшие к ошибке во время работы, а следовательно, выявить ее источник. Все это привело к появлению понятия процесса. Понятие "процесс" в последнее время встречается в литературе по операционным системам довольно часто, однако вкладываемый в это понятие смысл иногда сильно различается. Мы будем пользоваться следующим определением.
Процесс есть тройка (Q, f, g), где Q – множество состояний процесса; f– функция действия f : Q ® Q; g Í Q – начальное состояние процесса.
Действия, реализуемые процессом, будем рассматривать как результат выполнения некоторой программы на реальном (виртуальном) процессоре.
Перечислим некоторые свойства процесса:
* процесс не является закрытой системой и может взаимодействовать с другими процессами, воспринимая или изменяя часть среды, которую он с ними разделяет;
* каждый процесс живет лишь временно. Имеется и "главный" процесс, выполняемый вручную при включении компьютера, который начинает всю цепочку процессов;
* в любой момент процесс может быть описан его состоянием. Все параметры (переменные), характеризующие текущее состояние процесса, объ-единяются в "вектор состояний" или "слово состояний", которые позволяют возобновить процесс после его прерывания, в том числе и локальную среду.
Цикл жизни процесса может быть представлен как переход его из одного состояния в другое.
Пример. Пусть заданы три процесса (задания пользователя), одновременно присутствующие в системе с мультипрограммированием. И пусть каждый из них может находиться в трех состояниях: ожидание, готовность, выполнение.
Опишем эти состояния.
ОЖИДАНИЕ. Процесс ожидает выполнения какого-либо события (например, завершения операции I/0).
ГОТОВНОСТЬ. Процесс готов к выполнению, но процессов больше, чем процессоров, и он должен ждать своей очереди.
ВЫПОЛНЕНИЕ. Процессору выделены все ресурсы, в том числе и процессор, и его программы выполняются в настоящее время.
Схема на рис. 7.1. предполагает, что процессы уже существовали в памяти компьютера и будут существовать всегда. На практике пользователь должен эти процессы (задания) предоставить системе. Тогда реальная схема будет выглядеть так (рис. 7.2). Здесь дополнительно введены состояния: предоставление, хранение и завершение. Поясним их.
 |
Рис. 7.2. Полная схема обработки процесса
ПРЕДОСТАВЛЕНИЕ. Пользователь предоставляет задание системе, на которое она должна отреагировать.
ХРАНЕНИЕ. Задание преобразовано во внутреннюю форму, понятную компьютеру, но ресурсы еще не выделены (например, задание записано на диск). Процесс в случае выделения ресурсов переходит в состояние
готовности.
ЗАВЕРШЕНИЕ. Процесс завершил свои вычисления и все выделенные процессу ресурсы могут быть освобождены и возвращены системе.
Предпосылки создания систем параллельного действия
Развитие теории и практики проектирования компьютеров и их математического обеспечения (МО) показало, что существующие компьютеры уже не удовлетворяют потребностям пользователей в решении задач производства и науки. В связи с этим все изыскания в области вычислительной техники направлены на создание новых, более перспективных компьютеров.
ЭВМ и их МО являются на сегодня, пожалуй, самыми дорогостоящими продуктами производства, поэтому эффективность их применения требует бóльшего внимания. Работа современных ЭВМ в пакетном режиме использует это дорогостоящее оборудование крайне неэффективно. Речь идет не только о том, что простои оборудования в среднем достигают 50 %, но и о том, что половина оставшегося времени идет на отладку программ. Если сюда присовокупить время на процессы трансляции, сборки, редактирования связей – необходимые этапы подготовки задачи к счету, то доля полезного времени для обработки данных по отлаженной программе окажется совсем незначительной.
За время развития вычислительной техники накладные расходы на каждую с пользой выполненную команду программы выросли на 3–4 порядка. (Раньше роль транслятора, сборщика, редактора играл сам программист.) Созданные за это время средства автоматизации проектирования программ и их подготовки к обработке лишь в 40–50 раз повышают производительность работы программиста. Поэтому проблема изменения соотношения времени, затрачиваемого ЭВМ на подготовку задач и на получение "полезных результатов" в пользу последнего, является актуальной.
Изменение указанного соотношения можно осуществить через преобразование структуры компьютера.
Для универсальных ЭВМ характерен широкий набор команд и данных. Во время трансляции, например, главным образом используется небольшое подмножество этих команд, связанное с преобразованием текстов. Возможности АУ по выполнению арифметических операций с плавающей точкой и удвоенной точностью не используются, при выполнении вычислений все обстоит наоборот. Что касается операции ввода-вывода, то на разных этапах ее используются только определенные возможности компьютера.
Поэтому целесообразно иметь хотя бы два процессора в ЭВМ: один использовать только для обработки данных, а другой – для подготовительных работ. Основная трудность двухпроцессорной организации заключается в сбалансировании ее работы. Аналогичную картину можно проследить с использованием памяти, отдельные участки которой простаивают длительное время из-за отсутствия к ним обращений. При анализе динамики обращений к памяти при решении некоторых классов вычислительных задач было установлено, что ОЗУ активно используется лишь на 10–15 %.
Другим фактором, сдерживающим эффективное использование оборудования, является последовательный характер проектируемых алгоритмов.
Можно показать, что существует возможность построить такой компьютер (гипотетический, разумеется), что любой заданный алгоритм можно будет обрабатывать параллельно. Идею доказательства такой возможности продемонстрируем на конкретном примере.
Пусть надо вычислить значение r по формуле
r = x + y • z. |
(*) |
ri = r (x1, x2, ..., xn, y1, y2, ..., yn, z1, z2, ..., zn),
где xi, yi, zi, – двоичные разряды, представляющие возможные значения x, y, z.
Так как любая функция (вычисление любого разряда ri) i =

Ясно, что подобные рассуждения носят абстрактный характер и ими трудно воспользоваться на практике, ибо количество конкретных алгоритмов – бесконечное множество. Но тем не менее подобный подход позволяет рассматривать с общих позиций попытку реализовать вычислительные среды – многопроцессорные системы, динамически настраиваемые на конкретный алгоритм. Принципиальная возможность распараллелить любой алгоритм оправдывает те усилия, которые предпринимаются сегодня для решения этой задачи.
Структура и архитектура наиболее распространенных сегодня компьютеров ориентированы на алгоритм, как на некоторую последовательность конструктивных действий, в связи с чем они слабо приспособлены для реализации параллельных вычислений.
Технические предпосылки для создания МВС накапливались постепенно. Скажем, идея комплексирования ЭВМ через общую память была апробирована в многомашинном комплексе "Минск-222" в 1966 г. Внутри машин ряда I серии ЕС ЭВМ были заложены основы комплексирования ЭВМ, правда, с некоторыми ограничениями. Более широкие возможности комплексирования ЭВМ серии ЕС представлены в машинах ряда 2 и 3.
Можно выделить три основных направления по созданию машин следующих поколений.
1. Эволюционное направление. Оно связано с совершенствованием ЭВМ и их МО в плане развития связи с удаленными терминалами и выхода в сети передачи данных, расширения спектра виртуальных операционных окружений, что позволяет использовать их в многомашинных комплексах (МК) и компьютерных сетях.
2. Создание новых структур – МВС. При этом внутреннюю систему команд компьютеров приближают к языкам высокого уровня.
3. Разработка и создание перестраиваемых однородных МВС, пригодных для решения задач, распараллеливаемых на уровне входных алгоритмов. В них, например, центральная ВС может состоять из "однородного управляющего поля" и "однородного решающего поля". Каждое поле представляет собой набор однотипных специализированных блоков, выполненных на микроэлементной интегральной базе.Элементы управляющего поля независимо занимаются обработкой команд. Блоки управляющего поля могут одновременно обрабатывать команды различных программ, выбирая их из разных областей общей памяти. Блок, по существу, представляет собой УУ обычной ЭВМ, которое выбирает команду, дешифрирует ее, вычисляет исполнительный адрес, выбирает операнд и т. д.
Решающее поле состоит из однотипных элементов и представляет собой АУ, способное выполнять арифметические и логические операции над некоторыми типами данных.
Преобразование последовательных программ в последовательно-параллельные
Задача распараллеливания. В любом полном рассмотрении вопросов параллельного программирования должны быть представлены способы получения параллельной программы из обычной алгоритмической записи, которая несет в себе след чисто последовательной логики рассуждений, так как любые вычисления, проводимые вручную и автоматически, выполнялись последовательно. Однако оказывается, что любой реальный процесс при детальном его рассмотрении выполняется параллельно. И чем внимательнее и детальнее мы постараемся его описать, тем больше это описание будет приближаться к параллельной форме. Следовательно, задача состоит в том, чтобы с помощью каких-то понятий научиться достаточно просто и полно описывать естественные параллельные процессы.
Сложность задачи распараллеливания во многом определяется языком, на котором записан исходный алгоритм. Наиболее просто это делать, если язык не содержит циклических структур. Примером таких языков можно назвать языки "геометрического описания деталей со сложной объемной конфигурацией". Это язык, в котором предложение – последовательность директив.
Как правило, основное время выполнения программ на обычных языках связано с реализацией циклов. Поэтому важной задачей является распараллеливание циклов.
Как указывалось выше, некоторые языки программирования имеют средства для описания параллелизма. Однако все параллельные фрагменты программы должны быть указаны явным образом. Более того, должна быть указана последовательность их выполнения, организована передача необходимых управлений и т. д.
При использовании языка PL/1, например, программист должен:
· выделить и пометить независимые фрагменты программы (с помощью операторов CALL и TASK, например);
· обеспечить синхронизацию при выполнении фрагментов (используя, скажем, оператор DELAY);
· осуществить взаимное управление фрагментами (операторы COMPLETE, WAIT, RETURN).
Следовательно, все трудности по организации параллельной обработки ложатся на программиста, так как он, по-существу, должен предварительно написать весь "сценарий" прохождения задачи через компьютер в параллельном режиме.
На разработку математического и программного обеспечения, согласно различным литературным источникам, тратится от 70 до 90 % всех затрат на создание ВС. Это одна из основных причин, почему необходимо эффективно использовать накопившееся обеспечение для однопроцессорных ЭВМ при переходе к МВС. Математическое и программное обеспечение следует адаптировать для новых ВС. Таким образом, рождается актуальная проблема – преобразование последовательных программ в последовательно-парал-лельные. Но так как эта работа необычайно трудоемка, ее следует автоматизировать. Решение указанной проблемы позволяет, во-первых, высвободить большие трудовые ресурсы, во-вторых, использовать накопленный за долгие годы развития ЭВМ информационно-программный багаж без ручного перепрограммирования и, в-третьих, осуществить переход на многопроцессорные системы с меньшими затратами труда и времени.
Распараллеливание программ можно осуществлять как на уровне отдельных задач, так и на уровне отдельных процедур, операторов, операций и микроопераций. Целесообразность преобразования на указанных уровнях должна решаться в каждом отдельном случае в зависимости от структуры ВС, типа программы и цели, которая ставится при ее решении.
Рассмотрим общую схему преобразования последовательных программ в последовательно-параллельные. Организовать параллельные вычисления можно с помощью некоторой формальной процедуры, выполняемой автоматически над каждой программой, состоящей из последовательности операторов обычного ЯП. Эта процедура позволяет избавить программиста от анализа собственной программы и помогает выявить ее внутренний параллелизм. Выявление параллелизма заключается в разбиении всех операторов программ на два класса: тех, которые могут выполняться параллельно, и тех, которые должны быть завершены прежде, чем следующие последовательности операторов начнут выполняться.
Такой подход к распараллеливанию основывается на представлении программы в виде ориентированного графа G, множество вершин которого V = {v1, v2, ..., vn} соответствует либо отдельным операторам программы, либо совокупности этих операторов (типа подпрограмм в языке ФОРТРАН либо процедур в языке АЛГОЛ или ПАСКАЛЬ).
Множество направленных дуг U = {u1, u2, ..., um} соответствует возможным переходам между операторами программы.
Из теории графов известно, что ориентированный граф полностью описывается соответствующей матрицей смежности такой, что ее элемент
|
ì 1, если существует дуга (ui,uj); |
|
|
Сij = |
í |
|
|
î 0, если такой дуги нет. |
 |
Рис. 10.3. Сильносвязный подграф
Подграфу, представляющему собой последовательность различных вершин, каждая из которых имеет единственную входную и единственную выходную вершины, будем ставить в соответствие линейный участок в
программе.
Итак, ставится задача – преобразовать алгоритм решения задачи, заданный последовательной программой, для параллельной его реализации на многопроцессорной вычислительной системе.
Для преобразования программы из одной (последовательной) формы в другую (последовательно-параллельную) мы используем ее интерпретацию в виде орграфа. Вообще говоря, идея использовать некоторый "формализм" в качестве посредника для преобразования программ встречалась и раньше в связи с другими задачами. Так, в трансляторе системы АЛЬФА был введен дополнительный проход, во время которого по исходной программе строилась ее модель в виде схемы Лаврова, что позволило обнаруживать и анализировать информационные связи в целях глобальной экономии памяти.
Построим схему алгоритма распараллеливания программ, используя некоторые сведения из теории графов.
Примеры языков параллельного программирования
На сегодняшний день создано достаточно много языков параллельного программирования, однако трудно сказать, какой из них наиболее приемлем для использования. Все зависит от решаемой задачи, возможностей компьютера, целей, которые ставятся при этом, и ряда других факторов.
Ниже в качестве примеров ЯПП мы рассмотрим некоторые модельные языки, заложенные идеи в которых используют в большинстве современных языков параллельного программирования.
Приоритетное обслуживание прерываний
Аппарат приоритетов предназначен для повышения эффективности использования всех ресурсов ВС. Так, неэффективно одновременное выполнение двух заданий, каждое из которых требует большой загрузки устройств ввода-вывода и незначительно использует центральный процессор. Приоритет задания может назначаться исходя из: времени его выполнения ("короткие" задания имеют более высокий приоритет по сравнению с "длинными" заданиями); объема используемой оперативной памяти (задания, требующие большого объема памяти, не должны иметь одинаковый приоритет); интенсивности и объема использования других ресурсов ВС; срочности выполнения и т. д.
При программном распознавании причин прерывания прерывающая программа начинает анализ с тех запросов на прерывание, которые имеют более высокий приоритет. При этом в процессе работы мы можем программ-ным путем изменить приоритет запросов. При аппаратном распознавании причин прерывания указанные функции возлагаются на специальное обо-рудование.
Понятие приоритета в прерывании программ имеет два смысла. Предположим, что никаких ограничений на время поступления запросов прерывания не накладывается. При одновременном поступлении нескольких запросов для немедленного удовлетворения может быть принят только один. Этот тип приоритета, определяющий очередность рассмотрения запросов прерывания, называют приоритетом между запросами прерываний. Прерывающие программы, однако, могут иметь относительно текущей программы различную степень важности, и не любым запросом может быть прервана выполняющаяся программа. Чтобы иметь возможность прервать текущую программу, принятый СПП запрос должен соответствовать программе более важной, нежели выполняемая в данный момент. Этот тип приоритета определяет старшинство программ и его обычно называют приоритетом между прерывающими программами.
В случае простейшей аппаратной реализации приоритета между запросами прерывания может быть использован метод "последовательного поиска" (рис. 6.4).
Суть метода состоит в последовательном изменении содержимого счетчика от 0 до 2n
– 1 и просмотре всех 2n уровней прерывания до совпадения содержимого счетчика с номером уровня.
При одновременном появлении нескольких запросов жестко закрепляется запрос с уровня с меньшим номером. Метод "последовательного поиска" прост в реализации, но время реакции велико, так как в общем случае необходимо прохождение счетчиком всех 2n позиций, что при большом n может выходить за допустимые временные пределы. Особенно это важно при работе в режиме реального времени.
 |
Приоритет между прерывающими программами определяет, какие из программ могут прервать данную программу, а какие нет. Этот вид приоритета для многоуровневых систем с достаточной глубиной прерывания имеет гораздо большее значение, чем приоритет между запросами прерывания.
Пример. Пусть одновременно возникли три запроса, соответствующие трем уровням прерывания – № 1, № 2, № 3. Пусть по приоритету предпочтение отдается запросу с меньшим номером. Предположим, что приоритет между прерывающими программами, соответствующими указанным уровням, установлен в обратном порядке. Тогда в соответствии с приоритетами между запросами вначале процессор приступает к выполнению программы № 1, но, как только поиск запросов прерывания возобновится, запрос № 2 прервет выполнение программы № 1 и запустит программу № 2. Аналогично последняя прервется программой № 3, которая и выполняется первой.
Таким образом, приоритет между запросами прерывания нужен лишь для выбора одного запроса из многих, а приоритет между прерывающими программами определяет фактический порядок выполнения программ.
Так как степень важности программ, их объем, требуемые ресурсы и т. д. могут изменяться в ходе вычислительного процесса, то только приоритеты между запросами прерывания могут быть строго зафиксированы. Приоритеты же между прерывающими программами должны быть программно-управляемыми.
Маска прерывания. Маска – шаблонная последовательность знаков, управляющая сохранением или исключением отдельных частей другой последовательности знаков.
В простейшем виде маска – это двоичное число, каждый разряд которого соответствует одному из уровней прерывания и разрешает (например, состояние "1") или запрещает (состояние "0") прерывание от запросов, относящихся к данному уровню. Управление приоритетом находится полностью в распоряжении программы. Для каждой прерывающей программы может быть установлена своя маска, указывающая, какие программы способны ее прерывать. Каждый разряд маски соответствует отдельной программе. Маски всех программ хранятся в памяти. Если какая-нибудь программа вызывается для выполнения, то ее маска засылается в регистр маски. Физически маска реализуется обычно в виде триггерного регистра, состояние которого можно изменить программным путем. При формировании маски состояние "1" получают лишь те триггеры, которые соответствуют программам с более высоким, чем у данной программы, приоритетом.
В принципе нули и единицы в маске могут чередоваться в произвольном порядке, однако отсутствие упорядоченности влечет за собой дополнительные трудности:
* определение приоритета соответствующей программы;
* обход ситуации "зацикливание приоритетов".
При создании ситуации "зацикливание приоритетов" происходит поочередное выполнение нескольких команд каждой программы, что, естественно, резко увеличивает время обслуживания и снижает эффективность СПП.
Иногда создаются "групповые" маски, при которых каждый разряд воздействует на несколько уровней одновременно. Уровни прерываний, которые управляются одним разрядом маски прерывания, образуют "класс прерывания". Высшей степенью этой иерархии является главный триггер прерывания, выключающий (или включающий) всю СПП полностью.
В случае поступления запросов, запрещенных маской прерывания, СПП либо запоминает запрос, чтобы при снятии запрета удовлетворять его, либо игнорирует запрос, если его удовлетворение через время t может отрицательно повлиять на ход вычислительного процесса.Возможны и другие реакции СПП. В таком случае в маске на один уровень отводится более одного бита.
Проблема тупиков
Рассмотренные выше приемы синхронизации процессов, если ими при мультидоступе процессов к общим ресурсам пользоваться неосторожно, могут привести к ситуации, когда процессы блокируют друг друга и не могут выйти из состояния блокировки без принятия чрезвычайных мер очень долго, т. е. возникает критическая тупиковая ситуация.
Подобную ситуацию можно хорошо продемонстрировать на примере работы двух процессов p1 и p2 с одним читающим R1 и одним печатающим R2 устройствами.
Тупиковая ситуация возникает при мультипроцессировании, когда процессы p1, p2, ... , pn, заблокированные по одному и тому же ресурсу Zm, не могут быть разблокированы, так как их запросы на этот ресурс никогда не могут быть удовлетворены. Подобные конфликтные ситуации разрешаются либо ликвидацией процессов, зашедших в тупик, либо освобождением ресурса принудительным образом.
Комплекс программ, объединенных под общим названием ОБРА-БОТКА ТУПИКОВ (ОТП), как правило, выполняет следующие функции:
·
анализирует возможности избежания тупиков и предотвращает их, если возможно;
· определяет множество процессов, находящихся в состоянии тупика;
· определяет способы и принимает меры для выхода из тупика.
Одним из ключей к решению проблемы распознавания тупиков является наличие в графах типа "ресурс–процесс" цикла, т. е. направленного пути от некоторой вершины к ней самой.
Процессор MC компании Motorola
Процессор 88110 относится к разряду суперскалярных RISC-процессоров. Основные особенности этого процессора связаны с использованием принципов суперскалярной обработки, двух восьмипортовых регистровых файлов, десяти независимых исполнительных устройств, больших по объему внутренних кэшей и широких магистралей данных.
На рис.4.6 представлена блок-схема процессора, содержащего 1,3 млн вентилей. Центральной частью этой архитектуры является шина операндов (в
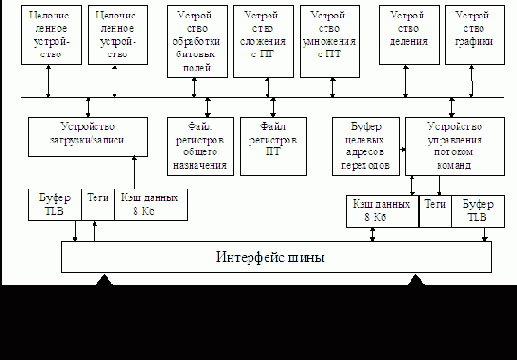 |
Рис 4.6. Блок-схема процессора MC 88110
реализации это шесть 80-битовых шин), соединяющая регистровые файлы и исполнительные устройства.
Процессор имеет 10 исполнительных устройств, которые работают одновременно и независимо, и два регистровых файла. Файл регистров общего назначения имеет 32-битовую организацию. Расширенные регистры плавающей точки имеют 80-битовую организацию. Эти регистровые файлы снабжены шестью портами чтения и двумя портами записи каждый.
Внешняя шина процессора имеет отдельные линии данных (64 бита) и адреса (32 бита), что позволяет реализовать быстрые групповые операции перезагрузки внутренней кэш-памяти. Внешняя шина имеет также специальные сигналы управления, обеспечивающие аппаратную поддержку когерентности кэш-памяти в мультипроцессорных конфигурациях.
В процессоре имеются две двухканальные множественно-ассо-циативные кэш-памяти емкостью по 8 Кб (для команд и для данных).
Суперскалярная архитектура процессора базируются на реализации возможности завершения команд не в порядке их поступления для выполнения, что позволяет существенно увеличить производительность, однако приводит к проблемам организации точного прерывания. Эта проблема решается в процессоре 88110 с помощью так называемого буфера истории, который хранит старые значения регистров при выполнении и завершении операций не в предписанном программой порядке и позволяет аппаратно восстановить необходимое состояние в случае прерывания.
В процессоре предусмотрено несколько способов ускорения обработки условных переходов.
Один из них, предсказание направления перехода, позволяет компилятору сообщить процессору предпочтительное направление перехода. Для предсказанного направления перехода разрешено условное выполнение команд. Если направление перехода предсказано неверно, исходное состояние процессора восстанавливается с помощью буфера истории. Выполнение программы в этом случае будет продолжено с "правильной" команды.
В каждом такте процессор может выдавать на выполнение две команды. В большинстве случаев выдача команд осуществляется в порядке, предписанном программой. Команды записи и условных переходов могут посылаться на буферные станции резервирования, из которых они в дальнейшем будут выданы на выполнение. Команды загрузки могут накапливаться в очереди. В устройстве загрузки-записи реализованы буфер загрузки FIFO на четыре строки и три станции резервирования операций записи, что позволяет иметь в каждый момент времени до четырех отложенных команд загрузки и до трех команд записи. Выполнение этих команд внутри устройства может переупорядочиваться для обеспечения большей эффективности.
При построении многопроцессорной системы все процессоры и основная память размещаются на одной плате. Для обеспечения хорошей производительности системы каждый процессор в такой конфигурации снабжается кэш-памятью второго уровня емкостью 256 Кб. Протокол поддержания когерентного состояния кэш-памяти (протокол наблюдения) базируется на методике записи с аннулированием, гарантирующей размещение модифицированной копии строки кэш-памяти только в одном из кэшей системы. Протокол позволяет нескольким процессорам иметь одну и ту же копию строки кэш-памяти. При этом, если один из процессоров выполняет запись в память (общую строку кэш-памяти), другие процессоры уведомляются о том, что их копии являются недействительными и должны быть аннулированы.
Процессоры PA-RISC компании Hewlett Packard
Основой разработки современных изделий Hewlett Packard является архитектура PA-RISC. Она была разработана компанией в 1986 г. и с тех пор прошла несколько стадий своего развития благодаря успехам интегральной технологии от многокристального до однокристального исполнения. В 1992 г. компания Hewlett Packard объявила о создании своего суперскалярного процессора PA-7100, который с тех пор стал основой построения семейства рабочих станций HP 9000 Series 700 и семейства бизнес-серверов HP 9000 Series 800. Имеются 33, 50 и 99 МГц реализации кристалла PA-7100. Кроме того, выпущены модифицированные, улучшенные по многим параметрам кристаллы PA-7100LC с тактовой частотой 64, 80 и 100 МГц и PA-7150 с тактовой частотой 125 МГц, а также PA-7200 с тактовой частотой 90 и 100 МГц. Компанией создан процессор следующего поколения HP-8000, который работает с тактовой частотой 200 МГц. Кроме того, Hewlett Packard в сотрудничестве с Intel создает новый процессор с очень длинным командным словом (VLIW-архитектура), который будет совместим как с семейством Intel x86, так и с семейством PA-RISC
Особенность архитектуры PA-RISC – внекристальная реализация кэша, что позволяет реализовать различные объемы кэш-памяти и оптимизировать конструкцию в зависимости от условий применения (рис. 4.4). Хранение команд и данных осуществляется в раздельных кэшах, причем процессор соединяется с ними с помощью высокоскоростных 64-битовых шин. Кэш-память реализуется на высокоскоростных кристаллах статической памяти (SRAM), синхронизация которых осуществляется непосредственно на тактовой частоте процессора. При тактовой частоте 100 МГц каждый кэш имеет полосу пропускания 800 Мб/с при выполнении операций считывания и 400 Мб/с при выполнении операций записи. Микропроцессор аппаратно поддерживает различный объем кэш-памяти: кэш команд может иметь объем от 4 Кб до 1 Мб, кэш данных – от 4 Кб до 2 Мб. Чтобы снизить коэффициент промахов, используется механизм хеширования адреса. В обоих кэшах для повышения надежности применяются дополнительные контрольные разряды, причем ошибки кэша команд корректируются аппаратными средствами.
вывода посредством синхронной шины. Процессор
Процессор подсоединяется к памяти и подсистеме ввода- вывода посредством синхронной шины. Процессор может работать с тремя разными отношениями внутренней и внешней тактовой частоты в зависимости от частоты внешней шины: 1:1, 3:2 и 2:1. Это позволяет использовать в системах разные по скорости микросхемы памяти.
 |
Конструктивно на кристалле PA-7100 размещены целочисленный процессор, процессор для обработки чисел с плавающей точкой, устройство управления кэшем, унифицированный буфер TLB, устройство управления, а также ряд интерфейсных схем.
 |
Рис. 4.5. Управление командами плавающей точки
Арифметико-логическое устройство выполняет операции сложения, вычитания и преобразования форматов данных. Регистровый файл состоит из 28 64-битовых регистров, каждый из которых может использоваться как два 32-битовых регистра для выполнения операций с плавающей точкой одинарной точности. Регистровый файл имеет пять портов чтения и три порта записи, которые обеспечивают одновременное выполнение операций умножения, сложения и загрузки-записи.
Большинство улучшений производительности процессора связано с увеличением тактовой частоты до 100 МГц по сравнению с 66 МГц у его предшественника.
Конвейер целочисленного устройства включает шесть ступеней: чтение из кэша команд (IR); чтение операндов (OR); выполнение-чтение из кэша данных (DR); завершение чтения кэша данных (DRC); запись в регистры (RW) и запись в кэш данных (DW). На ступени ID выполняется выборка команд. Реализация механизма выдачи двух команд требует небольшого буфера предварительной выборки, который обеспечивает предварительную выборку команд за два такта до начала работы ступени IR.
Во время выполнения на ступени OR все исполнительные устройства декодируют поля операндов в команде и начинают вычислять результат операции. На ступени DR целочисленное устройство завершает свою работу. Кроме того, кэш-память данных выполняет чтение, но данные не поступают до момента завершения работы ступени DRC. Результаты операций сложения (ADD) и умножения (MULTIPLY) также становятся достоверными в конце ступени DRC. Запись в универсальные регистры и регистры плавающей точки производится на ступени RW. Запись в кэш данных командами записи (STORE) требует двух тактов. Наиболее раннее двухтактное окно команды STORE возникает на ступенях RW и DW. Однако это окно может сдвигаться, поскольку записи в кэш данных происходят только тогда, когда появляется следующая команда записи. Операции деления и вычисления квадратного корня для чисел с плавающей точкой заканчиваются на много тактов позже ступени DW.
Конвейер проектировался в целях максимального увеличения времени, необходимого для выполнения чтения внешних кристаллов SRAM кэш-памяти данных. Это позволяет максимизировать частоту процессора при заданной скорости SRAM. Все команды загрузки (LOAD) выполняются за один такт и требуют только одного такта полосы пропускания кэш-памяти данных. Так как кэши команд и данных размещены на разных шинах, в конвейере отсутствуют какие-либо потери, связанные с конфликтами по обращениям в кэш данных и кэш команд.
Процессор может в каждом такте выдавать на выполнение одну целочисленную команду и одну команду плавающей точки. Полоса пропускания кэша команд достаточна для поддержания непрерывной выдачи двух команд в каждом такте. Отсутствуют какие-либо ограничения по выравниванию или порядку следования пары команд, которые выполняются вместе. Кроме того, отсутствуют потери тактов, связанных с переходом от выполнения двух команд на выполнение одной команды. Специальное внимание было уделено тому, чтобы выдача двух команд в одном такте не приводила к ограничению тактовой частоты. Для этого в кэше команд был реализован специальный декодируемый бит, чтобы отделить команды целочисленного устройства от команд устройства плавающей точки.
Этот бит предварительного декодирования минимизирует время, необходимое для правильного разделения команд.
Потери, связанные с зависимостями по данным и управлению, в этом конвейере минимальны. Команды загрузки выполняются за один такт, за исключением случая, когда последующая команда пользуется регистром-приемником команды LOAD. Как правило, компилятор позволяет обойти подобные потери одного такта. Для уменьшения потерь, связанных с командами условного перехода, в процессоре используется алгоритм прогнозирования направления передачи управления.
Количество тактов, необходимое для записи слова или двойного слова командой STORE, уменьшено с трех до двух тактов. РА-7100 использует отдельную шину адресного тега, чтобы совместить по времени чтение тега с записью данных предыдущей команды STORE. Кроме того, наличие отдельных сигналов разрешения записи для каждого слова строки кэш-памяти устраняет необходимость объединения старых данных с новыми, поступающими при выполнении команд записи слова или двойного слова. Этот алгоритм требует, чтобы запись в микросхемы SRAM происходила только после того, когда будет определено, что данная запись сопровождается попаданием в кэш и не вызывает прерывания. Это требует дополнительной ступени конвейера между чтением тега и записью данных. Такая конвейеризация не приводит к дополнительным потерям тактов, поскольку в процессоре реализованы специальные цепи обхода, позволяющие направить отложенные данные команды записи последующим командам загрузки или командам STORE, записывающим только часть слова. Для данного процессора потери конвейера для команд записи слова или двойного слова сведены к нулю, если непосредственно последующая команда не является командой загрузки или записи. Иначе потери равны одному такту. Потери на запись части слова могут составлять от нуля до двух тактов. Моделирование показывает, что подавляющее большинство команд записи в действительности работает с однословным или двухсловным форматом.
Все операции с плавающей точкой, за исключением команд деления и вычисления квадратного корня, полностью конвейеризованы и имеют двухтактную задержку выполнения как в режиме с одинарной, так и с двойной точностью.
Процессор может выдавать на выполнение независимые команды с плавающей точкой в каждом такте при отсутствии каких-либо потерь. Последовательные операции с зависимостями по регистрам приводят к потере одного такта. Команды деления и вычисления квадратного корня выполняются за 8 тактов при одиночной и за 15 тактов при двойной точности. Выполнение команд не останавливается из-за команд деления/вычисления квадратного корня до тех пор, пока не потребуется регистр результата или не будет выдаваться следующая команда деления/вычисления квадратного корня.
Процессор может выполнять параллельно одну целочисленную команду и одну команду с плавающей точкой. При этом "целочисленными командами" считаются и команды загрузки и записи регистров плавающей точки, а "команды плавающей точки" включают команды FMPYADD и FMPYSUB. Эти последние команды объединяют операцию умножения соответственно с операциями сложения или вычитания, которые выполняются параллельно. Пиковая производительность составляет 200 MFLOPS для последовательности команд FMPYADD, в которых смежные команды независимы по
регистрам.
Потери для операций плавающей точки, использующих предварительную загрузку операнда командой LOAD, составляют один такт, если команды загрузки и плавающей арифметики являются смежными, и два такта, если они выдаются для выполнения одновременно. Для команды записи, использующей результат операции с плавающей точкой, потери отсутствуют, даже если они выполняются параллельно.
При выполнении блочного копирования данных в ряде случаев компилятор заранее знает, что запись должна осуществляться в полную строку кэш-памяти. Для оптимизации обработки таких ситуаций архитектура PA-RISC 1.1 определяет специальную кодировку команд записи ("блочное копирование"), которая показывает, что аппаратуре не нужно осуществлять выборку из памяти строки, при обращении к которой может произойти промах кэш-памяти. В этом случае время обращения к кэшу данных складывается из времени, которое требуется для копирования в память старой строки кэш-памяти по тому же адресу в кэше, и времени, необходимого для записи нового тега кэша.
В процессоре PA- 7100 такая возможность реализована как для привилегированных, так и для непривилегированных команд.
Последнее улучшение управления кэшем данных связано с реализацией семафорных операций "загрузки с обнулением" непосредственно в кэш-памяти. Если семафорная операция выполняется в кэше, то потери времени при ее выполнении не превышают потерь обычных операций записи. Это не только сокращает конвейерные потери, но и снижает трафик шины памяти. В архитектуре PA-RISC 1.1 предусмотрен также другой тип специального кодирования команд, который устраняет требование синхронизации семафорных операций с устройствами ввода-вывода.
Управление кэш-памятью команд позволяет при промахе продолжить выполнение команд сразу же после поступления отсутствующей в кэше команды из памяти. Используемая для заполнения блоков кэша команд 64-битовая магистраль данных соответствует максимальной полосе пропускания внешней шины памяти 400 Мб/с при тактовой частоте 100 МГц.
Конструкция процессора обеспечивает реализацию двух способов построения многопроцессорных систем. При первом способе каждый процессор подсоединяется к интерфейсному кристаллу, который наблюдает за всеми транзакциями на шине основной памяти. В такой системе все функции по поддержанию когерентного состояния кэш-памяти возложены на интерфейсный кристалл, который посылает процессору соответствующие транзакции.
Второй способ организации многопроцессорной системы позволяет объединить два процессора и контроллер памяти и ввода-вывода на одной и той же локальной шине памяти. В такой конфигурации не требуется дополнительных интерфейсных кристаллов и система совместима с существующей системой памяти. Когерентность кэш-памяти обеспечивается наблюдением за локальной шиной памяти. Пересылки строк между кэшами выполняются без участия контроллера памяти и ввода-вывода. Такая конфигурация обеспечивает возможность построения очень дешевых высокопроизводительных многопроцессорных систем.
Процессор построен на базе КМОП-технологии с проектными нормами 0,8-мк, что обеспечивает тактовую частоту 100 МГц.
Процессор РА-7200 имеет ряд архитектурных усовершенствований по сравнению с РА-7100, главными из которых являются добавление второго целочисленного конвейера, построение внутрикристального вспомога-тельного кэша данных и реализация нового 64-битового интерфейса с шиной памяти.
В процессоре PA-7200 реализован эффективный алгоритм пред-варительной выборки команд, хорошо работающий и на линейных участках программ.
Расширенный набор команд процессора позволяет реализовать средства автоиндексации для повышения эффективности работы с массивами, а также осуществлять предварительную выборку команд, которые помещаются во вспомогательный внутренний кэш.
Процессор PA-7200 включает интерфейс новой 64-битовой мульти-плексной системной шины Runway, реализующей расщепление транзакций и поддержку протокола когерентности памяти. Этот интерфейс включает буфера транзакций, схемы арбитража и схемы управления соотношениями внешних и внутренних тактовых частот.
Процессоры с архитектурой x и Pentium
Архитектура 80x86 создавалась несколькими независимыми группами разработчиков, которые развивали ее более 15 лет, добавляя новые возможности к первоначальному набору команд.
Микропроцессор 8080 был построен на базе накапливающего сумматора (аккумулятора), но архитектура 8086 была расширена дополнительными регистрами. Поскольку почти каждый регистр в этой архитектуре имеет определенное назначение, 8086 по классификации частично можно отнести к машинам с накапливающим сумматором, а частично– к машинам с регистрами общего назначения, и его можно назвать расширенной машиной с накапливающим сумматором. Микропроцессор 8086 (точнее его версия 8088 с 8-битовой внешней шиной) стал основой, завоевавшей впоследствии весь мир серии компьютеров IBM PC, работающих под управлением операционной системы MS-DOS.
В 1980 г. был анонсирован сопроцессор плавающей точки 8087. Эта архитектура расширила 8086 почти на 60 команд работы с плавающей точкой. Ее архитекторы отказались от расширенных накапливающих сумматоров для того, чтобы создать некий гибрид стеков и регистров, по сути, расширенную стековую архитектуру. Полный набор стековых команд дополнен ограниченным набором команд типа регистр – память.
Анонсированный в 1982 г. микропроцессор 80286 еще дальше расширил архитектуру 8086. Была создана сложная модель распределения и защиты памяти, расширено адресное пространство до 24 разрядов, а также добавлено несколько команд. Поскольку очень важно было обеспечить выполнение программ, разработанных для 8086, в 80286 без изменений, был предусмотрен режим реальных адресов, позволяющий машине выглядеть почти как 8086. В 1984 г. компания IBM объявила об использовании этого процессора в своей новой серии персональных компьютеров IBM PC/AT.
В 1987 г. появился микропроцессор 80386, который расширил архитектуру 80286 до 32 бит. В дополнение к 32-битовой архитектуре с 32-битовыми регистрами и 32-битовым адресным пространством в микропроцессоре 80386 появились новые режимы адресации и дополнительные операции.
Все эти расширения превратили 80386 в машину, по идеологии близкую к машинам с регистрами общего назначения. Наряду с механизмом сегментации памяти в микропроцессор 80386 была добавлена поддержка страничной организации памяти. Как и 80286, микропроцессор 80386 имеет режим выполнения программ, написанных для 8086. Хотя базовой операционной системой для этих микропроцессоров оставалась MS-DOS, тем не менее 32-разрядная архитектура и страничная организация памяти послужили основой для переноса на эту платформу операционной системы UNIX. Следует отметить, что для процессора 80286 была создана операционная система XENIX (сокращенный вариант системы UNIX).
Последующие процессоры (80486 в 1989 г. и Pentium в 1993 г.) были нацелены на увеличение производительности и добавили к видимому пользователем набору команд только три новые команды, облегчившие организацию многопроцессорной работы.
Семейство процессоров i486 (i486SX, i486DX, i486DX2 и i486DX4), в котором сохранились система команд и методы адресации процессора i386, уже имеет некоторые свойства RISC-микропроцессоров. Например, наиболее употребительные команды выполняются за один такт. Компания Intel для оценки производительности своих процессоров ввела в употребление специальную характеристику, которая называется рейтингом iCOMP. Компания надеется, что эта характеристика станет стандартной тестовой оценкой и будет применяться другими производителями микропроцессоров, однако последние с понятной осторожностью относятся к системе измерений производительности, введенной компанией Intel. Ниже, в табл. 4.1, приведены сравнительные характеристики некоторых процессоров компании Intel на базе рейтинга iCOMP.
Процессоры i486SX и i486DX – это 32-битовые процессоры с внутренней кэш-памятью емкостью 8 Кб и 32-битовой шиной данных. Основное отличие между ними состоит в том, что в процессоре i486SX отсутствует интегрированный сопроцессор плавающей точки. Поэтому он имеет меньшую цену и применяется в системах, для которых не очень важна производительность при обработке вещественных чисел.
Для этих систем обычно возможно расширение с помощью внешнего сопроцессора i487SX.
Процессоры Intel OverDrive и i486DX2 практически идентичны. Однако кристалл OverDrive имеет корпус, который может устанавливаться в гнездо расширения сопроцессора i487SX, применяемое в ПК на базе i486SX. В процессорах OverDrive и i486DX2 применяется технология удвоения внутренней тактовой частоты, что позволяет увеличить производительность процессора почти на 70 %. Процессор i486DX4/100 использует технологию утроения тактовой частоты. Он работает с внутренней тактовой частотой 99 МГц, в то время как внешняя тактовая частота (частота, на которой работает внешняя шина) составляет 33 МГц. Этот процессор практически обеспечивает равные возможности с машинами класса 60 МГц Pentium.
Появившийся в 1993 г. процессор Pentium ознаменовал собой новый этап в развитии архитектуры x86, связанный с адаптацией многих свойств процессоров с архитектурой RISC. Он изготовлен по 0,8-микронной
БиКМОП технологии и содержит 3,1 млн транзисторов. Первоначальная
Таблица 4.1. Характеристики процессоров
Процессор |
Тактовая частота, Мгц |
Рейтинг iСOMP |
386SX 386SL 386DX 386DX i486SX i486SX i486SX i486DX i486DX2 i486DX i486DX2 i486DX4 i486DX4 Pentium Pentium Pentium Pentium Pentium |
Известны два подхода к построению логики формирования функциональных импульсов. Один из них: каждой операции процессора соответствует набор логических схем, выполненных на диодах, транзисторах и т.д. и определяющих, какой функциональный импульс (ФИ) и в каком такте должен быть возбужден. Пусть некоторый ФИ должен появиться в такте j операции m при условии наличия переполнения сумматора или в такте i операции n. Требуемое действие будет выполнено, если подать сигналы, соответствующие указанным кодам операции, тактам и условиям на входы схем И, а выходы последних через схему ИЛИ соединить с формирователем ФИ (рис. 2.3).
 |
Такой принцип управления операциями получил название "жесткой" или "запаянной" логики и широко применяется во многих компьютерах.
Рис. 2.3. Формирование функционального импульса
Другой принцип организации управления: каждой микрооперации (МИО) ставится в соответствие слово (или часть слова), называемое микрокомандой и хранимое в памяти подобно тому, как хранятся в памяти команды обычного компьютера. Здесь команде соответствует микропрограмма, т. е. набор микрокоманд (МИК), указывающих, какие ФИ и в какой последовательности необходимо возбуждать для выполнения данной операции. Такой подход получил название микропрограммирования или "хранимой логики". Это подчеркивает тот факт, что в микропрограммном компьютере логика управления реализуется не в виде электронной схемы, а в виде закодированной информации, находящейся в каком-то регистре.
Идея микропрограммирования, высказанная в 1951 г. Уилксом, до недавнего времени не находила широкого применения, ибо:
· не было надежных и быстродействующих ЗУ для хранения микропрограммы;
· неправильно понимались задачи и выгоды микропрограммирования.
Поясним второй аргумент. Считалось, ценность микропрограммирования в том, что каждый потребитель может сконструировать себе из МИК нужный ему набор операций в данной конкретной задаче. Замена наборов команд достигалась бы заменой информации в ЗУ без каких-либо переделок в аппаратуре.
Однако в этом случае программисту необходимо было бы знать все тонкости работы инженера-разработчика компьютера. А основная тенденция развития ЭВМ в связи с автоматизацией программирования состоит в том, чтобы освободить программиста от детального изучения устройств компьютера и в максимальной степени приблизить язык компьютера к языку человека. Поэтому микропрограммные компьютеры считали трудными для пользователя.
В последнее время интерес к микропрограммному принципу возродился, так как:
· созданы односторонние (читающие) быстродействующие ЗУ с малым циклом памяти;
· микропрограммирование рассматривается не как средство повышения гибкости программирования, а как метод построения системы управления процессором, удобный для инженера-разработчика компьютера.
Программист в своей работе может и не подозревать о микропро-граммной структуре компьютера и использовать все средства ПО и языки программирования самого высокого уровня. Использование микропрограммного принципа позволяет облегчить разработку и изменение логики процессора.
С появлением программного доступа к состоянию процессора после выполнения каждой МИК обеспечивается возможность создания экономичной системы автоматической диагностики неисправностей и появляется способность к эмуляции, т. е. к выполнению на данной ЭВМ программы, составленной в кодах команд другого компьютера. Это достигается введением дополнительного набора МИК, соответствующих командам эмулируемого компьютера.
Эти возможности способствуют распространению методов микропрограммирования при построении УУ в современных компьютерах.
ПРОЦЕССЫ ПОСЛЕДОВАТЕЛЬНЫЕ И ПАРАЛЛЕЛЬНЫЕ
Мы привыкли к последовательному образу мышления, к компьютерам последовательного действия, а следовательно, к разработке последовательных алгоритмов и соответственно к последовательной обработке данных. И как следствие этого, разработаны и широко используются "последовательные" языки программирования – ФОРТРАН, АЛГОЛ, ПАСКАЛЬ и многие другие.
Но если внимательно рассмотреть процессы, происходящие вокруг нас и в нас самих, то мы заметим, что многие операции выполняются одновременно. И естественно предположить, что только окружающие нас возможности по их реализации и адекватному отображению не позволяют нам замечать эту одновременность. В частности, однопроцессорные ЭВМ – один из главных источников формирования последовательного мышления. Этот процесс особенно усилился с появлением и широким распространением персональных компьютеров (ПК).
В настоящее время в мире произведено большое количество многопроцессорных компьютеров, которые позволяют осуществлять одновременную параллельную обработку многих процессов.
Под многопроцессорной вычислительной системой (МВС) будем понимать комплекс вычислительных средств, связанных физически и программно, в котором одновременно (в один и тот же момент времени) может выполняться несколько арифметических или логических операций по преобразованию данных.
Сформулированное определение исключает из понятия ВС обычные ЭВМ, содержащие один центральный и один или несколько периферийных процессоров.
Параллельные процессы начали усиленно исследоваться в связи с созданием локальных и глобальных компьютерных сетей и идеей распределенной обработки информации.
Часто бывает выгодно разделять время единственного обрабатывающего устройства между несколькими процессами. Полезной абстракцией является рассмотрение этих процессов как процессов, протекающих параллельно.
Программные методы контроля
Программные методы базируется на использовании специальных методов и пакетов контролирующих программ. Различают тестовый и программно-логический контроль. Тестовый контроль осуществляется в ЭВМ периодически с помощью программ-тестов. Тесты бывают:
· наладочные – для комплексной наладки компьютера;
· проверочные – для проверки устойчивости близких к отказу элементов во время профилактики ЭВМ;
· программы контрольных задач – пропускаются во время решения задачи в целях проверки работоспособности компьютера;
· диагностические – для локализации обнаруженных отказов путем программного анализа ошибок.
Программно-логический контроль ставит цель – непосредственно проверить правильность решения задачи при выполнении основной программы. Можно вводить некоторые операции дополнительно для контроля всех выполняемых операций. Рассмотрим ряд способов такого контроля.
Контроль решений методом двойного счета. Суть метода состоит в повторном вычислении всей задачи или отдельных ее частей. Результаты сравниваются и их совпадение считается признаком достоверности результата. При несовпадении результатов решение повторяется до двух одинаковых результатов, которые считаются верными.
Если решение задачи – таблица, то получается некоторая контрольная сумма и производится сравнение этих контрольных сумм.
Достоинство метода в простоте, однако необходимо предварительно предусмотреть контрольные точки.
Недостатки:
· время с контролем Т¢ намного больше времени решения задачи без контроля;
· использовать метод можно лишь тогда, когда исходные данные при решении задачи не разрушаются или могут быть легко восстановлены;
· исправляются лишь случайные ошибки, как результат сбоя.
Математические и смысловые проверки (МС-проверки). МC-проверки основаны на анализе промежуточных результатов решения задачи. Для этого предварительно необходимо проделать определенную работу по исследованию алгоритма решения задачи с целью выявить границы изменяемых величин, дополнительные условия, которым они должны удовлетворять, и т. д.
Общие принципы МС- проверок сформулировать трудно, ибо многое зависит от конкретной задачи и искусства программиста.
Рассмотрим некоторые типовые примеры.
Способ подстановки.
Суть: программой осуществляется подстановка полученных решений в условие задачи. После этого сравниваются правые и левые части уравнений в целях определения невязок. Если невязки не выходят за пределы заданной точности, решение считается правильным. Здесь время небольшое на контроль в сравнении с повторным счетом, тем не менее обнаруживает как случайные, так и систематические ошибки. Для исправления необходим повторный счет.
Дополнительные связи переменных.
Суть: используются некоторые дополнительные связи между искомыми величинами. Типичные примеры – связи между тригонометрическими функциями:

В связи с трудностями установления подобных связей такой контроль трудно сделать глубоким. Иногда в задачу вводят дополнительные переменные, удовлетворяющие вместе с вычисляемыми величинами некоторым соотношениям, и используют их для контроля.
Проверка предельных значений.
В большинстве задач нетрудно заранее определить пределы, в которых должны находиться некоторые искомые величины. Это делается обычно на основе приближенного анализа алгоритма вычислений. Тогда в программе в определенных точках выполняется проверка на нахождение величин в заданных пределах.
Адресное кодирование. В целях повышения быстродействия компьютера используется модификация команд. Она состоит в изменении адресной части базовой команды. В некоторых случаях в адресной части базовой команды индексируются и адреса команд. Этот прием используется в программах, состоящих из нескольких вычислительных блоков. Операции, связанные с изменением адресов, не застрахованы от ошибок.
Один из методов снижения вероятности таких ошибок состоит в особом кодировании, применяемом при программировании. Речь идет о выборе ячеек из ЗУ, совокупность адресов которых составляет какой-нибудь корректирующий код, например код с проверкой на четность.
Пример. Пусть программа разделена на ряд вычислительных блоков, начальные адреса которых хранятся в виде таблицы. Основная функция общей части программы – правильно определить вход в эту таблицу.
Пусть таблица имеет 8 входов. Выберем для их хранения 8 из 16 последовательных ячеек ЗУ, которые имеют адреса с четным числом единиц (см. табл. 11.5). Во все остальные ячейки поместим одну и ту же команду перехода к исправляющей программе ПкИП. Определить вход в таблицу несложно. Вот одна из возможностей. Для определения номера входа (N) надо брать все числа от 0 до 7, складывать их с числом, сдвинутым влево на один разряд. Таким образом, номер ячейки Nвх. А с адре-
сом входа в блок А равен Nвх. А = А + 2А.
Таблица 11.5. Пример адресного кодирования
Программы для обработки документовХотя алгоритмы сжатия, применяемые в телефаксах, непригодны для цветных и полутоновых изображений, они, очевидно, могут быть полезны для сжатия деловых документов, содержащих только текст и штриховые рисунки. Поэтому неудивительно, что многие фирмы использовали алгоритмы сжатия, подобные применяемым в телефаксах, для обработки деловой документации. Этот подход реализован в самых разных программных изделиях,  Рис.11.2. Сжатие данных в телефаксах от простых программ для однопользовательских систем до насыщенных мощными средствами программно-аппаратных комплексов, предназначенных для архивации и индексирования документации в объединяющий ряд географически разнесенных отделений корпорации. Один из примеров – система Hurdler CER для шины NuBus фирмы Creative Solutions, выполняющая сжатие и преобразование данных. На плате через встроенное постоянное запоминающее устройство реализована схема сжатия данных группы IV, в которой слегка улучшена обработка ошибок (небольшие ошибки могут не иметь значения при приеме факсов, но перерастают в большую проблему при записи информации на диск). Быстродействующая микросхема сопроцессора позволяет комплексу CER сжимать файлы, полученные в результате обработки сканером монохромного изображения, со скоростью 16 млн. элементов изображения в минуту. Фирма Creative Solutions поставляет вместе с комплексом CER специальные драйверы, позволяющие пользователям передавать файлы непосредственно в интерфейс NuBus, при этом не требуется никакого дополнительного программного обеспечения. Система архивации документов ArcImage фирмы First Financial Technology обладает более широкими возможностями. Эта система первоначально была предназначена для удовлетворения внутренних потребностей фирмы, связанных с обработкой банковских документов. В состав системы входят плата-акселератор с интерфейсом NuBus и программное обеспечение. В комплекте поставки имеются также простая в обращении обучающая программа и документация. Плата для шины NuBus с системой ArcImage позволяет в режиме реального времени обрабатывать информацию с выхода быстродействующего сканера (Fujitsu с автоматической подачей бумаги со скоростью 12 листов в минуту).
Простые алгоритмыНачнем с обычных текстовых файлов. Файл состоит из символов и, возможно, "невидимых" кодов управления печатью. Каждый символ в коде ASCII представлен одним байтом, или восемью битами. Алгоритм кодирования Хаффмана. В основе алгоритма лежит простой принцип: символы заменяются кодовыми последовательностями различной длины. Чем чаще используется символ, тем короче соответствующая последовательность. Например, для английского текста символам e, t, a можно поставить в соответствие 3-битовые последовательности, а j, z, q – 8-битовые. В одних вариантах алгоритма Хаффмана используются готовые кодовые таблицы, в других – кодовая таблица строится на основе статистического анализа содержимого файла (см. табл. 11.4. Кодирование Хаффмана). Применение кода Хаффмана гарантирует возможность декодирования. Это важно, так как "упакованные" кодовые последовательности имеют различную длину, в отличие от обычных, длина которых постоянна и равна 8 бит на символ. Пусть процессор вычисляет значение выражения Программа решения этой задачи для одноадресного компьютера может быть следующей (табл. 2.4). Таблица 2.4. Пример программы
Замечание. Выполнение команды типа  регистр  Как следует из приведенной программы, операнд a выбирается из памяти 2 раза (команды 4 и 5), b – 3 раза (команды 2, 7 и 8). Кроме того, потребовались дополнительные обращения к памяти для запоминания и вызова из памяти результатов промежуточных вычислений (команды 3, 6, 9, 10). Если главным фактором, ограничивающим быстродействие компьютера, является время цикла памяти, то необходимость в дополнительных обращениях к памяти значительно снижает скорость его работы. Очевидно, что принципиально необходимы только обращения к памяти за данными в первый раз. В дальнейшем они могут храниться в триггерных регистрах или СОЗУ. Указанные соображения получили свое воплощение в ряде логических структур процессора. Одна из них – процессор со стековой памятью. Принцип ее работы поясняет схема, представленная на рис. 2.2. Стековая память представляет собой набор из n регистров, каждый из которых способен хранить одно машинное слово. Одноименные разряды регистров P1, P2, ..., Pn соединены между собой цепями сдвига. Поэтому весь набор регистров может рассматриваться как группа n?разрядных сдвигающих регистров, составленных из одноименных разрядов регистров P1, P2, ..., Pn. Информация в стеке может продвигаться между регистрами вверх и вниз. Движение вниз: (P1) ® P2, (P2) ® P3, ..., а P1 заполняется данными из главной памяти. Движение вверх: (Pn) ® Pn?1, (Pn?1) ® Pn?2, а Pn заполняется нулями.
Регистры P1 и P2 связаны с АЛУ, образуя два операнда для выполнения операции. Результат операции записывается в P1. Следовательно, АЛУ выполняет операцию  Одновременно с выполнением арифметической операции (АО) осуществляется продвижение операндов вверх, не затрагивая P1, т. е. (P3) ® P2, (P4) ® P3 и т. д. Таким образом, АО используют подразумеваемые адреса, что уменьшает длину команды. В принципе, в команде достаточно иметь только поле, определяющее код операции. Поэтому компьютеры со стековой памятью называют безадресными. В то же время команды, осуществляющие вызов или запоминание информации из главной памяти, требуют указания адреса операнда. Поэтому в ЭВМ со стековой памятью используются команды переменной длины. Например, в KDF-9 команды АО – однослоговые, команды обращения к памяти и передач управления – трехслоговые, остальные – двуслоговые. Команды располагаются в памяти в виде непрерывного массива слогов независимо от границ ячеек памяти. Это позволяет за один цикл обращения к памяти вызвать несколько команд. Для эффективного использования возможностей такой памяти в ЭВМ вводятся спецкоманды: · дублирование ~ (P1) ® P2, (P2) ® P3, ... и т. д., а (P1) остается при этом неизменным; · реверсирование ~ (P1) ® P2, а (P2) ® P1, что удобно для выполнения некоторых операций. Рассмотрим тот же пример для новой ситуации (табл. 2.5): Таблица 2.5. Реализация программы со стековой памятью
|














