МИКРОПРОЦЕССОРНЫЕ УСТРОЙСТВА В РАДИОЭЛЕКТРОННОЙ АППАРАТУРЕ
МИКРОПРОЦЕССОРЫ — ЭЛЕМЕНТНАЯ БАЗА ЦИФРОВЫХ УСТРОЙСТВ
1.1. ПРИНЦИПЫ ПОСТРОЕНИЯ МИКРОПРОЦЕССОРНЫХ СРЕДСТВ
Микропроцессорные средства (МПС) возникли в результате развития технологии и вычислительной техники. По своей сути микропроцессор — это устройство, представляющее собой одну «ли несколько больших интегральных схем (БИС), выполняющих -функции процессора ЭВМ. Являясь частью вычислительных устройств, МПС используют и принципы их построения. Вместе с тем, существующий уровень развития полупроводниковой технологии вносит свои коррективы в эти принципы. Например, разрядность и сложность микропроцессорных (МП) БИС определяются максимальными размерами кристаллов, изготовление которых может обеспечить технология производства.
При построении современных МПС используют, в основном, «следующие принципы: микропрограммное управление, модульность построения, магистральный обмен информацией, наращиваемость вычислительной мощности.
Микропрограммное управление. Классическое вычислительное устройство состоит из арифметического устройства (АУ), устройства управления (УУ), запоминающего устройства (ЗУ) и устройства в во да-вывода (УВВ); АУ и УУ образуют процессор любой ЭВМ, т. е. ее управляющую и обрабатывающую части. УУ вырабатывает сигналы, под действием которых АУ выполняет все необходимые операции и действия. Существуют два метода построения УУ: с использованием комбинационных схем и микропрограммного ЗУ. В первом случае каждое входное воздействие »а УУ жестко связано с выходным и их изменения возможны только при изменении электрической схемы УУ. Поскольку входное воздействие — это команда МП, то использование такого метода жестко фиксирует его систему команд; при этом достигается максимальное быстродействие УУ. Микропроцессоры, использующие комбинационные УУ, называют МП с фиксированным набором команд. Примером такого МП является КР580ИК80.
В соответствии с микропрограммным принципом управления любая сложная операция делится на последовательность более простых действий.
Такое простое действие называется микрооперацией и выполняется за один такт работы АУ. Для задания очередности следования микроопераций вводятся специальные переменные, называемые логическими условиями. Совокупность микроопераций, выполняемых за один цикл (несколько тактов) работы устройства, называется микрокомандой (МК). Микрокоманда представляет собой двоичное я-разрядное слово, содержащее код операции (КОП), выполняемой АУ, а также коды адресов исходных данных и результата. Микрокоманда поступает на вход АУ, которое дешифрует ее и вырабатывает управляющие сигналы. Эти сигналы стробируются импульсами внутреннего блока синхронизации, который формирует временные такты выполнения микроопераций. Микрооперации жестко связаны со структурой АУ и не могут быть изменены.
После выполнения действия, определенного КОП, АУ информирует об окончании выполнения микрокоманды. Каждому АУ присущ только свой, конкретный набор МК, который называется системой микрокоманд.
Устройство, предназначенное для записи, хранения и считывания МК называется микропрограммным устройством управления (МУУ). В простейшем случае МУУ представляет собой БИС ПЗУ «ли ППЗУ, в которой записаны МК- Для считывания этих МК необходимо устройство формирования адреса, например счетчик. Любую операцию можно представить последовательностью МК (микропрограммой). Необходимо отметить два основных отличия микропрограммного управления от жесткого: смена выполняемой операции обеспечивается заменой микропрограммы; при считывании каждой МК требуется обращение к ПЗУ, что снижает быстродействие УУ. Итак, микропрограммное управление заменяет аппаратные средства программными и обеспечивает высокую гибкость, но при снижении быстродействия.
Минрокомандный уровень управления АУ является самым низким уровнем, доступным разработчику МПУ. Микрокоманда наиболее полно отражает структуру АУ, в силу чего реализация операций с помощью микропрограмм является оптимальной в смысле экономии памяти и повышения быстродействия.
Наряду с этим МК представляет собой достаточно мелкую детализацию выполняемой операции, например «обнулить регистр», «содержимое регистра переслать в аккумулятор» и т. д. Поэтому для программирования сложных алгоритмов, которыми являются алгоритмы обработки сигналов, потребовалось бы составить микропрограммы,, содержащие сотни, тысячи микрокоманд. Отладить такую микропрограмму очень сложно.
Для повышения уровня детализации выполняемой операции вводится командный уровень управления. Символом этого уровня является команда, которая представляет собой (как и микрокоманда) m-разрядное двоичное слово (обычно m<n). В общем случае формат команды должен включать КОП, адреса операндов, над которыми выполняется операция, и адрес результата. Команда представляет собой последовательность МК (микропрограмму). С целью экономии емкости микропрограммной памяти запись МК осуществляется в ячейки памяти, содержание которых, учитывает код текущей МК [1].

Рис. 1.1. Структурная схема микропрограммного устройства управления
Структурная схема МУУ изображена на рис. 1.1. Команда, считанная из ЗУ, поступает на .регистр команд и далее на блок управления. В соответствии с принятыми сигналами блок управления формирует адрес первой МК микропрограммы, соответствующей принятой команде. Этот адрес через регистр поступает в ЗУ МК. Считанная из ЗУ МК состоит из двух частей: операционной (или собственно микрокоманды, которая поступает на АУ) и адресной, которая поступает на блок управления. Приняв адресную часть МК, блок управления формирует адрес следующей МК. Виовь считанная МК имеет свою адресную часть, которая поступает на блок управления. Этот процесс продолжается до тех пор, пока не будет считана последняя МК данной программы. После этого МУУ готово к приему следующей команды. Длина микропрограммы определяется разрядностью кода адреса следующей МК. В табл. 1.1 приведены типовые команды процессора, выполненного на микросхемах серии К589, и число МК, содержащихся в этих командах [4, 6].
Доля МК обращения к ЗУ составляет 20 — 40%, это дает возможность работать нескольким МП с общей памятью без взаимных помех.
Итак, использование микропрограммного управления при построении МПУ обработки сигналов позволяет разрабатывать системы команд и языки, ориентированные на структуру реализуемых алгоритмов, повышать быстродействие за счет параллельной работы нескольких микропроцессоров с общей памятью.
МИКРОПРОЦЕССОРНЫЕ УСТРОЙСТВА В РАДИОЭЛЕКТРОННОЙ АППАРАТУРЕ
ОСОБЕННОСТИ ПРИМЕНЕНИЯ И КОНСТРУИРОВАНИЯ ВСТРАИВАЕМЫХ В РЭА МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ
2.1. ОБЛАСТИ ПРИМЕНЕНИЯ КОНСТРУКТИВНО ВСТРОЕННЫХ В РЭА МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ
Развитие современной РЭА характеризуется широким применением цифровых -методов обработки, преобразования и регистрации сигналов. Устройства, входные и выходные сигналы которых представляются в цифровой форме, называют цифровыми. Элементной базой таких устройств являются цифровые ИМС различной степени интеграции.
Прогресс в области микроэлектроники привел к созданию микропроцессорных БИС, являющихся элементной базой построения нового класса цифровой РЭА — микропроцессорных устройств (МПУ), которые представляют собой функционально законченные, программно управляемые вычислительные устройства.
Чаще всего МПУ применяются совместно с цифровыми устройствами (жесткой логикой), расширяя функциональные возможности РЭА. Радиоэлектронные устройства (РЭУ) объединяют аналоговые, цифровые и аналого-цифровые узлы. Конструкция такого устройства обычно представляет собой моноблок [27]; МПУ, реализующие некоторые функциональные узлы РЭУ, встраиваются в него и конструктивно представляют собой одну или несколько функциональных ячеек моноблока |[28].
Области применения МПУ в современной РЭА определяются, в основном, их быстродействием и функциональными возможностями по сравнению с комбинационными устройствами. По мере изменения этого соотношения в пользу МПУ расширяются и области их применения. Исходя из современного уровня функциональных возможностей МПУ, можно выделить следующие области применения микропроцессоров в РЭА.
Цифровые системы радиосвязи. В цифровых системах радиосвязи находят применение широкополосные шумоподобные модулирующие сигналы. Использование таких сигналов позволяет рас-
средоточить энергию излучаемого сигнала в широком диапазоне частот, определяемом шириной спектра модулирующего сигнала. Рассмотрим пример использования микропроцессоров при построении таких систем [29].
Пример 2.1. Упрощенная структурная схема цифровой системы радиосвязи с широкополосными шумоподобными сигналами изображена на рис. 2.1. В данной системе связи низкочастотный входной цифровой сигнал модулируется высокочастотной псевдошумовой последовательностью. Ширина спектра промодулированного сигнала увеличивается пропорционально длине псевдослучайной последовательности. Такое расширение спектра позволяет рассредоточить энергию сигнала в широком диапазоне частот, что повышает отношение сигнал-шум при узкополосных помехах. Для демодуляции входного сигнала необходимо в приемном устройстве создать опорную псевдослучайную последовательность, идентичную модулирующей. После вычитания псевдослучайной последовательности из входного сигнала в высокочастотном демодуляторе-смесителе на выходе приемного устройства появляется исходный цифровой код данных.

Рис. 2.1. Структурная схема цифровой системы радиосвязи
Основной задачей схемы управления захватом, выполненной на базе микропроцессора СР-1600, является обеспечение и поддержание синхронизма друг относительно друга двух псевдошумовых последовательностей: принимаемой и опорной. На выходе детектора огибающей уровень сигнала будет нарастать пропорционально значению функции корреляции между двумя псевдошумовымв последовательностями. Этот сигнал, преобразованный в цифровую форму и усредненный по времени наблюдения, поступает на микропроцессор обработки, который работает в трех режимах: захват, проверка, поиск. Порог сравнения, соответствующий принятому режиму работы, устанавливается переключателем, входных уровней и через мультиплексор поступает в ОЗУ.
Программируемое ПЗУ емкостью 1КХ16 предназначено для хранения программ обработки входного сигнала. Код рассогласования, вырабатываемый микропроцессором обработки, поступает на регистр результата и буферные регистры. В соответствии с принятым кодом рассогласования дешифратор вырабатывает управляющее напряжение, которое осуществляет сдвиг псевдошумовой последовательности с целью получения максимальных значений напряжения на выходе детектора огибающей.
Точность синхронизации не превышает 1 бита. Микропроцессорная реализация схемы управления захватом обеспечивает выполнение трех режимов работы системы на одной и той же аппаратуре, возможность оперативного изменения длительности псевдослучайной последовательности и, следовательно, повышение помехоустойчивости системы связи.
Цифровая обработка сигналов (включая цифровую фильтрацию, спектральный анализ, корреляционную обработку и т. п.). Алгоритмы цифровой обработки сигналов основываются на вычислении операции свертки. Для вычисления операции свертки применяется, в основном, прямое и обратное дискретное преобразование Фурье (ДПФ). Для линейных дискретных систем с постоянными параметрами, к классу которых относятся цифровые устройства обработки сигналов, прямое и обратное ДПФ -может быть представлено в матричной форме [2]:

где Хn, Xk — матрицы-столбцы сигнала и его спектра размером. N; Fkn — унитарная матрица базисных функций размером NxN; F*kn — матрица, комплексно-сопряженная Fhn-
Для вычисления ДПФ в соответствии с (2.1) необходимо выполнить (N — I)2 умножений и N (N — 1) сложений комплексных чисел. Для уменьшения числа операций умножения и сложения
при вычислении ДПФ в практике проектирования цифровых устройств обработки сигналов используется алгоритм быстрого преобразования Фурье (БПФ) и его модификации [30].
Суть алгоритма БПФ заключается в том, что когда размер матрицы Fkn является составным числом, то матрица может быть представлена в виде произведения слабозаполненных матриц, т. е. факторизована. Это дает возможность производить вычисления ДПФ в несколько этапов, выполняя на каждом из них лишь небольшое число операций. Благодаря этому достигается экономия вычислений. Если N = rL, то г называют основанием преобразования, a L — числом этапов преобразования.
При цифровой обработке радиотехнических сигналов в качестве базисных функций чаще всего используются дискретные экспоненциальные функции вида

где Wh — дискретная экспоненциальная функция или поворачивающий коэффициент; iV — размер матрицы-столбца сигналов.
На рис. 2.2 изображен граф 8-точечного БПФ по основанию 2 с прореживанием по времени. Незачерченные кружочки обозначают операции сложения — вычитания, причем верхний выход означает сумму, нижний — разность. Стрелкой обозначена операция умножения на поворачивающий коэффициент. На графе можно выделить элементарный подграф базовой операции (при г = 2 это БПФ двух отчетов). Базовую операцию можно представить следующим образом:

причем X, У, А, В, Wh — комплексные числа.

Рис. 2.2 Граф 8-точечного быстрого преобразования Фурье (БПФ) (а)- базовые операции алгоритма БПФ с прореживанием по времени (б) и по частоте (в)
Блоки СОЗУ1, СОЗУ2 выполняют функции внутрипроцессорного интерфейса. На его вход поступают отсчеты входного сигнала с ОЗУ1, ОЗУ2 на первом этапе вычисления БПФ и промежуточные отсчеты с ОЗУЗ, ОЗУ4 назера-Бесселя [2]. Умножитель может быть реализован на БИС параллельных умножителей КР1802ВРЗ — КР1802ВР5. Максимально допустимое время умножения ty одного отсчета должно быть не больше, периода дискретизации Tn — 1JAF. Если Tд=(2-3) мкс, то целесообразно использовать 8-разрядный последовательный умножитель К.Р1802ВР2, потребляемая мощность которого ниже, либо умножитель К588ВР2, выполненный по КМОП-технологии.
«Взвешенные» отсчеты входного сигнала поступают на ОЗУ1 и ОЗУ2, емкость памяти которых определяется размерностью входного массива N:N= =Tc/Ta, где Tc — длительность обрабатываемого сигнала.
Сигналы, считанные из ОЗУ, поступают из вход МП БПФ, включающего сверхоперативные ОЗУ — СОЗУ1, СОЗУ2, МП БО, ППЗУ поворачивающих коэффициентов и выходные ОЗУЗ, ОЗУ4, остальных L — 1 этапах вычисления БПФ. С выхода СОЗУ отсчеты сигнала поступают на вход МП БО.
После вычисления ВПФ действительные и мнимые значения спектральных составляющих записаны в ОЗУЗ, ОЗУ4 соответственно. При приходе управляющих сигналов считывания эти значения через СОЗУ1, СОЗУ2 поступают на выход; СОЗУ1, СОЗУ2 npoVro реализуются на БИС обмена информации КР1802ВВ1.
Пример такой реализации для 8- разрядных магистралей показан на рис. 2.6. Разрешением обмена информации с каналами А, В, С, X управляют входы ЕСА, ЕСВ, ЕСС, ЕСХ. Выбор режима работы (считывание — запись) определяется сигналами RA, RB, RC, RX; WA, WB, WC, WX соответственно при разрешении обмена информацией с выбранным каналом. Входные сигналы ААО, АА1, АВО; АВ1, АСО, АС1, АХО, АХ1 обеспечивают выбор одного из четырех внутренних регистров БИС. Архитектура БИС ОИ обеспечивает помодульное наращивание разрядности выходных магистралей DA, DB, DC, DX. Магистрали DA, DB, DC предназначены для работы на короткие линии связи. Магистраль DX может работать на длинные согласованные линии связи (в данном случае выходные).

Рис. 2.4. Временная диаграмма работы микропроцессора базовой операции алгоритма быстрого преобразования Фурье

Рис. 2.5. Структурная схема вычислителя быстрого преобразования Фурье

Рис. 2.6. Функциональная схема СОЗУ, выполненного на БИС КР1802ВВ1
Используя МП БО и МП БПФ, можно построить различные цифровые устройства обработки сигналов.
Пример 2.4. Сигнал на выходе цифрового фильтра равен дискретной свертке входного сигнала s(nAT) с импульсной характеристикой системы h[nAT): y(nAT)=s(nДT)+h(nДT), где + — операция дискретной свертки. Известно, что свертка во временной области соответствует умножению в частотной области [30]. В соответствии с (2.1) получаем


Рис. 2.7. Структурная схема цифрового фильтра
На рис. 2.7 приведена структурная схема фильтра, реализующего алгоритм (2.3) и построенного на базе МП БПФ (см. рис. 2.5). Микропроцессор БПФ1 выполняет задачу спектрального анализа, т. е. переводит временной сигнал s(nAT) в частотную область. Далее вычисляется спектр выходного сигнала: Y(nAw). Микропроцессор БПФ2 выполняет обратное ДПФ, т. е. переводит сигнал из частотной области во временную. Как следует из (2.3), для реализации прямого и обратного ДПФ необходимы одинаковые функциональные блоки.

Рис. 2.8. Структурная схема адаптивного цифрового фильтра
Если вместо ЗУ импульсной характеристики использовать микропроцессор, вычисляющий ее значения, то получим адаптивный фильтр. Применяются такие фильтры при селекции движущихся целей на фоне отражений от поверхности Земли и метеобразований. Поскольку реальная окружающая среда отличается от предполагаемой, которая закладывалась в ЗУ импульсной характеристики, то характеристики реального синтезированного фильтра отличаются от оптимальных, что вносит потери. Эти потери можно скомпенсировать, если адаптивно реагировать на изменение окружающей среды. Структурная схемэ адаптивного фильтра изображена на рис. 2.8. Этот фильтр аналогичен фильтру, изображенному на рис. 2.7, за исключением того, что значения импульсной характеристики периодически пересчитываются в зависимости от окружающей обстановки.
Управление лучом фазированной антенной решетки (ФАР) бортовой РЛС. Алгоритм управления лучом ФАР бортовой РЛС включает две части. Одна из них предназначена для вычисления направляющих косинусов по данным углового положения летательного аппарата в пространстве и предварительному указанию пеленга цели: (sd/Л)cos а и (sd/Л)cos$, где s — число состояний фазотаращателя; s = 2п/Дф (Дф — дискрет .приращения фазы); X — длина волны. Вторая часть алгоритма позволяет по полученным значениям направляющих косинусов рассчитать фазовое распределение в ФАР ![27]:

где (fij — значение фазы; ij — номер столбца и строки ФАР соответственно; (fa]mods — символ операции взятия целой части числа ПО МОДУЛЮ 5.
Анализ алгоритмов управления лучом ФАР показывает, что его первая часть содержит более 50% различных тригонометрических преобразований. Вычисление тригонометрических функ-
ций обычно осуществляется приближенными методами, использующими их разложение в ряд Маклорена. Вторая часть алгоритма, как следует из (2.4), по сути, (сводится к многократному повторению операции сложения, причем число операций сложения определяется размерностью модуля ФАР и равно псл = МхМ% М и N — число строк и столбцов ФАР соответственно.
Реализация такого количества сложений на МП, последовательно вычисляющем фij для каждого излучателя, привела бы к большим временным затратам. Поэтому целесообразно вычислитель управления лучом ФАР реализовать на МП с использованием аппаратного-сумматора, реализующего алгоритм (2.4).
Пример 2.5. Структурная схема вычислителя управления лучом ФАР приведена на рис. 2.9. Данные об угловом положении летательного аппарата и предварительное значение пеленга цели поступают через буферные регистры » ОЗУ. Микропроцессор в соответствии с программой, хранимой в ППЗУ, вычисляет значения направляющих косинусов для данного положения ЛА. Эти значения через буферные регистры подаются на сумматор, вычисляющий значения фазового распределения согласно (2.4). Структурная схема матричного сумматора для ФАР 8X8 приведена на рис. 2.10. Значения направляющих косинусов и сигналы управления поступают на буферный регистр, выполненный на БИС КР1802ВВ1, и далее на матричный сумматор, который вычисляет значения фij для каждого излучателя. Вычисленные значения хранятся в регистрах, а по сигналу считывания они поступают на фазовращатели ФАР. Общее время вычисления фазового распределения зависит от быстродействия сумматоров и приблизительно равно 9tсл.

Рис. 2.9. Структурная схема вычислителя управления лучом фазированной антенной решетки

Рис. 2.10. Структурная схема матричного сумматора 8X8
Комбинационные схемы. Микропроцессоры применяются для замены комбинационных схем, выполненных на ИМС средней и малой степени интеграции. Такие схемы в РТУ выполняют функции блоков синхронизации, .кодирующих и декодирующих устройств, устройств управления и т. п. Цифровые автоматы реализуются в основном на -матричных МП БИС типа ППЗУ и ПЛМ; при этом используются классические методы теории конечных автоматов. Методы синтеза конечных автоматов достаточно подробно освещены в .литературе. В [1] описывается система автоматизированного синтеза автоматов на матричных БИС.
Эта сис тема предназначена для синтеза автоматов, поведение которых описано граф-схемами алгоритмов (ГСА), в качестве элементной базы используются ПЛМ, ППЗУ, регистры, дешифраторы. При синтезе автоматов на этой системе необходимо учитывать следующие ограничения: общее число вершин ГСА не более 1023, число различных микрокоманд в ГСА не более 511, число различных микроопераций в ГСА не более 127, число внутренних состояний автомата не более 1023. Из приведенных данных видно, что сложность синтезируемых автоматов ограничивается несколькими тысячами внутренних состояний. При построении более сложных автоматов используются МП БИС совместно с комбинационными схемами. Типовой пример такого применения МП БИС приведен в [31]. Рассмотрим его подробнее.

Рис. 2.11. Функциональная схема программируемого синхронизирующего устройства
Пример 2.6. Функциональная схема программируемого синхронизирующего устройства приведена на рис. 2.11. Устройство выполнено на БИС К589ХЛ4 и представляет собой многофункциональное синхронизирующее устройство (D5 — D11).
В устройстве можно выделить следующие основные узлы: схему формирователя импульсов (D1 — D4), схему временной задержки (D5 — D7) и формирования частоты следования импульсов (D8, D9), формирователь числа импульсов в пакете (D10 — D11).
Схема формирования импульсов выполнена на микросхемах К500ТМ131 (D1), К500ПУ124 (D2), К500ИЕ136 (D3) и К500ПУ125 (D4). Устройство запускается подачей импульса «Пуск», а также управляющих и адресных сигналов на ППЗУ, поступающих с магистрали передачи информации (МПИ). При приходе сигнала «Пуск» триггер D1 устанавливается в 1; этот сигнал поступает на счетчик. Счетчик D3 работает в режиме деления частоты входных импульсов 80 МГц на 4, что достигается подачей кода ООП на его входы DO — D3. Неопределенность начала появления импульсов относительно сигнала «Пуск» не превышает периода следования импульсов кварцевого генератора 12,5 не.
Полученная последовательность ЭСЛ-уровня преобразуется в ТТЛ-уровень микросхемой D4.
С выхода D4 импульсы поступают на схему временной задержки. Выходной импульс длительностью 25 не появится на выходе F D7 через время задержки, определяемое из выражения Кп=2п — (t3 — tH)f, где t3 — время задержки; Кп — код пересчета (на входах D микросхем D5 — D7); тя и f — длительность и частота входных импульсов.
С выхода СО D7 положительный перепад напряжения устанавливает триггер D13 в 1, разрешая этим прием импульсов с f=20 МГц на схему формирования частоты следования импульсов (D8, D9). В зависимости от кода пересчета Кп, подаваемого на входы D микросхем D8, D9 изменяется частота следования импульсов, снимаемых с выхода F D9, по следующему закону: Кп = 2п — Kд, где Ад — коэффициент деления устройства.
Формирователь числа импульсов в пакете собран на элементах D10, D11. На его вход поступают выходные сигналы с D12. Число импульсов в пакете N определяется из выражения Кп=2n — (N — 1). После подсчета N импульсов на выходе F D11 появится сигнал, который своим фронтом через D2 установит триггер D1 в 0. При этом счетчик D3 перейдет в режим загрузки и работа всей схемы остановится.
Выбор необходимой задержки, частоты следования и длительности пакета импульсов определяется управляющим 28-разрядным кодом, считываемым из ППЗУ, по адресу, поступающему от микропроцессора с МПИ. Данное устройство позволяет устанавливать временную задержку 50 не — 204,8 мке, период следования импульсов 50 не — 12,3 мке, число импульсов в пакете 3 — 256. Устройство может применяться для управления работой АЦП, МП БО и др.
2.2. ОСОБЕННОСТИ ПРИМЕНЕНИЯ МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ В РЭА
При проектировании РЭА на МП БИС, в отличие от комбинационных цифровых устройств необходима совместная разработка программного обеспечения и аппаратных средств. Основные этапы проектирования МПУ приведены на рис. 2.12.
На этапе постановки задачи определяются входные и выходные требования к МПУ, математические методы решения поставленной задачи, разрабатываются алгоритмы решения задачи и взаимодействия МПУ с РЭУ.
Анализируя алгоритмы, решаемые МПУ и РЭУ, формируются требования и ограничения на их реализацию. Эти этапы являются типичными для любого РЭУ и поэтому обычно не вызывают затруднений.

Рис. 2.12. Основные этапы проектирования микропроцессорных устройств
На последующих этапах процесс проектирования раздваивается на аппаратурную и программную части. Первый же этап: выбор типа МП и структуры МПУ требует от специалиста знаний элементной базы МПУ, их систем команд, имеющегося программного обеспечения, средств отладки и т. п. На основе этих знаний осуществляется разбиение структуры МПУ на аппаратурную и программную части. Далее, исходя из выбранной структуры МПУ, конкретизируются требования к программному обеспечению и аппаратурным средствам. Осуществляется предварительная разработка программы и аппаратуры. Оцениваются основные характеристики МЛУ. Эти характеристики сравниваются с требованиями, предъявляемыми к МЛУ. Если полученные характеристики являются удовлетворительными, то осуществляется совместная отладка программного обеспечения и аппаратурных средств. По результатам отладки выпускается техническая документация.
Если характеристики не удовлетворяют требованиям, предъявляемым к МЛУ, выбирается другой МП или изменяется структура МПУ и весь процесс проектирования повторяется. Если для всего имеющегося в распоряжении разработчика набора МП и допустимых структур построения МЛУ не будет найдено удовлетворительное решение, то необходимо изменить требования, предъявляемые (К МПУ. Это достигается либо выбором более эффективных математических методов и алгоритмов, либо перераспределением задач между РЭУ и МЛУ.
В книге основное внимание будет уделено следующим этапам: выбору типа МП и структуры МПУ, предварительной разработки программного обеспечения и аппаратных средств, определению характеристик МЛУ. Этапы постановки задачи и формирования требований к разрабатываемым устройствам подробно изложены в специальной литературе, например [30, 32].
Отладка программного обеспечения рассмотрена в [9 — 11].
Кроме разработки программного обеспечения можно выделить еще ряд особенностей применения МПУ в РЭА: реальный масштаб времени обработки сигналов, использование аппаратных микропроцессоров, разработка специальных периферийных устройств и интерфейсных схем.
Реальный масштаб времени обработки сигналов (РМВ). Под РМВ обработки сигналов понимается необходимость обеспечения временного ограничения на выполнение алгоритма обработки сигналов: Тпр<Т, где Тпр — время выполнения программы микропроцессором; Т — допустимое время выполнения программы. Значение Гпр зависит от выполняемого алгоритма обработки, типа МП, его системы команд, структуры и т. п. Значение Т определяется структурой и требованиями к РЭУ, параметрами обрабатываемого сигнала. Для различных РЭУ и сигналов Т определяется по-разному. Рассмотрим, как определяется Т для МЛ БПФ (см. рис. 2.5).
Пример 2.7. Пусть МП БПФ решает задачу спектрального анализа сигнала, имеющего следующие параметры: полоса анализируемых частот AF= = 100 кГц, длительность обрабатываемого сигнала Гс = 10 мс. Требуется определить Т для МП БПФ и МП БО.
Для обеспечения РМВ необходимо, чтобы допустимое время спектрального анализа T<TCl т. е. время выполнения программы БПФ МП должно быть не более 10 мс. Частота дискретизации (при использовании квадратурных каналов) Fa=AF — l00 кГц. Размерность обрабатываемого массива N=2AFTC = =2-103. Число выполняемых БО NBQ=N/2*log2N=ll 103. Допустимое время выполнения одной БО ТБО <0,9 мкс. Микропроцессор БО (см. рис. 2.3) не обеспечивает решение данной задачи в РМВ. Поэтому необходимо использовать в МП БО вместо двух — четыре умножителя, либо в МП БПФ использовать несколько МП БО.
Допустимое время согласованной фильтрации более чем в 2 раза меньше-времени спектрального анализа, так как включает вычисление обратного ДПФ л умножение на импульсную характеристику. Параметр Т для МП управления лучом ФАР (см.
рис. 2.9) определяется максимально допустимым временем обнаружения цели T0: Т<Т0. Для других применений МП в РЭА Т определяется по-иному.
Использование аппаратных микропроцессоров. Для большинст ва задач обработки сигналов быстродействие микропроцессорных вычислителей недостаточно. Необходимо построение многомикропроцессорных систем. В |[2, 33] приведены примеры таких систем.
Существенное повышение быстродействия МПУ может дать применение аппаратных микропроцессоров, реализующих наиболее сложные, с вычислительной точки зрения, участки алгоритма обработки. Так, использование матричного сумматора в вычислителе управления лучом ФАР (пример 2.5) позволяет осуществить расчет фазового распределения за время, приблизительно равное 9tсл.
Возможны различные структурные варианты использования аппаратных микропроцессоров совместно с программными, некоторые из них приведены на рис. 2.13. В [2] приведены программы, реализации алгоритмов БО и БПФ для МП серий КР580, К589. В табл. 2.2 представлены данные о числе операций, используемых в алгоритмах, и времени вычисления этих операций.
Из табл. 2.2 видно, что умножение занимает значительную часть времени вычисления БО. Использование умножителей КР1802ВРЗ для вычисления БО позволяет снизить время ее вычисления для МП КР580 до 3082 мкс, для К589 до 20,4 мкс, для КР1802 до 1,5 мкс.

Рис. 2.13. Структурные схемы подключения аппаратных микропроцессоров к программным:
а — микропроцессор выполняет базовую операцию по программе, хранимой в ПЗУ; б — операция умножения выполняется аппаратно; в — базовая операция выполняется аппаратно
Этапы разработки ССИС
Приведем некоторые данные из программы разработки сверхскоростных БИС (ССИС) на основе МОП-приборов (табл. 2.4) [36].
Теоретически сокращение размеров в n раз приведет к повышению плотности компоновки в п2 раз. Однако из-за того, что с ростом числа элементов на кристалле растет и площадь соединений, плотность компоновки максимально повышается только в m раз (m<n2). Пропорционально с сокращением линейных размеров элементов в n раз уменьшаются значения токов и напряжений, а потребляемая мощность уменьшается в п2 раз.
Принципиальный недостаток сокращения размеров элементов -состоит в том, что в п2 раз повышается сопротивление соединений, что приводит к повышению плотности тока в n раз. Это может привести к миграции атомов металла проводника и другим вредным эффектам, снижающим надежность.
Наряду с повышением качества МП БИС, существенной проблемой улучшения конструкций МПУ является сокращение площади монтажных плат, занимаемой соединениями. Суть проблемы заключается в том, что с ростом степени интеграции площадь соединений на кристалле или подложке превышает площадь, занимаемую активными элементами. Наряду с этим, в [37, 38] показано, что без проведения оптимизации соединений в БИС процесс повышения степени интеграции практически будет приостановлен вследствие достижения логическими элементами своих физических пределов.
Повышение эффективности использования площади БИС и .подложек связано с решением задач совершенствования размещения элементов и трассировки связей на кристалле и подложке; оптимизации структурных и схемотехнических методов построения логических элементов в кристалле и БИС на монтажных платах.
Проблема оптимизации соединений свойственна конструкциям БИС, микросборок и ФЯ, тем более что для ряда устройств (например, ИЦП) эти конструкции близки.
Рассмотрим некоторые пути повышения эффективности использования плошади кристалла БИС. Полученные результаты во многом справедливы и для перспективных конструкций МПУ,
Для оценки качества размещения элементов и трассировки связей на кристалле БИС используют коэффициент оптимизации «связи К:

где Lcb, 1св(опт) — средняя длина линий связи при произвольном и оптимальном размещении элементов соответственно. В [37] показано, что

где N — число логических элементов на кристалле или степень интеграции; а — усредненный шаг размещения элементов на кри-сталле;
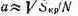
(SKp — площадь кристалла БИС). Подставив (2.8) в (2.7), получим

В табл. 2.5 приведены значения К для различной степени ин-теграции БИС.
Из табл. 2.5 видно, что с ростом степени интеграции N увели-чивается длина монтажных линий связи. Поэтому при конструи--ровании БИС и СБИС необходимо предусмотреть достаточную плошадь кристалла для выполнения межэлементных связей. Вели-чина этой площади зависит, в основном, от числа соединительных трасс или трассировочной способности кристалла БИС (Т):

где n — усредненная нагрузочная способность логического эле-мента, численно равная среднему числу входов логического эле-мента; n — коэффициент заполнения трасс кристалла; обычно среднее значение n = 0,5 — 0,7. Считая типовым случаем n = 0,5, a n = 3, получаем T = 2N5/6.
Площадь кристалла БИС для реализации межэлементных связей:

где ST — плошадь одной трассы. Для случая произвольного раз-мещения логических элементов при а= 1

где ят — шаг трасс.
Подставляя (2.10) в (2.9), получаем
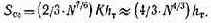
Как видно из (2.11), с ростом степени интеграции увеличивается доля площади кристалла, отводимая под соединения между логическими элементами. Для. уменьшения этой площади необходимо повышать: качество размещения элементов на кристалле БИС, разрешающую способность технологии изготовления, число-слоев межэлементных соединений. Однако эти направления не смогут решить проблему роста площади соединений, поскольку имеют свои пределы.
Новер линии
питания
ппд
Внутри и внепроцессорный обмен информацией осуществляется по асинхронному принципу с помощью сигналов «Выдано» (В) и «Принято (Я). При этом сигналы «Принято» всех БИС объединены, а «Выдано» соединяются следующим образом: В1 СК и В АУ, В2 СК и В D1 — D3, ВЗ СК и В D4 и DS, При таком соединении сигналов синхронизации обеспечивается разделение во времени приема данных и команд и запрещение приема команды в D1 — DS при наличии разрешенного прерывания. Соединением выводов С и Ф1 АУ и СК с соответствующими выводами управляющей памяти обеспечивается синхронизация передачи-приема МК.
Код состояния АУ выдается в канал К2 и далее поступает в канал К2 D1 — D3. В регистр состояния (канал K2) D4 и DS поступают сигналы прерывания СК Лр1 — Пр4.
Сигналы R0 и Rl D1 — D5 предназначены для начального запуска процессора. При ошибочном обращении к магистрали СК вырабатывает сигнал Я, который переводит D1 — D5 в режим формирования микропрограммы прерывания, вызванной этим ошибочным обращением к магистрали.
Интерфейс системной магистрали процессора включает 46 линий (табл. 1.3), 30 из которых (1 — 10, 18, 19, 29-46) по назначению совпадает с соответствующими линиями интерфейса микро-ЭВМ «Электроника-60». Остальные линии (11 — 17, 20 — 28) являются дополнительными.
Система команд процессора включает все команды микро-ЭВМ «Электроника-60», а также команды расширенной арифметики с фиксированной точкой. Для повышения производительности процессора в микропрограммах применено совмещение во времени отдельных этапов выполнения команд: считывание последующей команды совмещено с выполнением текущей, считывание данных из памяти — с не зависящими от него операциями. Применяемый в процессоре МПК БИС К588 электрически совместим с микросхемами серий 564 (при напряжении питания 5 В) и микросхемами серии 530 (при подключении не более двух нагрузок). Для повышения нагрузочной способности выводов внешнего интерфейса БИС процессора их можно подключать к системной магистрали через приемопередатчик К588ВА1, обеспечивающий согласование с 20 ТТЛШ-нагрузками и работу на емкостную нагрузку до 300 пФ. Потребляемая процессором мощность в динамическом режиме около 100 мВт.
Развитие МПК ведется в направлениях, указанных в 1.1, а также путем [совершенствования технологии МОП-структур, что постепенно выдвигает КМОП БИС и СБИС в первые ряды не только по малой потребляемой мощности, но и по быстродействию.
1.3. МИКРОСХЕМЫ ЗАПОМИНАЮЩИХ УСТРОЙСТВ
Основной элементной базой запоминающих устройств является полупроводниковая память, которую можно классифицировать по следующим основным признакам.
По функциональному назначению: сверхоперативная, оперативная, постоянная, буферная. Сверхоперативная и оперативная память предназначены для записи, хранения и считывания изменяемой информации (операндов, промежуточных результатов вычислений и т. п.). Принципиальных различий между сверхоперативной и оперативной памятью нет. Конструктивно оперативное ЗУ (ОЗУ) обычно выполняется в виде отдельного функционально и конструктивно законченного модуля, который подключается к интерфейсу [19]. Сверхоперативным ЗУ (СОЗУ) обычно называют регистры, конструктивно встроенные в МП БИС, например РОН БИС АУ (см. § 1.2). Время обращения к СОЗУ, как правило, не превышает одного такта работы МП. Поэтому при составлении программ стремятся максимально использовать СОЗУ, емкость которого из-за ограниченных размеров кристалла невелика (8 — 16 регистров). При отключении питания содержимое ОЗУ и СОЗУ теряется.
Для сохранения содержимого памяти при отключенном питании используют постоянное ЗУ (ПЗУ), которое предназначено-для хранения и считывания неизменяемой во время работы МПУ информации. В зависимости от способа записи информации различают: ПЗУ, программируемые маской, однократно программируемые пользователем (ППЗУ) и ПЗУ с многократной перезаписью информации, или репрограммируемые ПЗУ (РПЗУ) [4]. Первый тип ПЗУ используется при массовом производстве универсальных микро-ЭВМ, система команд которых не (изменяется. При разработке специализированных МПУ применяются ППЗУ и. РПЗУ, причем РПЗУ может применяться, например, на этапе отладки программы, когда вносится много изменений. Отлаженная программа записывается в ППЗУ и совместно с аппаратными, средствами представляет собой опытный образец разрабатываемого МПУ. Программирование ППЗУ осуществляется пережиганием, металлических или поликристаллических плавких вставок [4, 110].
Пережигание происходит при подаче импульсов напряжения соответствующей амплитуды и длительности на программирующие входы ППЗУ.В табл. 1.4 приведены режимы программирования наиболее распространенных биполярных ППЗУ.
Устройства, с помощью которых осуществляется запись (информации в ППЗУ, называются программаторами. В последнее время разработаны программаторы, работающие в автономном режиме или совместно с управляющей микро-ЭВМ [20].
solid windowtext
2. Полагая, что интенсивность отказов любой микросхемы равна 10~б, определяем время наработки на отказ МПУ:

3. Определяем среднее число выводов одной микросхемы и ее установочные размеры:

где ni — число микросхем i-го типа (i=1, 1); Kвыв i — число выводов микросхем i-гo типа; Квыв 1 — 38. Поскольку микросхемы устанавливаются в корпусах второго типа, имеющих шаг выводов 2,5 мм, считаем шаг установки средней микросхемы равным 50X38,5 мм, а ее размеры 40X28,5 мм.
4. Принимая размеры краевых полей x1, x2 y1, у2 равными соответственно-5, 5, 5 и 22,5 мм, определяем площадь печаткой платы, необходимую для размещения МПУ:
односторонняя компоновка
S1 = (3Ly + X1 + X2+ L0) (5by + y1 + y2 + bo) = 200X248,5 - 497 см»; двухсторонняя компоновка
S2 = (2Ly + X1 + х2 + Lo) (3bУ + у1 + у2 + bо) = 150x171.5 — 257 см».
5. Находим удельную мощность рассеивания МПУ: односторонняя компоновка
pi7K = 28,6/497 = 0,057 Вт/см2;
двухсторонняя компоновка
p2УД = 28,6/257 = 0,111 Вт/см2.
Сравниваем полученные значения с допустимым: р2уд>Рдоп. Корректируем значения: S2=28,6/0,08 = 357,5 см2 и Bп=357,5/171,5 = = 208,5 мм.
Параметры реализации
2. Используя выражения (3.6) и (3.10), определяем среднее время выполнения отдельных блоков алгоритма и частоту повторения этих блоков. Результаты расчетов сводим в табл. 3.10. Кроме того, считаем, что первый блок алгоритма может быть реализован на микросхемах К.573РФ4, К.573РФ6А. Вычисление БО выполняется на МП БО, представленных в табл. 3.7.
3. Анализ времени выполнения отдельных блоков алгоритма спектрального анализа показывает, что его реализация в реальном масштабе времени возможна только при распараллеливании вычислений. Для оценки этой возможности построим матрицу операндов, фрагмент которой приведен в табл. 3.11.
4. По данным матрицы операндов можно определить блоки алгоритма, допускающие их одновременное вычисление. В табл. 3.12 приведена последовательность вычислений отдельных блоков алгоритма.
Современный этап развития радиоэлектронной аппаратуры
Современный этап развития радиоэлектронной аппаратуры (РЭА) характеризуется широким применением методов цифровой обработки сигналов, реализуемых с использованием микропроцессорных средств. Однако ограниченные вычислительные возможности существующих микропроцессорных средств не позволяют обеспечить требуемые параметры реализации большинства алгоритмов обработки сигналов на одном микропроцессоре, что приводит к необходимости распараллеливания вычислений либо использования наряду с программными аппаратных средств. Выбор конкретной структуры построения микропроцессорного устройства обработки радиосигналов зависит от особенностей реализуемого алгоритма и конкретного набора микропроцессорных средств, на базе которых предполагается реализовать исходный алгоритм. Это порождает множество вариантов построения микропроцессорных устройств, выполняющих функции некоторой части РЭА.
За последнее время появилось много работ отечественных и зарубежных авторов, посвященных проектированию и применению микропроцессорных средств в различных отраслях техники, в том числе и в радиоэлектронике.
В данной книге приведены необходимые справочные сведения, методы и алгоритмы инженерного проектно-конструкторского синтеза микропроцессорных устройств обработки радиосигналов на ранних этапах разработки, включая по возможности весь комплекс вопросов от анализа заданного алгоритма до оценки конструктивных параметров его реализации на базе различных микропроцессорных средств. Предлагаемые алгоритмы формализованы и могут быть достаточно просто реализованы в виде пакета программ.
Большое внимание в книге уделяется вопросам создания специализированных вычислителей на комбинационных схемах или аппаратным процессорам, работающим совместно с программируемыми микропроцессорными устройствами. Показана эффективность этого известного приема для обеспечения высокой производительности устройств.
Ограниченный объем книги не позволил подробно рассмотреть вопросы разработки и отладки программного обеспечения МПУ. Эти вопросы изложены в [9 — 12].
Структурная схема формирователя адресов считывания ОЗУ и ПЗУ
Разрядность произведения выбирается с учетом требуемой точности реализации последующих вычислений. Так как в исходных данных эти требования не задавались, считаем достаточной разрядность произведения 8 бит. Итак, блок коррекции входных отсчетов может быть реализован на ПЗУ емкостью 4КХ8.
Таким образом, в результате анализа требований реализации исходного алгоритма установлено: для обеспечения заданного значения динамического диапазона выходного сигнала необходимо ввести этап коррекции действительной и мнимой частей входных отсчетов; внеполосное подавление до уровня — 43 дБ обеспечивается весовой обработкой входных отсчетов с помощью окна Хэмминга; система счисления с фиксированной запятой lк.ч=30; число отсчетов входного массива N=512; частота дискретизации fH>200 кГц; полоса пропускания эквивалентного фильтра Дf = 544 Гц.
Построение различных вариантов реализации алгоритма спектрального анализа. С целью ограничения количества вариантов реализации используем метод отсечений, позволяющий исключать варианты, которые не могут привести к оптимальному решению. Критериями оценки вариантов являются ограничения на реализацию алгоритма спектрального анализа: Tс>2,5 мс, q>40 дБ, T>20 000 ч и руд<0,08 Вт/cm2, Fд>200 кГц и др. Возможность выполнения этих ограничений определяется характеристиками модулей МПУ: АЦП, МП, модулей ОЗУ, ПЗУ. Поэтому определим варианты реализации основных модулей МПУ.
Построение и выбор вариантов реализации АЦП. Для решения этой задачи иеобходимо определить допустимый для аналого-цифрового преобразования уровень потерь.
Известно [2], что динамический диапазон на выходе цифрового устройства обработки сигналов определяется следующим образом:

где d — динамический диапазон входного сигнала; Ку= 10 lg AfTc — коэффициент, характеризующий увеличение отношения сигнал-шум на выходе устройства; Пацп, Пбпф потери за счет аналого-цифрового преобразования и вычисления БПФ соответственно:

Будем считать, что П3ад<6,9 дБ, ПБПФ=10 лВ. В соответствии с методикой, изложенной в § 3.5, выбираем АЦП.
1. Так как FH>200 кГц, из табл. 3. 8 определяем, что для обеспечения П8>2 дБ допустимая длительность выборки: ф<0,36 Гп = 1,8 мкс.
2. Определим разрядность АЦП, обеспечивающую требуемый уровень яотерь:
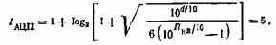
где Пкв=Пзад — Пф =4,9 дБ.
3. Определенным в пп. 1 и 2 ограничениям удовлетворяют АЦП К1107ПВ1 и КП08ПВ1. Другие типы АЦП из дальнейшего рассмотрения исключаются.
Построение и выбор вариантов реализации МП осуществляется в соответствии с алгоритмом, рассмотренным в § 3.2. Модель алгоритма спектрального анализа приведена на рис. 3.12,6. Алгоритм содержит два цикла (х8 — Х12 и X7 — X14). Вероятность перехода рij между вершинами цикла p12,8=0,9961, p12,13=0,0039, а p14,7=0,89 и p14,15=0,ll. Другие значения рij=1.
Исходной элементной базой реализации МП являются данные таблиц 1.2, 3.5, 3.6 и результаты анализа алгоритма.
1. Определяем разрядность МП. Она рассчитывается исходя из требуемой точности представления информации на выходе МП. Однако, поскольку в данном случае принята система счисления с фиксированной запятой, считаем: 1=1 + L=15. В примере 3.1 было показано, что это значение превосходит I, вычисленное из условия обеспечения требуемой точности представления информации на выходе МП.
Содержание команды
Модульный принцип построения. Этот принцип предполагает разделение электрической схемы МПУ на функционально завершенные модули. Исходя из классической схемы вычислительногоустройства, любое МПУ должно включать как минимум микропроцессор, ЗУ и УВВ. Конструкция модуля представляет собой либо функциональную ячейку (ФЯ) (см. § 2.3), либо микросборку (МСБ), либо СБИС. Современные модули МПУ чаще всего выполняются в виде ФЯ. Приведенный выше состав модулей позволяет построить универсальное МПУ. При решении вопроса о функциональном составе модулей МПУ необходимо учитывать многофункциональность (универсальность) и специализацию модулей. Повышение универсальности модулей обеспечивает сокращение их. номенклатуры, снижение затрат на проектирование. Специализация модулей является средством достижения соответствия структуры МПУ выполняемым алгоритмам и тем самым повышения быстродействия, а следовательно, и эффективности применений1 МПУ в РЭА.
Модульный принцип конструирования МПС дает возможность, разработчику выбирать только необходимые ему модули и постепенно наращивать функциональные возможности МПУ. Иногда при проектировании МПУ, реализующих конкретные алгоритмы, для обеспечения требуемых характеристик достаточно небольшой фрагмент алгоритма реализовать аппаратно. Конструирование специального модуля или БИС для реализации такого фрагмента может оказаться неоправданно дорогим. Целесообразно на модуле МП установить специальный соединитель для подключения малых модулей, реализующих конкретные функции. Такой подход был реализован в микромодульных платах iSBX [3].
Для расширения функциональных возможностей одноплатной микро-ЭВМ разработаны три модуля: последовательного вводавывода iSBXx25i, параллельного ввода-вывода iSВХх350 и арифметического процессора с плавающей точкой iSВX332.
При менение таких модулей увеличивает гибкость одноплатной микро-ЭВМ. Для обеспечения аппаратной специализации системы разработана переходная плата iSBXyx960=5, содержащая пять гнезд шины iSBX, к которым разработчик может подключать специальные аппаратные модули.
Модульный принцип построения позволяет повысить эффективность применения МПС для конкретных задач. Это достигается выбором типа и числа модулей, учитывающих особенности решаемого алгоритма. Например, микро-ЭВМ «Электроника С5-12» в минимальной конфигурации представляет собой микропроцессор, содержащий ПЗУ емкостью 1КХ32 и ОЗУ емкостью 128X16. Микро-ЭВМ может использоваться совместно с модулями «Электроника С5-121» — АЦП (число каналов 115, время преобразования 10 мс, погрешность 0,4%), «Электроника С5-125» — модуль внешнего ОЗУ емкостью 8К байт, «Электроника C5-I123» — модуль сопряжения с устройством ввода-вывода и некоторыми другими.
Комбинируя модули, можно получать вычислительные средства различного назначения. Приведем некоторые из них: микро-ЭВМ+ +ОЗУ — минимальная конфигурация одноплатной микро-ЭВМ с относительно большим объемом памяти, микро-ЭВМ + АЦП — применяется в измерительных приборах, цифровых следящих системах.
Магистральный принцип обмена информацией. Некоторые выводы МПС должны соединяться с различными внешними устройствами. Это обеспечивается объединением выводов МПС в магистрали (шины) и мультиплексированием во времени обмена информацией между модулями. Весь информационный поток, циркулирующий в МПС, обычно разбивается на три группы: адреса, дан-яые и управление. В соответствии с этим выделяют шину данных, шину адресов и управляющую шину. Применяя последовательно временное мультиплексирование, можно построить МПС с трех-, двух- и однотипной структурой.
При выборе структуры МПУ необходимо учитывать следующее: при уменьшении числа шин увеличивается площадь кристалла или модуля, отводимая под функциональные элементы, и тем самым повышаются функциональные возможности МПС.
Вместе с тем применение временного мультиплексирования обмена информацией приводит к снижению быстродействия и необходимости использования дополнительных буферных регистров.
В некоторый период времени только два устройства могут быть одновременно подключены к шине. Одно из них — ведущее, другое — ведомое. Ведущим устройством обычно является МП. При обмене информацией между МП и ведомым остальные устройства, подключенные к шине, не должны им мешать. Такое раздельное использование шины достигается различными способами подключения к ней выводов устройств. Известны три способа подключения: логическое объединение, объединение с помощью схем с открытым коллектором и объединение с использованием схем с тремя состояниями [4].
Логическое объединение выполняется с помощью логических схем ИЛИ, И (рис. 1.2,а). На входы логических вентилей поступают информационные сигналы И1 — И4. Подключением этих сигналов к шине управляют сигналы У1 — У4, схема формирования которых приведена на рис. 1.2,6. На вход схемы поступают два адресных сигнала: Al и А2. Схема формирует четыре взаимоисключающих управляющих сигнала У1
— У4. (Вместо этой схемы может быть использован любой дешифратор типа 1 из и на два входа и более. Максимальное число подключаемых устройств определяется числом входов логического элемента ИЛИ.
Объединение с помощью схем с открытым коллектором предполагает электрическое соединение выходов нескольких логических элементов, как это показано на рис. 1.2,в. В схемах с открытым коллектором отсутствует .нагрузочный резистор. Выходы схем с открытым коллектором объединены с использованием общего нагрузочного резистора RK. Выходной сигнал равен 0, если сигнал на любом из объединенных выходов равен 0, и 1, если сигналы на всех объединенных выходах равны 1. По аналогии с реализуемой логической функцией такой способ подключения называют «монтажным ИЛИ», или «монтажным И». При поступлении на вход управляющего сигнала 1, на выходе схемы ИЛИ появляется 1 (независимо от значения информационного сигнала И); в результате общий выходной сигнал не меняется.
При ( низком уровне управляющего сигнала сигнал на выходе схемы ИЛИ равен информационному. Итак, если один управляющий сигнал равен 0, а остальные II, то общий выходной сигнал повторяет значение информационного входа схемы ИЛИ, имеющей низкое значение сигнала управления.
Для подключения устройств к шине с использованием схем с открытым коллектором требуется меньшее число логических элементов, чем при логическом объединении. Однако шины на схемах с открытым коллектором (как и шины с логическим объединением) имеют ограниченное применение. В основном, это обусловлено следующими причинами:
1. Значение выходного тока стандартной управляющей схемы, выполненной по ТТЛ-технологии, около 20 мА. Поэтому с помощью «монтажного ИЛИ» можно объединить сравнительно немного (не более 20) схем с открытым коллектором.

Рис. 1.2. Структурные схемы подключения выходов нескольких микросхем к общей шине:
а — логическое объединение сигналов; б — схема формирования управляющих сигналов; в — подключение с помощью схем с открытым коллектором; г — подключение с помощью схем с тремя состояниями
2. Нагрузочный резистор занимает место на плате и потребляет около 1 мА, когда шина находится в рабочем состоянии. Наличие этого тока еще больше снижает уровень сигнала в шине.
Объединение с использованием схем с тремя состояниями свободно от недостатков, присущих рассмотренным выше способам. На рис. 1.2,г нагрузочными являются транзисторы VT1 и VT3. На входы транзисторов подаются управляющие и информационные сигналы. Каждая пара транзисторов управляет подключением одного устройства. При подключении устройства к шине транзисторной парой управляет информационный сигнал. Например, при подаче лог. 1 на VT1 и лог. 0 на VT2 транзистор VT1 открыт, VT2 закрыт; на шине — лог. 1. Если на VT1 подается 0, а на VT2 1, то на шине — лог. 0. Одновременно значение управляющего сигнала на входах транзисторов VT3, VT4 равно 0.
Оба транзистора закрыты, и схема находится в третьем устойчивом состояния: «цепь разомкнута». В этом состоянии через схему протекает очень маленький ток. Шины с тремя состояними имеют следующие преимущества:
схема в состоянии «цепь разомкнута» потребляет ток не более 0,4 мА (схема с открытым коллектором около 2 мА), поэтому в схемах с тремя состояниями можно объединить гораздо больше выходов (до 50);
не требуется дополнительных логических схем. Микропроцессорные БИС имеют буферные схемы с тремя состояниями внутри кристалла, для этого предусматривается дополнительный вывод;
нет необходимости использовать нагрузочный резистор.
При разработке МПУ логическое объединение и объединение с помощью схем с открытым коллектором используются обычно при организации внутренних шин МП, модулей ОЗУ, ПЗУ и др. При организации внешних по отношению к МП шин обычно используются схемы с тремя состояниями.
Наращиваемость вычислительной мощности МП С. Основным отличием МПС от других изделий вычислительной техники является реализация их в виде одной или нескольких БИС. Современные уровни развития полупроводниковой технологии и материаловедения позволяют производить БИС на кристаллах площадью» до 50 мм2. Небольшая площадь кристалла приводит к необходимости расчленения МПУ на отдельные БИС. Факторами, ограничивающими функциональную сложность этих БИС, являются число выводов и потребляемая мощность. Последний фактор особенно важен для .быстродействующих МП БИС, выполненных по биполярной технологии.
Современные МПК БИС включают несколько десятков БИС различного назначения. Разрядность МП БИС обычно составляет 4, 8, реже 16 бит. Микропроцессорные БИС с ограниченной разрядностью называются секционированными. Обеспечение требуемой разрядности проектируемых МПУ достигается путем объединения необходимого числа БИС. При этом обычно не требуется дополнительных аппаратных затрат, достаточно только объединить соответствующие выводы и цепи сигналов переноса.
Более подробно этот вопрос будет рассмотрен в § 1.2. Детальный анализ проблем построения различных МПС на секционированном МПК БИС Ат2900 рассмотрен в [5].
Таким образом, основные принципы построения МПС: микропрограммное управление, модульность построения, магистралыклй обмен информацией и наращиваемость вычислительной мощности позволяют разрабатывать МПУ, структура, система команд, быстродействие и разрядность которых учитывают особенности реализуемых алгоритмов.
1.2. МИКРОПРОЦЕССОРНЫЕ КОМПЛЕКТЫ БИС
Микропроцессорные средства включают: МПК БИС, однокристальные и одноплатные микропроцессоры, микро-ЭВМ, микроконтроллеры, устройства ввода-вывода, хранения, отображения, коммутации информации и т. п. Основой построения МПС являются: МПК БИС, микросхемы запоминающих устройств и преобразования вида информации (АЦП, ЦАП).
Микропроцессорный комплект БИС представляет собой набор электрически совместимых цифровых БИС, достаточный для построения различных МПУ. Существующие МПК БИС можно разделить на две группы: с фиксированной системой команд и секционированные. Основное различие этих комплектов заключается в способе реализации устройства управления. В первом случае оно реализовано на комбинационных схемах и конструктивно объединено с арифметическим устройством в одной БИС. Это объединение представляет собой функционально законченный микропроцессор с фиксированной системой команд, ориентированной на широкий круг решаемых задач. Такие МПК обычно имеют стандартные отладочные средства и относительно развитое программное обеспечение, что обеспечивает их широкое применение.
Примером однокристального микропроцессора является центральный процессорный элемент КР580ИК.80. Особенности построения и реализации арифметического и управляющего устройств делают недоступным программисту микропрограммный уровень управления. Он оперирует командами, которые не может изменить. Вместе с тем проектирование конструктивно встраиваемых в РЭА МПУ предполагает их специализацию в соответствии с реализуемым алгоритмом.
Кроме того, как .будет показано в гл. 2, одним из основных требований, предъявляемых к МПУ, является реальный масштаб времени вычислений решаемых алгоритмов. Необходимость специализации системы команд и структуры проектируемых МПУ ограничивает применение однокристальных микропроцессоров в РЭА.
Основной элементной базой конструктивно встраиваемых в РЭА МПУ являются секционированные МПК БИС, у которых в отличие от однокристальных микропроцессоров управляющее устройство реализовано на принципах микропрограммного управления. Такой подход обеспечивает доступ разработчика к уровню микрокоманд, что позволяет изменять команды и соответствующие им микропрограммы исходя из решаемых алгоритмов. Секционированные МПК имеют различные системы команд, разрядность, типы интерфейса ввода-вывода и т. п. Проектируемые на основе секционированных МПК МПУ обладают большой гибкостью, так как расширение функциональных возможностей обеспечивается изменением отдельных микрокоманд или заменой всей памяти микропрограмм.
Построение арифметического устройства требуемой разрядности осуществляется объединением 4-, 8- или 16-разрядных процессорных секций. Микропрограммное устройство управления выполняется на одной или нескольких БИС. Соединив между собой несколько БИС микропрограммного управления, можно увеличить объем микропрограммной памяти. Объединение арифметического и управляющего устройств позволяет получить базовую структуру микропроцессора. Подключение к ней специализированных БИС ввода-вывода, вспомогательных аппаратных микропроцессоров и других специализированных микросхем приводит к повышению производительности МПУ.
Использование секционируемых МПК обеспечивает гибкость проектирования как по аппаратным решениям, так и по реализации требуемой системы команд. Однако при этом предполагается, что разработчик знает возможности и особенности всех микросхем, входящих в состав МПК, принципы объединения их в устройство, организацию синхронизации в устройстве; владеет методами разработки и отладки микропрограмм.
Вместе с тем работа на микропрограммном уровне создает и определенные трудности. Микропрограммный уровень определяется конкретными схемными решениями, поэтому программирование на этом уровне требует от разработчика знаний аппаратных особенностей МПК, учета временных соотношений и т. п. Кроме того, разработка оригинальной .системы команд приведет к необходимости проектирования дополнительных аппаратных средств и программного обеспечения, предназначенного для отладки программ. Это обуславливает увеличение сроков [разработки и повышение стоимости МПУ, проектируемых «а основе секционируемых МПК БИС.
Микропроцессорные комплекты БИС отличаются своими характеристиками, основными из которых являются: число БИС в комплекте, число внутренних магистралей, разрядность, система микрокоманд, число регистров общего назначения, число уровней прерывания, быстродействие, число буферных регистров (портов) ввода-вывода (Явв, ЯВЫв) и др.
Число БИС в комплекте во многом определяет функциональные возможности МПК. Наличие в составе комплекта разнообразных специализированных БИС позволяет проектировать функционально законченные МПУ при минимальном использовании микросхем средней и малой степени интеграции. Если число специализированных БИС в МПК ограничено, то некоторые функциональные узлы приходится проектировать на (микросхемах малой и средней степени интеграция, что снижает плотность упаковки МПУ и ухудшает его конструктивные параметры. Кроме того, использование специализированных БИС для аппаратной реализации некоторых сложных (с вычислительной точки зрения) функций повышает производительность МПУ.
Как было показано в § 1.1, число внутренних магистралей микропроцессорных БИС колеблется от одной до трех. При выборе МПК необходимо учитывать, что уменьшение числа магистралей снижает процент использования площади кристалла под магистрали, а также быстродействие этих микросхем.
Большинство современных МПК имеют разрядность 4, 8 или 16 бит.
Ограничение разрядности обусловлено размерами кристалла и технологическими допусками изготовления логических элементов. Биполярные секционированные МПК обычно имеют разрядность 4 и 8 бит. Разрядность МПК, выполненных по МОП-технологии, достигает 16 бит.
Система микрокоманд (как и число БИС) определяет функциональные возможности МПК. Системы микрокоманд распространенных МПК БИС, их (форматы, разрядность, особенности реализации подробно рассмотрены в [6 — 12]. Отметим, что при выборе типа МПК необходимо, чтобы его система микрокоманд соответствовала решаемому алгоритму. При этом особое значение приобретают микрокоманды, реализующие специальные функции, например умножение, деление, нормализацию чисел и т. п. Эти функции могут быть реализованы аппаратно на специализированных БИС, либо программно, например в МПК БИС КМ1804 [12]. Для ряда применений, не требующих высоких скоростей обработки информации, программная реализация специальных функций может оказаться предпочтительней, так как не требует дополнительных аппаратных затрат.
Число регистров общего назначения (РОН) определяет емкость внутренней сверхоперативной памяти МП и колеблется от 2 до 16. Увеличение числа РОН в МПК дает возможность хранить в них большее число исходных данных и промежуточных результатов вычислений. При этом в микропрограмме вычислений будут шире использоваться микрокоманды типа регистр-регистр, а следовательно, уменьшится число обращений к ЗУ. Быстродействие выполнения такой микропрограммы будет выше.
Прерывание представляет собой процедуру обмена данными с внешними устройствами. При этом инициатором обмена является внешнее устройство, которое посылает сигнал «Запрос на прерывание». Получив этот сигнал, МП приостанавливает выполнение основной программы и переходит к реализации специальной подпрограммы обмена, называемой подпрограммой обработки прерываний. Эта подпрограмма выключает ряд действий, описание которых можно найти в [10, 13].
Число уровней прерывания опре деляет число внешних устройств, способных обращаться к микропроцессору и обмениваться с ним информацией. Этот параметр имеет особое значение при использовании МПК для построения систем сбора и распределения данных, характеризующихся большим числом датчиков информации, имеющих различный приоритет.
Параметром, характеризующим быстродействие МПК, обычно является время цикла выполнения простейшей микрооперации. Поскольку микрокоманды состоят из последовательности микроопераций различной длины, то время цикла выполнения микроопераций дает очень относительное представление о реальном времени реализации микрокоманд. Один из методов определения времени выполнения микрокоманд приведен в Приложении. При совместном включении нескольких арифметических и управляющих устройств с различным быстродействием такт работы всего МПУ определяется длительностью такта устройства, обладающего меньшим быстродействием.
Число буферных регистров (портов) ввода-вывода является параметром, характеризующим структуру МПК БИС. Для секционированных МПК характерно использование многопортовых структур (обычно двух-трех). Увеличение числа портов ввода-вывода приводит к уменьшению длительности цикла выполнения микрокоманды, упрощает построение МПУ, реализованных по «конвейерной» структуре. Остальные параметры МПК такие же, как и у Других цифровых микросхем. Это прежде всего уровни напряжений логических сигналов (U0 и U'), потребляемая мощность, устойчивость к изменениям напряжения питания, коэффициент объединения по входу, коэффициент разветвления по выходу (нагрузочная способность), помехоустойчивость и др.
Функциональная сложность МПК БИС определяется максимальными размерами полупроводниковых кристаллов, изготовление которых может обеспечить современный уровень развития технологии. Небольшие размеры кристаллов (до 50 мм2) требуют упрощения структур и ограничения разрядности БИС.
Для опреде ления содержимого внутренних регистров МП требуются специальные программы, обеспечивающие вывод содержимого регистров из МП. Большее число выводов БИС упрощает разработку МПУ. Однако корпуса, имеющие большее число выводов, занимают большую площадь на плате. Ограниченное число внешних выводов приводит к необходимости использования одних и тех же выводов для нескольких целей, например для ввода и вывода данных.
При построении МПУ необходимо обеспечить электрическое сопряжение между микросхемами МПК БИС. Условиями правильного сопряжения являются одинаковые представления логических О и 1 (U°, U1) и обеспечение допустимой нагрузки на каждый выход. При построении МПУ на одном или электрически совместимых МПК БИС первое условие выполняется и задача электрического сопряжения сводится к обеспечению допустимой нагрузки на каждый выход. Для МПК, выполненных по биполярной технологии, это условна может быть записано в виде неравенства [4]
I1 макс<I1вых, I0макс <I0вых, (1.1)
где I1вых — значение тока, отдаваемого в нагрузку; I'макс — максимально допустимый ток нагрузки, при котором напряжение на выходе соответствует U1; I°ВЫХ — ток микросхемы; I°макс — максимально допустимый ток нагрузки, при котором напряжение на выходе соответствует U0.
Нагрузочная способность по переменному току МПК БИС, выполненных по МДП функционально-технологическому принципу, существенно ниже нагрузочной способности по постоянному току и фактически определяется максимальной емкостью Сн.макс, которую можно подключить к выходу схемы:
CД < Cн.макc, (1.2)
где Сн — емкость нагрузки, складывается из входных Свх и выходных Свых емкостей входов (выходов) микросхем, подключенных к данному выходу, и емкости монтажа См.
Для сопряжения МПК БИС, имеющих различные уровни напряжений логических сигналов, используются специальные схемы, называемые усилителями-трансформаторами уровней напряжений. Например, микросхема К1800ВА4 позволяет сопрягать МПК ЭСЛ и ТТЛ.
Наиболее распространенными являются цифровые микросхемы вообще и МПК БИС в частности, выполняемые по принципам транзисторно-транзисторной логики. Поэтому некоторые микросхемы, выполняемые по другим принципам, могут объединять в кристалле буферные трансформаторы уровней, обеспечивающие по выходу и входу ТТЛ-уровни напряжений логических сигналов.
В настоящее время отечественная промышленность выпускает различные МПК БИС. Технические характеристики и описания этих комплектов приводятся в [6, II4 — 16]. Из известных и освоенных в производстве МПК БИС для использования в РЭА наибольший интерес представляют МПК БИС серий К588, К1800, КР1802, КМ1804. Состав и основные характеристики микросхем, входящих в эти МПК, приведены в табл. 1.2. Подробное описание МПК БИС содержится в [54].
Микропроцессорный комплект БИС КР1802 выполнен по ТТЛШ-функционально-технологичеокому принципу. Электрически программируемая логическая матрица КР556РТ1 позволяет (разработчику записать в «ее оригинальную систему команд, в (Наибольшей степени учитывающую специфику конкретного применения. Наличие матричных умножителей КР1802ВРЗ — КР1802ВР5, а также сумматора на четыре входа обеспечивают значительное повышение производительности МПУ при выполнении арифметических операций. В § 2.1 приведены примеры построения некоторых устройств обработки сигналов на МПК КР1802. Важнейшими особенностями МПК (с точки зрения обработки сигналов) являются [16]:
многопортовая структура БИС. Микросхемы обработки (КР1802ВС1, КР1802ВР1, КР1802ВР2) имеют два порта ввода-вывода; БИС параллельных умножителей КР1802ВРЗ — КР1802ВР5 — три порта, БИС обмена информацией (ОИ) КР1802ВВ1 — четыре, а БИС сумматора — пять портов ввода-вывода. Через эти парты может одновременно осуществляться выборка операндов и выдача результатов обработки. Такая организация БИС ориентирована на эффективное выполнение двухопе-рандовых операций, составляющих большинство (до 80%) всех операций обработки;
использование регистров общего назначения вне обрабатывающих БИС обеспечивает большее быстродействие МПУ, объединяющих несколько разнотипных БИС обработки информации, а также расширяет возможности разработчиков в применении регистров для реализации различных системных функций;
обеспечение конвейерной обработки информации. В БИС обработки информации каждый порт ©вода-вывода имеет регистр, на котором фиксируются операнды или результат. Последовательное объединение этих БИС и управление их входами-выходами позволяет проектировать устройства с конвейерной организацией обработки. Это обеспечивает проектирование МПУ, быстродействие которых определяется временем одного цикла БИС (около 150 нс). Подробное описание МПК БИС КР1802 приведено в [6].
Микропроцессорный комплект БИС КМ1804 выполнен также по ТТЛШ-функционально-техналогическому принципу. Архитектура МПК предусматривает параллельное наращивание разрядности, микропрограммное управление, конвейерную обработку. Эти архитектурные особенности обеспечивают высокую гибкость применения МПК КМ 1804 при построении различных МПУ. В отличие от МПК КР1802 в составе МПК КМ1804 нет БИС, аппаратно реализующих арифметические операции. Вместе с тем МПК КМ1804 отличается большим функциональным разнообразием БИС и, что особенно важно, включает большое число БИС, предназначенных для построения интерфейсных схем ввода-вывода. Комплекты КР1802 и КМ1804 электрически совместимы. Совместное их использование позволит проектировать МПУ обработки сигналов, отличающиеся высокой производительностью и гибкостью. Комплект КМ1804 (является аналогом МПК Ат2900. Построение- различных МПУ на базе Ат2900 подробно рассмотрено в [5, 12].
СПИСОК УСЛОВНЫХ ОБОЗНАЧЕНИИ
d — динамический диапазон входного сигнала
FД — частота дискретизации
Fобр — интервал об;работки по частоте
H(пДw) — дискретная импульсная характеристика системы в частотной области
h(nДT) — дискретная импульсная характеристика системы во временной области
L — число этапов вычисления быстрого преобразования Фурье
l — разрядность микропроцессора
laцп — разрядность АЦП
N — размерность входного массива
р, Рдоп — удельная мощность рассеивания и ее допустимое значение
r — основание преобразования
S — площадь монтажной платы
S(nДw) — спектр дискретного входного сигнала
s(t), s(nДT) — непрерывный и дискретный входные сигналы
T — допустимое время выполнения программы микропроцессором
Tnp — время выполнения программы микропроцессором
Тс — длительность обрабатываемого сигнала
tу — время выполнения операции умножения
Y(nДw) — спектр дискретного выходного сигнала
ДF — ширина спектра анализируемого сигнала
Дf — полоса пропускания фильтра
бf — расстояние между центральными частотами соседних фильтров
б, бдоп — среднее квадрэтическое отклонение погрешности вычислений на выходе микропроцессора и его допустимое значение
кратная 4. Система команд по
|
Наименование |
Обозначение |
Тип корпуса |
Основные электрические характеристики |
Примечание |
|
|
16-разрядное наращиваемое АУ |
К588ВС1, К588ВС2 |
Серия K5S8 2124.42 — 1 |
Tц
= 1,0 мкс; 150 логических |
Uп = 5 В±10%. Система |
|
|
Наращиваемая УП |
К588ВУ1 |
2124.42 — 1 |
произведений |
1.1305.909 — 82 |
|
|
Арифметический расширитель |
К588ВР1А — К588ВР1Г |
2124.42 — 1 |
tу<5 мкс; 1=8 бит |
Пвв-выв = 2 |
|
|
Системный контроллер |
К588ВГ1 |
2124.42 — 1 |
Число входов прерываний 7 |
Тц=600 нс |
|
|
Многофункциональный буферный регистр |
К588ИР1 |
2121.28 — 4 |
Tц
= 150 не; l=8 бит |
Пвв=1; Пвыв=1 |
|
|
Магистральный приемопередатчик |
К588ВА1 |
2121.28 — 4 |
Tц=150 нc; l=8 бит |
Пвв-выв=2 |
|
|
Умножитель 16X16 |
К588ВР2 |
4118.24 — 2 |
ty=2 мкс |
Пвв-выв= 1 |
|
|
Кодер-декодер последовательного мультиплексного канала |
К588ВГЗ |
2124.42 — 1 |
Тактовая частота кодера 2 МГц, декодера 12 МГц |
Преобразует код «Манчестер 2» в последовательный униполярный |
|
|
АЛУ |
К1800ВС1 |
Серия К1800 2207.48 — 1 |
U„= — 5,2 В±5%; |
Аналог Мс10800 |
|
|
Микропрограммное устройство управления |
К1800ВУ1 |
2207.48 — 1 |
Uц= — 2 В±5%; Tц = 28 нс; l=4 бит |
Аналог Мс10801 |
|
|
Схема синхронизации |
К1800ВБ2 |
2120.24 — 1 |
Разрядность МК — 8 бит |
Аналог Мс10802 |
|
|
Схема управления ОЗУ |
К1800ВТЗ |
2207.48 — 1 |
1=А бит; Рп=1,6 Вт |
Аналог Мс 10803 |
|
|
Двунаправленный трансформатор уровней |
К1800ВА4 |
2103.16 — 1 |
t3>8 нс; Рп=0,7 Вт |
Аналог Мс1080А |
|
|
8-разрядное АУ |
КР1802ВС1 |
Серия КР1802 2206.42 — 1 |
Гц = 120 не |
Uи=5 В±10% |
|
|
Блок регистров общего назначения (16X4) |
КР1802ИР1 |
239.24 — 2 |
Гц=45 не |
Ри=1,4 Вт |
|
|
Арифметический расширитель |
КР1802ВР1 |
2206.42 — 1 |
Гц-90 не; г-16 бит |
||
|
Схема обмена информацией (4X4) |
КР1802ВВ1 |
2206-42 — 1 |
Гц = 60 не; Рш=1Л Вт |
Пвв-выв = 4 |
|
|
Схема интерфейса |
КР1802ВВ2 |
2206.42 — 1 |
Гц = 100 не |
Рп=1 Вт |
|
|
Электрически программируемая логическая матрица |
К.Р556РТ1, КР556РТ2 |
2121.28 — 1 |
48 логических произведений |
Pп= 0,8 Вт |
|
|
Умножитель последовательный (8X8) |
КР1802ВР2 |
2206.42 — 1 |
tт>1,0 мке; tД>1,8 мкс |
Пвв-выв = 2; Рп=1,5 Вт |
|
|
Умножитель параллельный (8X8) |
КР1802ВРЗ |
2206.42 — 2 |
tу=200 не; Рп = 3 Вт |
||
|
Умножитель параллельный (12X12) |
КР1802ВР4 |
2136.64 — 1 |
tу=200 не; Рп=4 Вт |
Пвв=2; Пвыв=1 |
|
|
Умножитель параллельный (16X16) |
КР1802ВР5 |
2136.64 — 1 |
ty=200 не; Рп=5 Вт |
Пвв=2; ПвыВ=1 |
|
|
Сумматор на четыре входа |
К.Р1802ИМ1 |
2207.48 — 1 |
tс
= 150 не |
Пвв=4; Пвыв=1 |
|
|
4-разрядная процессорная секция |
КМ1804ВС1 |
Серия КМ1804 2123.40 — 6 |
Uв=5 В±10%; Гц
= 110 не. Разрядность — кратная 4. Система команд по ОСТ 11.305.909 — 82 |
Аналог Ат2901 |
|
|
Схема формирования ускоренного переноса |
КМ1804ВР1 |
201.16 — 16 |
Аналог Ат2902 |
||
|
Схема управления последовательностью мк |
КМ1804ВУ1, КМ1804ВУ2 |
2121.28 — 1 2121.28 — 1 |
Аналоги: Ат2909 Ат2911 |
||
|
Схема выбора адреса следующей мк |
КМ1804ВУЗ |
201.16 — 16 |
16 инструкций |
Ат2918 |
|
|
Параллельный 4-разрядный регистр |
КМ1804ИР1 |
201.16 — 16 |
Гц=20 не; Рп=0,65 Вт |
Ат2918 |
|
|
4-разрядная процессорная секция |
КМ1804ВС2 |
2123.40 — 6 |
Число РОН 16 |
Ат2903 |
|
|
Схема управления состоянием и сдвигами |
КМ1804ВР2 |
2123.40 — 6 |
t3
— 60 не. Число шин 2 |
Ат2904 |
|
|
Схема управления микропрограммой |
КМ1804ВУ4 |
2123.40 — 6 |
Гц=95 не; Рп=1,7 Вт |
Ат2910 |
Микропроцессорный комплект БИС К1800 выполнен по ЭСЛ-функционально-технологическому принципу. Микросхемы отличаются повышенными быстродействием и потребляемой мощностью. Архитектура МПК К1800, как и предыдущих, обеспечивает наращивание разрядности, микропрограммное управление, конвейерную организацию вычислений. Отличительной особенностью ЭСЛ-комплекта является ограниченный функциональный состав БИС, что затрудняет построение законченных МПУ только на МПК К1800. Комплект БИС К1800 электрически совместим с цифровыми микросхемами серий К500, К1500. Наличие в составе комплекта двунаправленного транслятора К1800ВА4 позволяет использовать совместно с К1800 МПК БИС ТТЛШ, например КР1802, КМ1804. При построении МПК К1800 использовался ряд схемотехнических и конструктивно-технологических особенностей построения быстродействующих микросхем, что позволило достигнуть степени интеграции до 1000 логических элементов (ЛЭ) на кристалле, снизить потребляемую мощность до 4 — 5 мВт на один ЛЭ и обеспечить время задержки 1 — 1,5 не на один ЛЭ [16].

Рис. 1.3. Функциональная схема операционного устройства, построенного на МПК БИС К.Р1802
Микропроцессорный комплект БИС К588 выполнен по КМОП-функцианально-технологичесшму принципу. Важнейшей отличительной особенностью таких микросхем является низкая потребляемая мощность. В статическом режиме потребляемая мощность на один ЛЭ примерно в 100 раз меньше, чем у ТТЛ ЛЭ. В динамическом режиме (мощность, потребляемая КМОП-ехемами, увеличивается при повышении тактовой частоты. При тактовой частоте 1 — 2 МГц она всего в 5 — 10 раз меньше мощности, потребляемой ТТЛ-схемами. Комплект БИС К588 имеет несколько меньшее быстродействие, чем ТТЛШ МПК. Однако МПК К588 обеспечивает построение МПУ РЭА с ограниченным потреблением энергии.
Рассмотрим несколько примеров построения различных аппаратных средств на базе рассмотренных МПК БИС.
Пример 1.1. На рис. 1.3 приведена схема 16-разрядного операционного устройства МП [17].
Операционное устройство выполняет арифметические и логические операции над битами, полями битов, 16-разрядными словами; сдвиг 16-разрядных слов на один разряд вправо и влево. Управление работой операционного устройства осуществляется по шине микрокоманд (ШМК) и шине адреса (ШАД). Передача операндов осуществляется по шинам А и В, результат операции выдается на шину А.
Синхронизация считывания информации из регистров и записи результата в регистр выполняется синхроимпульсом (СИ), импульсами чтения (Чт), импульсами записи (Зп). Результат операции сопровождается выдачей признаков равенства нулю (ПН) результата, переполнения разрядной сетки (ПП) и расширения (ПР). Арифметическое устройство выполнено на двух БИС КР1802ВС1 (Dl, D2). Сверхоперативная память данных и результата выполнена на четырех БИС РОН КР1802ИР1 (D3 — D6). Емкость памяти 16X16.
Пример 1.2. Процессор микро-ЭВМ общего назначения. На рис. 1.4 приведена функциональная схема процессора с системой команд и интерфейсом микро-ЭВМ «Электроника-60» [18]. Процессор предназначен для применения в МПУ с жестко ограниченными энергетическими ресурсами и быстродействием до 400 тыс. коротких операций. При этом может быть использовано математическое обеспечение микро-ЭВМ «Электроника-60». Процессор выполнен на БИС МПК К588: К588ВС2 (D6), К588ВУ2 (D1 — D5), К588ВГ1 (D7). Каждая БИС управляющей памяти (D1 — D5) отличается информационным содержанием.
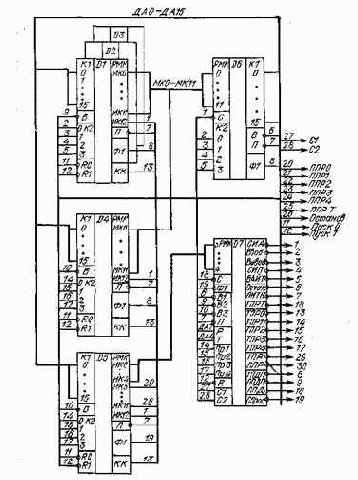
Рис. 1.4. Функциональная схема микропроцессора, построенного на МПК БИС К588
Данные адреса и команды передаются по 16-разрядной совмещенной магистрали данных-адреса ДА0 — ДА15. Эта магистраль соединена с каналом К1 D6 и регистрами команд управляющей памяти (Dl — D5).
Четыре БИС (Dl — D4) формируют микрокоманды, управляющие работой ДУ (D6). 12-разрядные МК объединяются по схеме «проводное И» и подключаются к регистру микрокоманд АУ. Системный контроллер (СК) К588ВП управляется 5-разрядной МК, формируемой D5. Свободные разряды МК (МК5 — МКИ) вырабатывают сигналы разрешения прерывания по запросам ППРО — ППР4, ППРТ и сигнал «Останов».Поскольку длина микропрограмм, записанных в Dl — D5, различная, синхронизация приема кода команды осуществляется по сигналам «Конец команды», объединенным по схеме «Про» водное И».
Репрограммируемые ПЗУ выпускаются двух типов:
|
Серия ППЗУ |
Амплитуда программирующих имнуль-сов, В |
Длительность импульсов, МКС |
Длительность цикла программирования, с |
Скважность импульсов |
|
К541РТ1 |
(4,5-12)+0,5 (2,4-4,5)±0,5 |
1-8 |
0,5 |
2 |
|
КР556РТ5 |
5±0,5, 12,5+0,5; |
25 — 100 |
0,25-1 |
10 |
Важной разновидностью ПЗУ являются программируемые логические матрицы (ПЛМ), которые могут быть запрограммированы в виде различных комбинаций, реализующих логические функции входных сигналов. Конструктивно модули ПЗУ выполняются а виде ФЯ и подключаются к общей магистрали.
Буферные ЗУ представляют собой ОЗУ, выполняющие функции согласования между двумя устройствами, например между периферийным устройством и памятью МПУ; между двумя ЗУ, работающими с различным быстродействием и т. п. Пример использования буферного ЗУ для согласования быстродействия РЛС и магнитного накопителя рассмотрен в § 2.1.
По принципу хранения информации: статические и динамические. В статических ЗУ для хранения каждого бита информации используется отдельный триггер. В динамических ЗУ один бит информации хранится в виде заряда паразитной емкости затвор — лодложка. С течением времени напряжение заряда емкости снижается и может стать меньше допустимого значения.
Во избежа ние этого необходима периодическая подзарядка (регенерация) содержимого ОЗУ. Для динамических ЗУ характерно более низкое быстродействие, обусловленное постоянной цепи заряда — разряда емкости, и большая информационная емкость. Для хранения одного бита информации в динамическом ЗУ требуется 1 — 3 транзистора вместо 6 — 8 транзисторов у статического ЗУ.
По функционально-технологическому принципу: на биполярные (ТТЛШ, И2Л, И3Л, ЭСЛ) и МОП («МОП, КМОП, рМОП). Биполярные ЗУ характеризуются высоким быстродействием (единицы — десятки наносекунд) и соответственно большей потребляемой мощностью; МОП ЗУ обладают большей плотностью размещения, но меньшим быстродействием при меньшей мощности потребления; КМОП БИС могут также сохранять информацию при пониженном напряжении питания, например КР537РУЗ сохраняет информацию при снижении напряжения питания до 1,3 В (номинальное значение 5 В).
Кроме перечисленных выше признаков полупроводниковая память может также классифицироваться по способу организации обмена информацией: с произвольной выборкой и с последовательным обращением; по конструктивной реализации: на встроенную в кристалл МП, реализованную в виде отдельной БИС, выполненную в !виде ФЯ или блока. В качестве признаков классификации могут быть также использованы следующие характеристики ЗУ: емкость памяти, разрядность слова, время выборки, потребляемая мощность и др. В табл. 1.5 приведены основные характеристики наиболее распространенных типов полупроводниковой памяти.
solid windowtext
|
Тип микросхемы |
Емкость, бнт |
Организация БИС |
Время выборки, НС |
Потребляемая мощность, Вт |
Напряжение питания, В |
Тип корпуса |
Функционально-технологический принцип реализации |
|
ОЗУ |
|||||||
|
КР132РУ6А |
16К |
16КХ1 |
75 |
0,5 |
5 |
2104.18 — 1 |
лМОП |
|
КМ132РУ8А |
4К |
1КХ4 |
60 |
0,9 |
5 |
2104.18 — 1 |
«МОП |
|
К155РУ7 |
1К |
1КХ1 |
60 |
0,8 |
5 |
238.16 — 2 |
ТТЛ |
|
КР537РУЗА |
4К |
4КХ1 |
320 |
0,16 |
5 |
2107.18 — 4 |
кмоп |
|
КР537РУ8А |
16К |
2КХ8 |
220 |
0,2 |
5 |
239.24 — 2 |
кмоп |
|
К500РУ415А |
1К |
1КХ1 |
20 |
0,7 |
-5,2 |
238.16 — 2 |
эсл |
|
К500РУ470 |
4К |
4КХ1 |
35 |
0,93 |
-5,2 |
2107.18 — 3 |
эсл |
|
КР541РУ1А |
4К |
4КХ1 |
120 |
0,45 |
5 |
2107.18 — 1 |
иил |
|
КР541РУ2 |
4К |
1КХ4 |
120 |
0,5 |
5 |
427.18 — 1 |
иил |
|
КР541РУЗ |
16К |
16КХ1 |
150 |
0,57 |
5 |
2118.20 — 1 |
иил |
|
КР541РУ31 |
8К |
8КХ1 |
150 |
0,52 |
5 |
2118.20 — 1 |
ииил |
|
К565РУ5Б |
64К |
64КХ1 |
230 |
0,25 |
5 |
2103.16 — 5 |
пМОП |
|
ПЗУ |
|||||||
|
К596РЕ1 |
64К |
8КХ8 |
350 |
0,8 |
5 |
4131.24 — 3 |
ТТЛ |
|
КА596РЕ2 |
1М |
64КХ16 |
450 |
1,1 |
5 |
42-контактный |
ТТЛ |
|
КР568РЕЗ |
128К |
16КХ8 |
800 |
0,3 |
5 |
2121.28 — 3 |
nМОП |
|
К555РЕ4 |
16К |
2КХ8 |
100 |
0,45 |
5 |
239.24 — 2 |
ттлш |
|
ППЗУ |
|||||||
|
К541РТ1 |
1К |
256X4 |
80 |
0,4 |
5 |
402.16 — 21 |
иил |
|
КР556РТ5 |
4К |
512X8 |
80 |
1,0 |
5 |
239.24 — 2 |
ттлш |
|
КР556РТ15 |
8К |
2КХ4 |
60 |
0,74 |
5 |
2104.18 — 5 |
ттлш |
|
КР556РТ16 |
64К |
8КХ8 |
85 |
1,0 |
5 |
239.24 — 5 |
ттлш |
|
КР556РТ18 |
16К |
2КХ8 |
60 |
0,95 |
5 |
239.24 — 2 |
ттлш |
|
РПЗУ |
|||||||
|
К573РФЗ |
64К |
4КХ16 |
450 |
0,45 |
5 |
210Б.24 — 5 |
«МОП |
|
К573РФ4 |
64К |
8КХ8 |
500 |
0,7 |
5,12 |
2121.28 — 4 |
«МОП |
|
К573РФ6А |
64К |
8КХ8 |
300 |
0,87 |
5,12 |
2121.28 — 6.04 |
пМОП |
Структурные схемы таких ЗУ показаны на рис 1.5. Для увеличения разрядности слов объединяются информационные выводы БИС (рис. 1.5,а). Для наращивания числа адресуемых слов в качестве управляющих сигналов используются сигналы «Выборка кристалла» (ВК), осуществляющие подключение выходов БИС к шине данных (рис. 1.5,6). При разработке модулей памяти используются оба способа наращивания ЗУ.

Рис. 1.5. Структурные схемы ОЗУ с объединением информационных выводов ((о) и наращиванием числа адресуемых слов (б)

Рис. 1.6. Функциональная схема модуля ОЗУ емкостью 4КХ16
Подключение ЗУ к общей магистрали осуществляется с помощью схемы внутримодульного интерфейса. На рис. 1.6 показана функциональная схема модуля ЗУ емкостью 4КХ16, реализованная на статических ОЗУ типа КР537РУ2 [21]. Модуль состоит из двух блоков емкостью 4КХ8, реализованных на восьми микросхемах. Внутримодульный интерфейс выполнен на микросхемах D17, D18 типа К588ИР1, D19, D20 магистрального приемопередатчика (МОП) типа К588ВА1 и D21 контроллера ЗУ (КЗУ) типа К588ВГ2. Контроллер ЗУ обеспечивает сопряжение блоков статических ОЗУ с унифицированным межмодульным интерфейсом типа «общая шина». Этот модуль ОЗУ может использоваться совместно с процессором, рассмотренным в примере 1.2. Назначение сигнальных проводов магистрали показано в табл. 1.3.
Разряды ДА1 — ДА12 кода адреса используются для выборки необходимой ячейки памяти. Через МБР они поступают на адресные входы ОЗУ. Гри разряда кода адреса (ДА13 — ДА15) КЗУ используются для подключения одного из восьми модулей к магистрали. Адрес каждого модуля определяется выводами А13 — А15 КЗУ, которые подключаются к общей шине или шине питания. При совпадении кода ДА13 — ДА15 с кодом А13 — А15 КЗУ формирует сигналы ВКО, ВК.1, обеспечивающие подключение информационных выводов блоков 1 и 2 ОЗУ к магистрали данных через МПП (D19, D20). К выводам «Задержка чтения» (ЗДЧ) и «Задержка записи» (ЗДЗ) КЗУ подключаются RС-цепочки, которые определяют задержку выдачи сигнала СИП относительно сигналов ВКО, ВК1 при считывании или записи данных в модуле ОЗУ.
Параметры RC- цепочек выбирают такими, чтобы при наличии сигнала «Ввод» О сигнал СИП-0 не опережал выдачу информации из модуля ОЗУ на магистраль данных, а при наличии сигнала «Вывод»-0 гарантировалась запись информации в ОЗУ. К одному контроллеру ЗУ может быть подключено до восьми модулей ОЗУ.
Модуль ОЗУ имеет следующие параметры: длительность цикла ввода или вывода около 0,8 мкс, мощность потребления: при частоте обращения 1 МГц не более 250 мВт, в режиме хранения не более 8 мВт. Параметры модуля могут быть изменены при использовании других микросхем ОЗУ (см. табл. 1.5). Так, при использовании БИС КР537РУ8А для построения модуля ОЗУ емкостью 4КХ16 потребуется всего 4 микросхемы вместо 16 микросхем КР537РУ2. При использовании биполярных ОЗУ уменьшается время выборки, но увеличивается потребляемая мощность.
1.4. МИКРОСХЕМЫ ПРЕОБРАЗОВАНИЯ ИНФОРМАЦИИ
Радиотехническое устройство (РТУ) обработки сигналов включает аналоговую, аналого-цифровую ih цифровую части. Задачами аналоговой части являются: предварительная селекция полезного сигнала на фоне помех, снижение несущей частоты и повышение уровня принимаемого сигнала до значений, достаточных для устойчивой работы последующих устройств. Аналого-цифровая часть РТУ осуществляет преобразование аналогового сигнала в цифровую форму, а также согласование скорости поступления входного сигнала и быстродействия МПУ (см. § 2.2). Условно можно считать, что для МПУ обработки сигналов аналоговая часть РТУ является датчиком информации, а аналого-цифровая — периферийным устройством (ПУ).
Аналого-цифровые части РТУ можно разделить «а устройства сбора данных (УСД) и устройства распределения данных (УРД) [22]. УСД предназначены для нормализации и преобразования аналоговых сигналов в цифровые с последующей записью их в МПУ. УРД восстанавливают из входного цифрового аналоговый сигнал с последующей передачей его к приемнику информации. Некоторые структурные схемы УСД и УРД приведены на рис. 1.7. В состав УСД входят схемы нормализации аналоговых сигналов, коммутаторы, устройства выборки и хранения (УВХ), осуществляющие быструю выборку аналогового сигнала и згапоминание его значения до следующего цикла преобразования.
Этот входной сигнал преобразуется аналого-цифровым преобразователем (АЦП) в эквивалентное значение цифрового кода, который поступает в МП. Выбор конкретной структуры УСД определяется быстродействием АЦП, параметрами и скоростью поступления входных сигналов. Если входные сигналы узкополосные, а быстродействие АЦП значительно больше Гд, то целесообразно выбрать последовательное УСД (рис. 1.7,а). При работе с широкополосными сигналами, когда время выборки АЦП сравнимо с ТА, используют параллельную схему УСД (рис. 1.7,6).
В состав УРД входят буферные регистры, коммутаторы и цифро-аналоговые преобразователи (ЦАП), осуществляющие декодирование входных цифровых кодов в эквивалентные им значения определенных физических величин (напряжения, тока, частоты, фазы и т. п.). В зависимости от относительного быстродействия МПУ, ЦАП и приемников информации УРД могут строиться по параллельной (рис. 1.7,в) и последовательной (рис. 1.7,г) схемам.
АЦП и ЦАП. Основными функциональными узлами, определяющими быстродействие и конструктивные параметры устройств сбора и распределения данных, являются ЦАП и АЦП. Они характеризуются рядом электрических параметров, отражающих особенности их построения и функционирования. Число таких параметров может достигать нескольких десятков. Каждый параметр имеет свое значение на той или иной стадии разработки преобразователя.
Основными параметрами преобразователей, позволяющими провести их сравнительный анализ на ранних стадиях разработки МПУ, являются: разрядность, время преобразования, потребляемая мощность или ток, нелинейность преобразования, максимальная частота преобразования, параметры входных и выходных на- пряжений и токов, конструктивная реализация [22, 23]. Под разрядностью понимается число разрядов кода, связанного с аналоговой величиной, которое может воспринимать ЦАП или вырабатывать АЦП. Время преобразования равно длительности интервала времени от момента изменения сигнала на входе АЦП до появления на его выходе цифрового кода, соответствующего этому изменению.
Аналогичный параметр для ЦАП называют временем установления выходной аналоговой величины (напряжения, тока и т. п.). Нелинейность преобразователя характеризует отклонение характеристики преобразования от прямой линии. Дифференциальная нелинейность представляет собой отклонение разности двух аналоговых сигналов, соответствующих соседним кодам, от значения единицы младшего разряда. Наибольшую частоту дискретизации, при которой заданные параметры соответствуют установленным нормам, называют максимальной частотой преобразования.

Рис 1.7. Структурные схемы устройств сбора и распределения данных:
a — последовательное УСД; б — параллельное УСД; в — параллельное УРД; г — последовательное УРД
Для уменьшения погрешности преобразования и расширения спектра частот входного сигнала используют УВХ. Это устройство представляет собой временной дискретизатор с памятью. Оно обеспечивает преобразование входного непрерывного сигнала s(t) в непрерывную последовательность s(tn), где м=1, 2, ... Это преобразование включает два режима работы УВХ: выборку значения входного сигнала и хранение этого значения. Могут быть выделены также два переходных режима: переход от выборки к хранению и обратно. Основными параметрами УВХ являются: время выборки, время хранения, апертурное время, потребляемая мощность и некоторые другие [22]. Время выборки равно минимальной длительности выборки, при которой погрешность не превышает допустимой нормы при поочередной выборке минимального и максимального значений (входных сигналов. Время хранения определяется промежутком времени, в течение которого выбранное значение входного сигнала хранится с заданной точностью. Апер-турное время характеризует динамическую погрешность, обусловленную конечным временем переключения ключа при переходе от выборки к хранению информации.
В табл. 1.6 приведены некоторые серии полупроводниковых преобразователей информации.
Микросхемы АЦП К11107ПВ1 и КП07ПВ2 относятся к быстродействующим преобразователям с ограниченной разрядностью.Максимальная частота преобразования не превышает 20 МГц. Логические уровни управляющих и выходных цифровых сигналов соответствуют логическим уровням ТТЛ-схем.
Преобразователи серии КП08 (К1108ПВ1 и КП08ПА1) выполнены по биполярной технологии и имеют повышенное быстродействие. Время выборки АЦП КП08ПВ1 1 мкс. Разрядность выходного кода 10 бит; это позволяет преобразовать аналоговые сигналы, имеющие большой динамический диапазон (до 50 — 60 дБ).
Микросхема АЦП К572ПВ1 является универсальным
|
Тип микросхемы |
Назначение |
Разрядность, бит |
Время преобразования, МКС |
Потребляемая мощность, Вт |
Тип корпуса |
Дифференциальная нелинейность, % |
Примечание |
|
К572ПВ1А |
АЦП |
12 |
150 170 |
0,09 |
4134.48 — 2 |
+0,05 |
U1BHx=2,4 В, |
|
К572ПВ1Б |
АЦП |
12 |
150 170 |
0,09 |
4134.48 — 2 |
+0,1 |
|
|
К572ПВ1В |
АЦП |
12 |
150... 170 |
0,09 |
4134.48 — 2 |
±0,2 |
У«вых=0,3 В |
|
К594ПА1 |
ЦАП |
12 |
3,5 |
0,5 |
405.24 — 2 |
±0,024 |
__ |
|
КРП00СК2 |
УВХ |
— |
tв = 5, txР = 50 |
0,06 |
201.14 — 1 |
0,1 |
Схр=1000 пф, 4=100 не |
|
К1107ПВ1 |
АЦП |
6 |
0,1 |
1,0 |
2207.48 — 1 |
+ (0,5-0.8) |
U1вых=2,4 В, |
|
К1107ПВ2 |
АЦП |
8 |
0,1 |
2,5 |
2136.64 — 1 |
±(0,2-0,4) |
U°вых=0,4 В |
|
К1107ПВЗА |
АЦП |
6 |
0,01 |
1,0 |
201.16 — 13 |
±(0,5+0,8) |
U1вых=—(1,1.-0,7) В, |
|
КП07ПВЗБ |
АЦП |
6 |
0,02 |
1,0 |
201.16 — 13 |
±(0,5+0,8) |
U0вых= — (2...1.5) В |
|
КП08ПВ1 |
АЦП |
10 |
1,0 |
0,8 |
210Б.25 — 1 |
±(0,1+0,4) |
U1Bых=2,4 В, U0вых=0,4 В |
|
КП08ПА1А |
ЦАП |
12 |
0,4 |
0,8 |
2105.24 — 1 |
±0,024 |
U1Bx>2,0 В, |
|
КП08ПА1Б |
ЦАП |
12 |
0,7 |
0,8 |
2105.24 — 1 |
±0,024 |
U°вх<0,8 В |
|
КШЗПВ1А |
АЦП |
10 |
30 |
0,35 |
238.18 — 1 |
+0,1 |
U°вых=0,4 В, |
|
КШЗПВ1Б |
АЦП |
1П |
30 |
0,35 |
238.18 — 1 |
±0,2 |
У1вых=2,4 В |
|
КШЗПВ1В |
АЦП |
10 |
30 |
0,35 |
238.18 — 1 |
±0,4 |
Микросхема К111ЗПВ1 представляет собой функционально полный узел АЦП, предназначенный для использования в блоках аналогового ввода. Для включения микросхемы необходимы два источника питания и несколько резисторов. Наличие выходных буферных регистров с тремя состояниями позволяет непосредственно подключить микросхему к шине данных МП.
Структуры, типовые схемы включения и особенности эксплуатации приведенных в табл. 1.6 преобразователей рассмотрены в [22]. Исключение сос тавляет АЦП К1107ПВЗ. Рассмотрим его подробнее [24]. Быстродействующие шестиразрядяые преобразователи К1107ПВЗА,Б позволяют осуществлять преобразование напряжения в диапазоне ±2,5 В с максимальной частотой 100 и 50 МГц (для преобразователей с индексами А и Б соответственно).
Преобразователь построен по параллельной схеме, следовательно, при выборке аналоговый сигнал поступает одновременно на 64 компаратора. Особенностью построения преобразователя является отсутствие выходного регистра. Это приводит к тому, что часть периода «тактирования» цифровой код на выходе не определен. Длительность этого периода равна длительности режима выборки, но по времени сдвинута относительно его начала.
Типовая схема включения АЦП приведена на рис. 1.8. .Выходы микросхемы через резисторы R6 — R12 сопротивлением 100 Ом подключены к источнику напряжения — 2 В. Два источника опорного напряжения ( + 2,5 В и — 2,5 В) через калибровочные резисторы Rl, R2 подключены к выводам 2 и 4. Для повышения стабильности работы микросхемы на высокой частоте предусмотрена подача на вывод 5 регулируемого напряжения, предназначенного для управления гистерезисом компараторов. Напряжение регулируется от О до 2 В. В основном микросхема применяется без внешнего напряжения гистерезиса. Нестабильность опорных и питающих напряжений вызывает появление дополнительных погрешностей. Для ослабления влияния колебаний напряжений источников к ним подключаются блокировочные конденсаторы С1 — С5 емкостью 0,1 мкФ. АЦП КП07ПВЗ содержат разряд переполнения (вывод 15). Наличие такого разряда позволяет увеличить разрядность преобразователя путем пар ал дельного объединения микросхем (рис... 1.8,6). Для высокочастотных сигналов печатные проводники представляют собой микрополоековые линии. Для исключения отражений сигналов в этих линиях и обеспечения максимального быстродействия АЦП его выводы необходимо согласовать с трактом.
Для этой цели в микросхеме предусмотрены отдельные выводы 16; «Цифровая земля» и 1 «Аналоговая земля», которые подключаются к соответствующим шинам, причем соединение шин осуществляется только в одной точке — на клемме источника питания.

Рис. 1.8. Типовая схема включения микросхемы АЦП К1107ПВЗ (а) и способ объединения двух микросхем (б)
Ограниченные размеры кристалла и невысокая точность изготовления элементов полупроводниковых микросхем обуславливают использование, наряду с полупроводниковыми, АЦП и ЦАП, выполненных по тонкопленочной технологии. В [53] описан АЦП повышенного быстродействия, выполненный по тонкопленочной технологии с использованием бескорпусных микросхем. Преобразователь построен по последовательно-параллельной конвейерной схеме и имеет следующие характеристики: разрядность выходного кода 10, период дискретизации 350 не, амплитуда входного сигнала + 2,5 В, апертурное время 0,2 не, дифференциальная нелинейность 0,2%, потребляемая мощность 20 Вт.
Микросхема УВХ КРП00СК2 реализована на кристалле с размерами 1,7X2,1 мм. Значительное время выборки (5 мке) ограничивает область применения этого устройства узкополосными сигналами. Более быстродействующие УВХ выполняются обычно либо в виде ГИС, либо в виде функционального узла с дискретными элементами. Примеры таких УВХ рассмотрены в [23].
Способы обмена информацией между АЦП и МП. Обмен информацией между периферийными устройствами (включая АЦП) и МП называют вводом-выводом, а устройства, выполняющие эту процедуру, — устройствами ввода-вывода.
Операция ввода информации включает три шага: МП выставляет адрес АЦП на шину адреса; МП ждет, когда УВВ выставит Данные на шину данных; МП считывает данные и помещает их в °дин из регистров.
Операция вывода информации также включает три шага: МП выставляет адрес ЦАП; после получения сигнала о том, что ЦАП готов к приему данных, МП выставляет данные на шину данных; МП ждет завершения передачи данных.
Для согласования работы МП и АЦП используются различные способы обмена информацией. Выбор конкретного способа определяется типом МП, скоростью обмена, сложностью и структурой массива данных и т. п. Специализированные МПУ, используемые в РЭА, производят обмен информацией с УВВ, которые в зависимости от конкретного применения имеют (различные характеристики. Например, для системы передачи телеметрической информации характерно большое число информационных каналов и невысокая скорость их опроса. Для МПУ обработки сигналов — ограниченное число каналов и высокая скорость обмена информацией. Исходя из этих особенностей, коротко рассмотрим следующие способы обмена информацией МП с УВВ: программно-управляемую передачу данных; обращение к УВВ как к ячейке памяти; прерывание и прямой доступ к памяти. Подробнее описание этих способов приведено в [10, 13, 19].
При использования программно-управляемой передачи данных система команд МП должна содержать специальные команды ввода-вывода. Обман данными между МП и УВВ осуществляется в следующей последовательности:
1. МП выдает на адресную магистраль адрес УВВ.
2. МП осуществляет проверку состояния готовности УВВ к обмену информацией. Эта процедура может выполняться, например, с помощью триггера — флага. Если этот триггер находится в состоянии 1, то происходит переход к п. 3. Если триггер — в состоянии 0, то МП повторяет команду опроса состояния УВВ либо осуществляет переход к другому устройству.
3. МП осуществляет ввод или вывод данных. Такая последовательность программно-управляемой передачи данных характерна для АЦП, работающих независимо от МП. Если АЦП запускается одновременно с приемом от МП своего адреса, то вместо опроса состояния триггера можно ввести программную задержку, равную циклу работы АЦП. По истечении времени задержки МП осуществляет ввод или вывод данных. Структурная схема программно-управляемой передачи данных от АЦП в МП приведена на рис. 1.9 [25].
Микропроцессор выдает в шину адреса ад рес ПУ А1. Этот адрес поступает на дешифратор ДШ, который в соответствии с принятым кодом адреса формирует управляющий сигнал У1, поступающий на вентиль D1. На второй вход вентиля с шины управления поступает сигнал «Вывод». При совпадении сигналов «Вывод» и VI на выходе D1 формируется сигнал запуска АЦП. Затем МП переходит в режим ожидания, длительность которого определяется временем преобразования АЦП. По окончании программной задержки МП выдает в адресную шину адрес А2, а в шину управления — «Ввод». Микросхема D2 формирует сигнал, по которому цифровые данные с выхода АЦП через магистральный усилитель D3 поступают на ШД и вводятся в МП.

Рис. 1.9. Структурная схема подключения АЦП к микропроцессору с использованием программно-управляемой передачи данных
Итак, реализация программно-управляемого ввода-вывода не требует затрат адресов памяти и относительно проста. Основным недостатком этого способа обмена информацией является затраты времени на ожидание готовности ЦАП или АЦП к выдаче или приему данных. Близким к рассмотренному выше способу обмена информацией является обращение к УВВ как к ячейке памяти. В этом способе УВВ рассматривается как ячейка памяти. Микропроцессор использует одни и те же команды для обмена как с памятью, так и с УВВ. Конкретное УВВ определяется только своим адресом. Отличиями обращения к УВВ как к ячейке памяти являются: отсутствие особых команд ввода-вывода, УВВ требуют выделения им некоторого числа адресов.
Основным недостатком рассмотренных выше способов обмена информацией является потеря процессорного времени на ожидание готовности УВВ к обмену. Для устранения этого недостатка используется способ обмена информацией с прерыванием программы, выполняемой МП. Прерывание программы может происходить по инициативе УВВ. Для этого оно посылает в МП сигнал «Запрос прерывания», который поступает на специальный вход. Число входов запросов на прерывание колеблется от S1 до 8 для различных МП.
На каждый вход могут поступать сигналы запросов на прерывание более чем от одного источника (такие сигналы могут объединяться по ИЛИ).
После приема сигнала «Запрос на прерывание» МП приостанавливает вычисления по основной программе и переходит к выполнению подпрограммы обмена информацией с УВВ. Эта подпрограмма содержит ряд процедур, подробное описание которых рассмотрено в [10, 13]. После выполнения подпрограммы обмена информацией МП продолжает выполнение основной программы.
Примеры построения (различных схем прерывания с использованием микросхем векторного приоритетного прерывания Ат2914, расширителя приоритетного прерывания Ат2913, а также других БИС серии Ат2900 приведены в [5].
В рассмотренных выше способах обмен информацией осуществляется между УВВ и МП. Для ввода-вывода данных в ОЗУ, минуя МП, используется способ обмена информацией с помощью прямого доступа к памяти (ПДП). Организация обмена данными в режиме ПДП осуществляется обычно контроллером ПДП. Микропроцессор передает управление шинами контроллеру ПДП, который производит обмен данными непосредственно между памятью и УВВ; ПДП может быть реализован таким образом, чтобы выполнять пересылки данных между различными блоками памяти или разными УВВ, использующими общую с МП шину. При этом значительно повышается скорость обмена данными, которая определяется временем доступа к памяти.

Рис. 1.10. Структурная схема алгоритма операции ввода по методу прямого доступа к памяти
Устройства ввода-вывода и МП для связи с памятью пользуются одной шиной и, следовательно, не могут обращаться к памяти в одном цикле. Существуют несколько -вариантов реализации ПДП, в том числе: с блокировкой МП, с квантованием цикла памяти и захватом цикла [13]. В первом варианте — на время пересылки данных контроллер ПДП останавливает МП .и отключает его от шины. Недостатками ПДП с блокировкой МП являются затраты времени на отключение МП от шины и последующее его подключение, а также потеря процессорного времени во время пересылки.
При ПДП с квантованием цикла памяти используется быстродействующая память, цикл которой делится на два временных интервала, причем один из них отводится для МП, а другой — для ПДП. Этот метод позволяет достичь максимальной скорости обмена данными при параллельном выполнении операций » МП. Недостатком метода является необходимость применения быстродействующей памяти, которая потребляет большую мощность и имеет большую стоимость.
Компромиссным вариантом между быстродействием и стоимостью ПДП является метод захвата цикла. При этом методе контроллер ПДП отнимает у МП цикл памяти для пересылки данных. В процессе выполнения обмена данными с УВВ МП не блокируются. Если цикл памяти нужен одновременно МП и контроллеру ПДП, то приоритет отдается ПДП. Таким образом, производительность МП снижается только в тех ситуациях, когда цикл работы МП близок к циклу памяти. Использование микропрограммного управления при построении МПУ приводит к тому, что цикл выполнения команды значительно больше цикла памяти. Это позволяет МП и контроллеру ПДП обращаться к памяти практически без взаимных помех. При работе нескольких МП с общей памятью увеличивается число обращений к последней и поэтому производительность ПДП снижается.
При организации пересылки данных между УВВ и памятью, контроллер ПДП должен выполнять ряд функций. На рис. 1.10 приведена схема алгоритма операции ввода при ПДП. Микропроцессор инициирует работу контроллера ПДП подачей на него команды ввода, начального адреса памяти, отведенной для массива данных, числа слов вводимого массива и другой информации, необходимой для выполнения операции. Затем контроллер получает от УВВ слово данных и запрашивает разрешение на использование шины МПУ для пересылки с ПДП. После предоставления шины контроллер запрашивает разрешение на пересылку данных в память. Получив от памяти сигнал подтверждения о том, что текущий цикл обмена с памятью завершен, контроллер ПДП анализирует содержимое счетчика слов, которое равно числу слов пересылаемого массива данных.
Если содержимое счетчика слов не Равно нулю, то оно уменьшается на единицу, а содержимое счетчика адреса памяти увеличивается на единицу. После этого осуществляется прием (следующего слова данных. Загрузка массива в память продолжается до тех пор, пока значение счетчика слов не становится нулевым. При этом контроллер ПДП прекращает пересылку данных и информирует МП о том, что пересылка завершена.
Обычно контроллеры ПДП представляют собой достаточно сложные устройства и содержат несколько десятков микросхем средней степени интеграции. Уменьшения числа микросхем можно достичь путем использования специальных БИС МПК, реализующих функции контроллера ПДП, например контроллер ПДП серии К588, БИС генератора адреса ПДП Ат2940 и др.
Использование когаюретого способа сопряжения ПУ и МП является одним из важнейших вопросов проектирования МПУ, применяемых в РЭА. Он должен решаться с учетом вычислительных возможностей МП, структуры построения МПУ, разрядности и размерности массива данных, требуемой скорости обмена, обеспечивающей РМВ обработки сигналов, и других требований.

Рис. 1.11. Схема подключения АЦП к микропроцессору
В качестве примера рассмотрим устройство сопряжения АЦП с МП, приведенным иа рис. 1.4 [26].
Пример 1.4. Иа рис. 1.11 приведена схема устройства сопряжения АЦП с МП, интерфейс которого совместим с интерфейсом микро-ЭВМ «Электрони-ка-60». Устройство сопряжения включает: четыре магистральных приемопередатчика (Dl — D4), реализованных на микросхемах К589АП26; дешифратор адреса на микросхемах К155ЛН1 (D5.1, D5.2) и К155ЛА2 (D6); адресный регистр К155ТМ8 (D7, D8); два одновибратора К.155АП (Dll, D12); схему управления режимами работы магистральных приемопередатчиков D10, D9, D14, реализованную на микросхемах К155ЛАЗ, К155ЛЕ1, К155ЛА8 соответственно. Для установки адресного регистра в исходное состояние используются микросхемы D10.1, D9, D13.
Для ввода информации с АЦП МП формирует адрес УВВ и выставляет его на шину данных — адреса (ДА).
Кроме адреса МП выдает также сигналы обращения к внешнему устройству (ВУ) и синхронизации активного устройства (СИА). Эти сигналы вместе с иодом адреса (АО — А15) поступают на дешифратор адреса (D5, D6), который вырабатывает сигнал стробирования для запоминания младших разрядов адреса в адресном регистре D7, D8. С выхода регистра D7, D8 код адреса поступает на мультиплексор, который выбирает соответствующий адресу датчик информации и подключает его ко входу АЦП. Одновременно с выдачей адреса на мультиплексор запускаются одновибраторы Dll, D12, которые используются для формирования задержки запуска АЦП на время срабатывания мультиплексора и для выработки сигнала «Пуск». Микропроцессор вырабатывает сигнал «Ввод», означающий его готовность к приему данных от АЦП. По приему этого сигнала и наличию сигнала «Пуск» на выходе микросхемы D10.2 формируется сигнал переключения магистральных приемопередатчиков на передачу. После приема сигнала «Ввод» устройство сопряжения вырабатывает сигнал «СИП» и выставляет данные на шину ДА. Задержка формирования сигнала «СИП» не должна превышать для данной схемы 10 мкс. Если в течение этого времени сигнал «СИП» не выработан устройством, то МП выходит на прерывание. С учетом этих требований ввод информации в МП в течение одного цикла возможен в том случае, если АЦП имеет время преобразования не более 5 мкс, мультиплексор — время переключения не более 3 мкс. При выполнении этих требований организация операции ввода информации сводится к выполнению одной команды пересылки.
Данное устройство реализовано в виде функциональной ячейки микро-ЭВМ (габаритные размеры печатной платы 143X252x12 мм). АЦП типа Ф7077/1,. мультиплексор реализован на микросхемах серии К591.
сных схем. Технические характеристики АЦП
|
Операции |
Число операций |
Время выполнения операций, мкс |
||
|
КР580 |
К589 |
КР580 |
К589 |
|
|
Умножение |
4 |
4 |
1030 |
39,2 |
|
Сложение |
13 |
16 |
2,0 |
0,2 |
|
Пересылки: |
||||
|
память — регистр |
35 |
7 |
3,5 8,0 |
0,2. 0,4 |
|
регистр — регистр |
8 |
11 |
2,5 |
0,2 |
|
Прочие операции |
5 |
2 |
5,5 — 8,5 |
0,2 |
|
БО |
65 |
40 |
4430 |
164 |

Рис. 2.14. Структурная схема устройства сопряжения РЛС с магнитным накопителем микро-ЭВМ
Основной задачей интерфейсных схем сопряжения является организация обмена данными между источниками, приемниками информации и МП. При этом сопряжение должно осуществляться как по формату данных, так и по скорости обмена. На рис. 2.14 приведена структурная схема устройства сопряжения импульсной РЛС с магнитным накопителем микро-ЭВМ, обеспечивающим регистрацию в РМВ выборок из эхосигнала, следующих с частотой дискретизации 1 МГц в виде 8-разрядных параллельных слов [34]. Данное устройство применяется при исследовании отражательной способности поверхности земли. Для решения этой задачи требуется большой объем памяти запоминающего устройства.
Это мо жет быть обеспечено магнитным накопителем. Второй особенностью является высокая скорость поступления информации. Помимо измерительной информации необходимо записывать также служебную (текущее время, координаты РЛС и т. п.).
Выравнивание скоростей информационных потоков, поступающих с РЛС, служебных сигналов и скорости записи обеспечивается использованием буферного ЗУ (БЗУ).
Сигнал с РЛС поступает на АЦП и анализатор входного сигнала, который вырабатывает стробирующий импульс, запускающий генератор тактовых импульсов (ГТИ1). Одновременно АЦП осуществляет дискретизацию входного сигнала по времени и квантование по уровню. Частота дискретизации 1 МГц. Разрядность АЦП 8 бит, шаг квантования 20 мВ. АЦП формирует часть отсчетов, число которых определяется длительностью стробирую-щего импульса тс: N=xc/TR. Этот массив записывается в ОЗУ1.
Запись служебной информации осуществляется по мере заполнения накапливающего регистра. Входной регистр выполняет роль коммутатора; после окончания записи в ОЗУ1 сигнального массива он осуществляет запись в ОЗУ 1 служебного массива по соседним адресам. Адреса формирует регистр адреса 1. Сигнальный и служебный массивы составляют кадр записи. Для разделения кадров вводится маркер кадра. Очередной кадр информации записывается в соседние ячейки памяти.
После того как будет полностью заполнен модуль ОЗУ1, емкость которого около 2К байт, устройство управления (УУ) переключает режимы работы модулей: ОЗУ1 на считывание, ОЗУ2 иа запись.
Для формирования синхроимпульсов считывания информации используется ГТИ2, частота которого согласована с магнитным накопителем. Считываемая информация через коммутатор поступает на формирователь, вырабатывающий выходной код, определяемый типом магнитного накопителя.
Устройство сопряжения позволяет записывать информацию в РМВ со скоростью значительно ниже скорости поступления информации с РЛС.
2.3. КОНСТРУКЦИИ ФУНКЦИОНАЛЬНЫХ ЯЧЕЕК МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ
Ведущим направлением конструирования современной РЭА является комплексная микроминиатюризация (КММ). Основной задачей КММ является обеспечение высокой надежности, малых масс и объемов, повышенных эксплуатационных характеристик РЭА. Выполнение этих требований обуславливает необходимость применения БИС и СБИС, современных и перспективных конструкций РЭА. При конструировании РЭА широко применяется модульный принцип, под которым понимается совокупность различных методов (функционально-модульный, модульно-ячееч-ный и т. п.), в основе которых заложено общее требование: как расчленить электрическую схему на модули (функциональные ячейки и блоки), чтобы они были как функционально, так и конструктивно законченными. При этом их конструктивные размеры должны быть одинаковыми либо кратными одним базовым размерам, т. е. унифицированными. Таким образом, если конструкция РЭУ представляет собой блок или моноблок с общей герметизацией, то конструкция встроенного в этот блок МП У представляет одну или несколько функциональных ячеек (ФЯ).
Существенным ограничением применения МПУ в РЭА является реальный масштаб времени решения исходных задач. В § 2.2 показано, что выполнение этого требования возможно только при высоком быстродействии МП и других ИМС, входящих в МПУ.
Быстродействие цифровых ИМС прямо пропорционально потребляемой мощности. Это значит, что при повышении быстродействия ухудшаются тепловые режимы работы МПУ. В свою очередь, это может привести к изменению параметров и режимов работы комплектующих изделий относительно расчетных значений и в конечном счете к увеличению отказов. Для уменьшения теплонапряженности в блоках РЭА необходимы дополнительные меры по улучшению теплопередачи. Как известно, теплота передается от нагретого тела в среду путем конвекции и лучеиспускания. Внутри герметичного блока теплота передается, в основном, за счет теплопроводности.
Мощность (Р), рассеиваемая блоком, и перегрев блока v связаны прямо пропорциональной зависимостью P = crv, где а — коэффициент пропорциональности, представляющий собой величину, обратную термическому сопротивлению конструкции блока или ФЯ- Чем выше значение а блока, тем большую мощность он может рассеять при фиксированном перегреве.
Значение а при пе редаче теплоты теплопроводностью пропорционально площади контактируемых поверхностей и коэффициенту теплопроводности материала. Для увеличения теплопроводности ФЯ вводятся металлические теплопроводящие шины, имеющие большое значение коэффициента теплопроводности. Они могут быть выполнены в виде значительных участков фольги на печатных платах, тонких металлических пластин, на которые устанавливаются бескорпусные микросхемы и .микросборки; металлических рамок с планками и т. п.
Применение металлических рамок или оснований (28] повышает теплопроводность не только в ФЯ, но и в пакете ячеек, а от него -к корпусу. Кроме того, использование рамок в конструкциях ФЯ значительно увеличивает ее собственную резонансную частоту, тем самым повышая вибропрочность конструкции ФЯ.

Рис. 2.15. Установка микросхем на тепловые шины: 1 — рама; 2 — микросхема; 3 — печатная плата; 4 — тепловая шина; 5 — контактная площадка

Рис. 2.16. Установка микросхем на тепловые основания: а — со штырьковыми выводами; б — с планарными выводами; 1 — металлическое основание; 2 — микросхема; 3 — плата
Толщина тепловых шин выбирается в пределах 0,4 — 0,8 мм, а металлических оснований 0,4 — 1,0 мм. Материал тепловых шин и оснований — обычно алюминий и его сплавы. Примеры установки микросхем и микросборок на тепловые шины и металлические основания показаны на рис. 2.15 и 2.16.
Для повышения теплопроводимости между ФЯ и блоком тепловой контакт между ними осуществляется через металлическое основание в единой конструкции с рамой ячейки путем пайки, сварки и склеивания мест соединения. Используются также заклепочные и винтовые соединения. При винтовых соединениях термическое сопротивление контакта уменьшается при повышении класса чистоты обрабатываемых поверхностей, повышении усилия сжатия и т. п. На рис. 2.17 показана конструкция теплового контакта ячейки с корпусом блока с помощью односкосного клина. Рассмотрим наиболее распространенные конструкции ФЯ (28].

Рис. 2.17. Конструкция теплового контакта ячейки с корпусом блока с помощью односкосного клина:
1 — печатная плата; 2 — микросхема; 3 — рама; 4 — корпус блока; 5 — винт; 6 — клин

Рис. 2.18. Жесткая рамочная конструкция функциональной ячейки:
1 — печатная плата; 2 — микросборка; 3 — рама; 4 — пустотелая заклепка; 5 — втулка

Рис. 2.19. Конструкция paмы для использования в блоках с воздуховодом: 1 — П-образная металлическая пластина; 2 — воздуховод

Рис. 2.20. Установка микросборок на металлическое основание:
1 — микросборка; 2 — проводник; 3 — металлическая пластина; 4 — печатная плата; 5 — контактная площадка печатной платы
На рис. 2. 18 изображена жесткая рамочная конструкция ФЯ-Рамка этой ячейки выполнена совместно с теплоотводящими шинами. В качестве навесных компонент могут быть использованы корпусные микросхемы и микросборки. Это особенно важно, так как 30 — 50% общего числа микросхем МПУ составляют микросхемы малой и средней степени интеграции. Функциональные узлы из таких микросхем целесообразно выполнять в виде микросборок. Особенности конструкций различных микросборок и порядок их расчета подробно изложены в работах [27, 28]. Микросборки и корпусные БИС устанавливаются на теплопроводящие шины. Выходные контактные площадки микросборок с помощью перемычек соединяются с контактными площадками печатной платы, которая по периметру приклеивается к раме. Типоразмер печатной платы 170X200 мм. Электрическая коммутация ячеек осуществляется с помощью гибкого шлейфа. Благодаря высокой вибропрочности конструкций таких ФЯ они нашли применение, в основном, в самолетной аппаратуре.

Рис. 2.21. Конструкция функциональной ячейки с воздуховодом:
1 — металлическое основание; 2 — микросборка; 3 — воздуховод; 4 — контактные площадки печатной платы; 5 — печатная плата
На рис. 2.19 изображена конструкция рамы, предназначенной для использования в ФЯ блоков герметичной книжной конструкции с воздуховодом.
Печатная плата устанав ливается между стенками рамы. Контактирование между печатной платой и микросборками, устанавливаемыми на раме, осуществляется перемычками через прорези в раме (рис. 2.20). Обычно рамы выполняются из алюминиевых сплавов. Воздуховод крепится к металлическому основанию с помощью сварки и имеет приливы для крепления ячеек в блоке. Конструкция ФЯ с воздуховодом показана на рис. 2.21. Печатная плата ячейки крепится к раме пустотелыми заклепками. Микрооборки приклеиваются к раме с двух сторон. Электрическая коммутация ячеек осуществляется с помощью гибкого шлейфа.
При конструировании ФЯ важным этапом является выбор типоразмера печатных плат. Для решения этой задачи применяется нормативно-техническая документация. Выбор необходимого типоразмера печатных плат зависит от вида аппаратуры, конструкции ячеек, условий эксплуатации аппаратуры. В [28] рекомендуют применять печатные платы размерами 170X75 и 170X200 мм.
Ниже будут показаны перспективные направления конструирования путем сокращения размеров элементов СБИС, а также площади ФЯ и заменой печатных плат микросборками, состоящими из бескорпусных СБИС и подложек. Это направление конструирования позволяет снизить потребляемую мощность и повысить быстродействие.
2.4. КОМПОНОВКА И РАСЧЕТ КОНСТРУКТИВНЫХ ПАРАМЕТРОВ ФУНКЦИОНАЛЬНЫХ ЯЧЕЕК МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ
Особенностью конструкций МПУ является использование ИМС различной степени интеграции. Наряду с СБИС, насчитывающими десятки и сотни тысяч транзисторов, используются микросхемы малой и средней степени интеграции: логические элементы, триггеры и т. п. Это приводит к ухудшению качества компоновки МПУ и увеличению коэффициента дезинтеграции. Для улучшения качества компоновки МПУ целесообразно наряду с корпу-сированными МП БИС использовать микросборки, объединяющие на одной диэлектрической подложке бескорпусные микросхемы малой и средней степени интеграции. Рассмотрим алгоритмы расчета основных конструктивных параметров микросборок и ФЯ.
В основу алго ритмов положены методы расчета, изложенные в [28]. Задача расчета конструктивных параметров микросборок ставится следующим образом: зная число и конструктивные параметры бескорпусных микросхем (кристаллов), определить минимальный типоразмер и число слоев разводки микрооборок.

Рис. 2.22. Посадочное место кристалла
Для решения этой задачи рассмотрим посадочное место кристалла (рис. 2.22). Оно ограничено контуром, проведенным по внешним сторонам контактных площадок. Обычно минимальные размеры посадочного места кристалла определяются по формулам: b1 = bKр+2(a + c); l1=lKP + 2(a + c), где l1, b1 — минимальные размеры посадочного места кристалла; bKP, Up — размеры кристалла; а — сторона контактной площадки; d1 — -минимальное расстояние между двумя контактными площадками; с — минимальное расстояние от края контактной площадки до юрая кристалла. Значения параметров а, с зависят от технологии изготовления микрооборки и приведены в [27].
Алгоритм расчета конструктивных параметров микросборки: 1. Определяем минимальные шаги установки кристаллов по вертикали и горизонтали:

где а1 — минимально допустимое расстояние между внешними краями контактных площадок соседних кристаллов.
2. Поскольку в микросборках, устанавливаемых на тепловые шины, для размещения выходных контактных площадок используются только две противоположные стороны, соотношение двух соседних сторон микросборки целесообразно принять равным 2 : 3 или 4: 5. С учетом этого число рядов и столбцов кристаллов на микросборке можно определять по формулам

где Шу, тх — число рядов и столбцов кристаллов, соответственно; JVKp — общее число кристаллов, расположенных на микросборке; [а] — -целая часть числа а.
3. Находим число контактных площадок, которое можно расположить вокруг кристалла (рис. 2.22):

число неиспользуемых контактных (площадок х + у= (Мкм — Мкр)/2, где Мкр — число выводов кристалла; х, у — число неиспользуемых контактных площадок вдоль большей и меньшей сторон кристалла соответственно.
4. С учетом неиспользуемых контактных площадок определяем размеры зоны проводников:

5. Исходя из приведенных выше уравнений и предполагая, что Расстояние между соседними линиями, сгруппированными в го-
ризентальные шины, равно расстоянию между линиями в вертикальных шинах, определяем х и у:

где М1л, М2л — число вертикальных и горизонтальных шин соответственно. Наиболее распространенной в конструкциях цифровых микросборок и ФЯ является двухслойная разводка соединительных проводников в областях подложки, свободных от контактных площадок. При такой разводке проводники в одном слое проходят, в основном, вертикально; в другом — горизонтально. Число перекрестий тем меньше, чем меньше отношение числа проводников одного слоя к числу проводников другого слоя. В [28] показано, что число вертикальных и горизонтальных линий определяется по формулам

6. Определяем число слоев соединительных проводников:

Соединительные проводники могут быть разведены в двух слоях, если целочисленная часть приведенной формулы равна единице, т. е. знаменатель больше числителя:

Подставив в данное неравенство выражения, приведенные в п. 5.3, получим следующее условие двухслойной разводки:

где К1 — среднее значение коэффициента объединения по входу, увеличенное на 1.
Чтобы приведенное выше выражение имело физический смысл, необходимо выполнение неравенства

Если это неравенство не выполняется, то переходим к п. 10. 7. Находим максимально возможное число рядов и столбцов:

где d — технологическая зона додложки микрооборки.
8. Максимальное число кристаллов, располагающихся на подложке, NKP.KaKC = mxmy.
9. Число микросборок типоразмера bxl, необходимое для размещения заданного числа кристаллов NKp, равно

10. Находим размеры дополнительной площади микросборки, необходимой для расположения проводников вне посадочных мест кристаллов:

где b2, k — размеры суммарных свободных зон под кристаллами вдоль меньшей и большей стороны соответственно:

11. Определяем длину и ширину подложки:
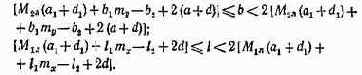
Выбираем стандартный типоразмер подложки и, используя выражения, приведенные в пп. 8, 9, определяем Ммс5.
12. При использовании кристаллов с шариковыми выводами размеры подложки определяются следующим образом:

13. Определяем высоту микросборки: h=hn+hK + hKP, где hn, ;hK, hKp — толщина подложки, клея и высота кристалла соответственно.
При определении размеров микросборки предполагалось, что лспользуются кристаллы одного типоразмера. В случае использования кристаллов различных типоразмеров стандартным считается кристалл, которого в изделии больше всего. Кроме того, считается, что посадочные размеры меньших кристаллов равны соответствующим размерам стандартного кристалла. Наличие кристаллов больших размеров учитывается как некоторое дополнительное число Ni стандартных кристаллов, причем N:i = — ([b11/b1] +l)/([l11/l1] + 1), где b11, l11 — размеры посадочного места кристалла больше стандартного.
При герметизации микросборок в индивидуальном (корпусе полученные значения являются исходными для выбора типа корпуса. Далее посадочные размеры корректируются с учетом шага выводов корпуса и теплового режима.
Методики выбора типа корпуса и расчета теплового режима внутри его приведены в ,[27]. Если предусмотрена общая герметизация блока, использование индивидуальных корпусов микро-сборок не обязательно.
Рассчитанные по приведенному выше алгоритму размеры микросборок являются исходными данными для расчета конструктивных параметров МПУ.

Рис. 2.23. Основные зоны и размеры печатной платы ФЯ:
Lп, Bп — длина и ширина печатной платы; Lu 61 — длина и ширина зоны установки микросхем; хи х2, у1, y2 — краевые поля; U, Ьо — установочные размеры микросхем; Ly, by — шаг установки микросхем; S1, s2, ss, s4 — зоны краевых полей
Алгоритм расчета конструктивных параметров ФЯ.
1. Определяем минимальное число микросборок и БИС МП, смонтированных на печатной плате. Габаритные размеры корпуса являются определяющими для выбора типоразмера печатных плат ФЯ.
Основные зоны и размеры печатной платы ФЯ показаны на рис. 2.23. По периметру печатной платы ФЯ находятся краевые поля, на которых недопустима установка компонентов или прокладка проводников. Часть печатной платы без краевых полей образует контактное поле, на котором располагаются микросборки и микросхемы. На печатной плате можно расположить пу рядов и пх столбцов микросхем:
nу = [(Вв-У1-у2)/by] + 1; (2.5)
nx = [(Ln-x1-x2)/Ly]+1. (2.6)
Число БИС МП и микросборок, смонтированных на печатной
плате с размерами ЬПХВВ, равно NMCl = nxnynyCT, где луст=1 для
штырьковых выводов и 1, 2 для пленарных.
2. Находим максимально допустимую длину общего участка проводников из условия обеспечения помехоустойчивости. В условиях высокой плотности размещения БИС МП и микросборок на печатной плате между сигнальными проводниками возникают емкостная и индуктивная паразитная связь. Возникающие паразитные связи обуславливают наводку в соседних проводниках помех, которые могут вызвать ложное срабатывание микросхем. Во избежание этого необходимо, чтобы уровень помехи не превышал
допустимого предела. В [27] приведены выражения для определения допустимой длины двух соседних .проводников:


где 1с и 1М — допустимые длины общего участка проводников при емкостной и взаимно индуктивной связи; Тф — длительность фронта импульса источника помехи; kПОМ — коэффициент помехоустойчивости; ег — относительная диэлектрическая проницаемость среды; I — величина импульса тока, протекающего по цепи-источнику помех; а, Ъ, d — ширина двух соседних проводников и расстояние между ними; RВЫХ — выходное сопротивление (микросхемы.
В реальных условиях в цепи присутствуют емкостная и индуктивная составляющие помехи. Полагая, что амплитуда помехи пропорциональна длине проводника, определим допустимую длину общего участка двух сигнальных проводников по формуле lдоп = lclм/(lс + lм)
Допустимую длину трех параллельно расположенных проводников при одновременном переключении микросхем в двух активных цепях рекомендуется определять по формуле [28]: l'доп = = 0,5 lдоп.
3. Принимаем, что максимальная длина соединительных проводников не превышает (0,7 — 0,8) b в первом слое и (0,7 — 0,8) l во втором. Если максимальная длина проводников превышает lдоп, то уменьшаем число столбцов пх на один. Увеличиваем расстояние d между проводниками и повторяем выполнение п. 2.
4. Определяем число печатных плат типоразмера LuxBn, необходимых для размещения всех микросхем МПУ (Nмс):
Mu.n = (NMC/NMC1)+1.
5. Выбираем конструкцию ФЯ и определяем ее высоту [27]. Функциональные ячейки МПУ объединяются с ФЯ других узлов РЭУ и располагаются в герметичном блоке. При конструировании РЭА используются различные компоновки блоков. Компоновка и расчет конструктивных параметров блоков РЭА третьего и четвертого поколений рассмотрены в [27, 28].
2.5. ПЕРСПЕКТИВНЫЕ МЕТОДЫ КОНСТРУИРОВАНИЯ ФУНКЦИОНАЛЬНЫХ ЯЧЕЕК МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ
Повышение сложности задач, решаемых МПУ в составе Радиотехнических систем, приводит к необходимости постоянного соверщенствования и методов их конструирования. Применение этих методов в практике (конструирования должно обеспечить повышение быстродействия и надежности, снижение потребляемой мощности и площади внутренних соединений как самих МП, БИС, так и устройств, выполненных на их основе. Среди перспективных конструкций следует отметить разработку МПУ на мно гослойных подложках, выполненных по тонко- или толстопленочной технологии, а также изготовление на одной пластине кремния иле другого полупроводника нескоммутированных БИС. Такие конструкции в зарубежной литературе получили название «интегра-ция на целой пластине» (ИЦП).
Сравнительные параметры в относительных единицах некоторых перспективных конструкций приведены в табл. 2.3 ,[35].
Анализ данных табл. 2.3 показывает, что по критериям, приведенным в ней, наиболее перспективными конструкциями являются гибридные тонкопленочные многослойные схемы на различных подложках с двусторонними монтажом и ИЦП, причем подложки обеспечивают плотность жомпоновки на 25 — 30% выше чем ИЦП.
С точки зрения задержки на БИС обе конструкции приблизительно равноценны. Так, если они имеют около 450 выходных буферных каскадов на одну БИС, то задержка равнг 11,8 не для ИЦП и 10,5 не для многослойных тонкопленочны? подложек с двусторонним монтажом [35].
Практическая реализация перспективных конструкций МПУ неотделима от решения задач повышения быстродействия МП БИС при существенном снижении их потребляемой мощности и сокращении площадей БИС и монтажных плат, занимаемых соединениями.
Рассмотрим некоторые методы, направленные на существенное повышение быстродействия и снижение потребляемой мощно сти в БИС, ФЯ и МПУ за счет уменьшения геометрических раз меров и площадей переходов транзисторных элементов, сокра щения длины и сечения соединений как внутри кристалла, так к в ФЯ и МПУ. Эти методы известны под понятием микроминиа тюризации, которая рассматривается прежде всего ,как один ж основных путей повышения быстродействия цифровых устройств,
при оптимальном размещении логических элементов
|
N |
102 |
103 |
104 |
105 |
10е |
|
К |
4,31 |
6,32 |
9,28 |
13,62 |
20 |

Сокращение линейных размеров соединений и расстояния между ними приводит к росту омического сопротивления проводников и увеличению паразитных реактивностей, влияющих на быстродействие и помехоустойчивость проектируемых БИС. Среди структурных и схемотехнических методов, позволяющих сократить число межэлементных соединений и повысить производительность МПУ, следует отметить: конвейерные структуры; вычисление приращений iK функциям, а не самой функции; использование поразрядной обработки информации; многомикропроцессорные системы с перестраиваемой структурой.
Принципы построения МПУ с использованием приведенных выше методов рассмотрены в ряде работ, например [33, 39].
Таким образом, разработка перспективных методов конструирования связана с решением конструктивно-технологических и схемотехнических задач, обеспечивающих повышение быстродействия и надежности, снижение потребляемой мощности и площади межэлементных соединений МПУ.
Глава 3
автоматизация конструкторского синтеза микропроцессорных устройств и оценка эффективности их применения в рэа
3.1. ВЫБОР КРИТЕРИЯ ОЦЕНКИ ЭФФЕКТИВНОСТИ ПРИМЕНЕНИЯ МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ
При выборе этого критерия необходимо, в первую очередь, учитывать особенности построения и применения МПУ в составе РЭУ. Проведенный в § 2.2 анализ примеров использования МПУ в РЭА выявил основные особенности: решение задачи в РМВ, распараллеливание выполнения задачи, т. е. использование наряду с МП аппаратных процессоров; наличие возможности перераспределения выполняемых функций между МПУ и РЭУ и разработки для этого специальных интерфейсных схем и периферийных устройств. Кроме того, в данной работе рассматриваются, в основном, специализированные МПУ, конструктивно встраиваемые в РЭА. Конструкция таких МПУ должна иметь минимальную массу и объем, ограниченную потребляемую мощность и высокую надежность.
Задача оценки эффективности применения МПУ в РЭА ставится следующим образом: МПУ должно решать исходный алгоритм в рамках заданных ограничений на его реализацию при минимуме затрат. Затраты на реализацию алгоритма характеризуются рядом скалярных критериев, наиболее важными среди которых являются: масса, объем МПУ, надежность по внезапным отказам, тепловой режим, стоимость.
Оптимизация МПУ по перечисленным конструктивным параметрам (как и любая задача оптимального проектирования) является задачей многокритериальной (векторной) оптимизации.
Для решения задач многокритериальной оптимизации в инженерной практике используется ряд методов, позволяющих векторный критерий свести к скалярному [40]. Каждый метод имеет свои преимущества и недостатки, но все они позволяют довести процесс оптимизации до выбора единственного решения. В задачах конструкторской оптимизации МЭА наиболее часто используется комплексный показатель качества [27]

где hij — весовые коэффициенты; qi0 — нормирующий делитель; qij — значение i-го критерия при j-х условиях.
С учетом особенностей применения МПУ в РЭА комплексный показатель качества может быть представлен в следующем виде:

где hv, hm, hi , hP, he — весовые коэффициенты объема, массы, надежности, потребляемой мощности и стоимости МПУ соответственно: v, т, X, р, с, V, М, Л, Р, С — объем, масса, интенсивность отказов, удельная рассеиваемая мощность, стоимость и их нормирующие делители, в качестве которых могут быть взяты одноименные конструктивные параметры всего РЭУ.
Надежность по внезапным отказам является одним из параметров, определяющим условную эффективность всего РЭУ. Для модульных конструкций, предусматривающих возможность перераспределения функций в случае отказов отдельных модулей, интенсивность отказов всего РЭУ определяется из выражения

где Лi — интенсивность отказов г-го функционально-конструктивного модуля.
При независимом проектировании отдельных моду лей значение Лi не должно превышать некоторого допустимого-Ядоп, определяемого из условия обеспечения требуемой величины Л РЭу.
Значение удельной рассеиваемой мощности при заданной температуре окружающей среды во многом определяет тепловой режим МПУ, а значит, и перегревы элементов конструкции. Поскольку эти перегревы согласно ТУ имеют допустимые значения, то и удельная рассеиваемая мощность имеет одностороннее ограничение (р<рдоп).
Важным параметром, характеризующим эффективность применения МПУ, является его стоимость. Методика оценки экономической (эффективности применения МПУ приведена в [41]. Используя эту методику, можно определить стоимость разрабатываемого варианта МПУ. Эта стоимость не должна превышать некоторого допустимого значения сДОп, назначаемого с учетом стоимости всего РЭУ, масштаба его выпуска и т. п.
Итак, для случая использования МПУ в РЭА комплексный показатель качества может быть представлен в следующем виде:
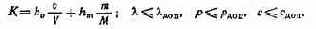
Масса и объем МПУ могут быть определены из следующих выражений:

где qm, qv — коэффициенты дезинтеграции массы и объема МПУ; S2 — площадь всех монтажных плат МПУ; а, р, ST.M.n — соответственно масса, объем и площадь типовой монтажной платы, в качестве которой может быть взята монтажная плата, имеющая минимальные размеры из стандартного ряда, кратные размерам всех монтажных плат МПУ.
Подставив значения т и v в (3.2), получим

В уравнении (3.3) стоящее в скобках выражение является константой для конкретного случая применения МПУ. Поэтому экстремум K совпадает с экстремумом Sz, т. е. минимизация суммарной площади монтажных плат позволяет минимизировать объем и массу МПУ. С учетом ограничений по надежности, удельной рассеиваемой мощности и стоимости этот критерий может быть использован для оценки эффективности применения МПУ в РЭА.
Необходимо отметить, что 52 не является единственным критерием. В большей степени он отражает специфику применения МПУ в бортовой РЭА. Для других применений МПУ в РЭА критерий может быть иным. Например, при проектировании МПУ, эксплуатируемых в условиях ограниченных энергетических ресурсов, т и v могут стать ограничениями, а оценка эффективности применения будет проводиться по минимуму р и X. Для МПУ, используемых в бытовой РЭА, особое значение приобретает стой? мость с. Если из особенностей конкретного применения МПУ не удается определить целесообразные ограничения конструкторских параметров, то оценка эффективности применения проводится по критерию (3.1). Значения весовых коэффициентов могут быть на значены, например, методом экспертных оценок с учетом особен ностей конкретного применения МПУ.
Итак, оптимальным МПУ будем считать устройство, обеспечивающее решение исходного алгоритма в рамках заданных ограничений и при минимуме суммарной площади монтажных плат Sz:

где б, бдоп — среднее квадратическое значение погрешности вычислений МПУ и его допустимое значение; Тпр, Т — время выполнения программы МПУ и его допустимое значение; L — максимальное число различных вариантов построения МПУ.
Исходными данными решения задачи являются: реализуемый алгоритм (А), ограничения (О) на реализацию А, заданная элементная база реализации (МПК. БИС, ОЗУ, ПЗУ, цифровые микросхемы и др.).
Решение задачи включает ряд этапов.
1. Анализ алгоритма и ограничений на его реализацию. На этом этапе анализируются основные алгоритмы реализации задачи, осуществляется предварительный выбор алгоритма, например по минимуму числа операций умножения. Оценивается возможность реализации алгоритма на имеющейся в распоряжении разработчика элементной базе. Осуществляется оценка необходимости разработки специальных периферийных устройств и др.
2. Генерируются различные конструктивные варианты реализации алгоритма А на заданной элементной базе.
Каждый вариант должен удовлетворять ограничениям (3.4). Для уменьшения размерности задачи она решается методом отсечений. Вначале определяются МП, удовлетворяющие функциональным ограничениям на реализуемый алгоритм, т. е. Тпр<Л и ст<бдоп; МП, не удовлетворяющие этим ограничениям, из дальнейшего рассмотрения исключаются. Генерируются только конструктивные варианты МПУ, соответствующие ограничениям (3.4). Для каждого варианта определяется 52.
3. Наиболее эффективным будет считаться вариант построения МПУ, имеющий минимальное значение 52 .
3.2. АНАЛИЗ И МОДЕЛИРОВАНИЕ АЛГОРИТМОВ
Основной задачей этапа анализа и моделирования алгоритмов является обоснование требований к МПУ. Недостаточно тщательно обоснованные исходные данные приводят к неоправданным ухудшениям его конструктивных и функциональных параметров или к тому, что МПУ не будет в состоянии выполнять возложенные на него функции.

Рис. 3.1. Основные параметры гребенки фильтра слектроанализатора
Проследим процесс анализа алгоритмов на примере распространенных задач цифровой обработку сигналов: спектрального анализа и цифровой фильтрации [2, 30].
Спектральный анализ. Спектроана-лизатор представляет собой гребенку узкополосных фильтров, на вход которой подается сигнал с динамическим диапазоном d, уровнями напряжения UМакс и шума 0ш, диапазоном частот ДF. Выходными параметрами являются требования к гребенке фильтра: точность спектрального анализа, определяемая полосой пропускания фильтра Дf, амплитуда пульсаций и неравномерность частотной характеристики на вершине ДВ, величина внеполосного затухания или уровень боковых лепестков частотной характеристики Лб.л, крутизна ската вне полосы S, расстояние между центральными частотами соседних фильтров 6f (рис. 3.1). Чаще всего гребенка таких фильтров реализуется на основе алгоритма БПФ.
На рис. 2.5 изображена структурная схема вычислителя БПФ, на входе которого включен формирователь квадратур (ФК).
Использование ФК позволяет перенести спектр частот в нулевую область, а применение двух АЦП — в 2 раза снизить частоту дискретизации Fд. Наибольшего внимания требует обоснование допустимых отклонений амплитудной и фазовой характеристик ФК от идеальных. Синфазную и квадратурную составляющие на выходе реального ФК можно представить в виде [2]:

где Uосф, U0K — синфазная и квадратурная составляющие идеального ФК; kсф, kK — средние наклоны амплитудных характеристик; аСф n, а,кп, bсф n, bк n — коэффициенты разложения в ряд Фурье ложного сигнала, возникающего из-за отклонений амплитудных характеристик от идеальных.
Нелинейность амплитудных характеристик разных каналов приводит к появлению на выходе ФК искажений, ложных сигналов. Если принять, что все коэффициенты нелинейности, кроме ЬСф i и &кь равны нулю, а йСф=&к=1, что соответствует случаю, когда нелинейность можно представить отрезкам синусоиды, то выражение (3.5) примет вид

Задаваясь конкретным видом входного сигнала и раскладывая UСф и UH в ряд, можно оценить уровень ложных сигналов, которые образуются на частотах, кратных основной частоте.
даны количественные оценки уровня
|
bсф1 |
bк1 |
Ксф=1 |
КК = 1 |
ксф=1, Кк=0,99 |
Ксф=1, Кк=0,95 |
kсф=1. |
kн=0,9 |
||
|
UЗw/Uw ДБ |
U-w/UW, ДБ |
U3w/Uw, ДБ |
U
— w/Uw, дБ |
UЗw/Uw, ДБ |
U
— w/Uw, ДБ |
UЗw/Uw, дБ |
U — w/UW, дБ |
||
|
0 |
0 |
— |
— 46 |
— 32 |
— |
— 26 |
|||
|
0,01 |
0 |
— 50 |
— 40 |
— 50 |
— 36 |
— 50 |
— 29 |
— 50 |
— 24 |
|
0,05 |
0 |
— 36 |
— 25 |
— 36 |
— 26 |
— 36 |
— 23 |
— 36 |
— 20 |
|
0,10 |
0 |
— 30 |
— 21 |
— 30 |
— 20 |
— 30 |
— 19 |
— З0 |
— 17 |
|
0,01 |
0,01 |
— 44 |
— |
— 44 |
— 46 |
— 44 |
— 32 |
— 44 |
— 26 |
|
0,05 |
0,01 |
— 39 |
— 28 |
— 35 |
— 27 |
— 34 |
— 24 |
— 34 |
— 21 |
|
0,10 |
0,01 |
— 30 |
-22 |
— 29 |
— 21 |
— 29 |
— 19 |
— 29 |
— 18 |
|
0,05 |
0,05 |
— 30 |
— |
— 30 |
— 47 |
— 30 |
— 32 |
— 30 |
— 26 |
|
0,10 |
0,05 |
— 27 |
— 27 |
— 27 |
— 26 |
— 26 |
-23 |
— 26 |
__21 |
Отклонения разности фаз квадратурных составляющих от 90° также приводит к появлению ложных сигналов на частоте — Q. При разности фаз ф для гармонического входного сигнала сигнал на выходе ФК можно записать в виде

В табл. 3.2 приведены количественные оценки уровней ложных сигналов, обусловленных отклонением разности фаз каналов от 90.
Используя табл. 3.1 и 3.2, разработчик должен оценить допустимые искажения, определенные заданным динамическим диапазоном входного сигнала d. Если эти искажения велики, то необходимо либо предусмотреть коррекцию искажений, либо отказаться от ФК и перейти к дискретизации сигналов на несущей частоте w (см. § 3.4).
Алгоритм спектрального анализа включает следующие этапы:
1. Формирование подмассивов входных данных. Из массива входных отсчетов s(ri) формируется L подмассивов выходных отсчетов yi(n), где I — номер подмассива .(l=1,L). Соотношения между отсчетами подмассивов и исходного массива определяет алгоритм выбора подмассивов

где Дl — задержка подмассива относительно начала массива; Ni — число отсче-тов подмассива. Параметры N, Ni, Тя, А1 определяются из анализа исходных данных. Число отсчетов на интервале обработки N = TmlTa, где Ти — длитель-ность интервала обработки. Значение Tи определяется требуемым расстоянием между центральными частотами соседних фильтров: rH=l/6f. Частота дискретизаций входного сигнала при использовании ФК Fa>ДF, число отсчетов N=ДF/бf. В данном случае N=Ni. Число подмассивов определяется соотношением между длительностью интервала обработки Ти и длительностью обрабатываемого сигнала Тс: L=TCITS. С помощью БПФ производится вычисление «скачущих» спектров на интервалах длительностью N, сдвинутых на величину скачка N3, причем Na=Al/TR. Обычно в задачах спектрального анализа N3 составляет 1/4, 1/2 или 3[4N [2]. Полученные результаты анализа исходных данных определяют требования к схеме сопряжения и периферийным устройствам МПУ, выполняющего спектральный анализ.
Таблица 3.2
|
Аф, град |
0,10 |
0,15 |
0.20 |
0,30 |
0,35 |
0,40 |
0,45 |
0,50 |
0.6S |
0,60 |
0,65 |
0,70 |
0,85 |
1,00 |
|
Лбл. ДБ |
59,2 |
57,0 |
55,2 |
51,3 |
50,3 |
49,2 |
48,1 |
47,0 |
46,2 |
45.6 |
44.8 |
44,1 |
42,7 |
41,2 |

Этот этап вводится в том случае, если при обработке входного сигнала с динамическим диапазоном d уровень ложных сигналов, обусловленных нелинейностью ФК, превысит допустимый.
3. Весовая обработка входных подмассивов. Амплитудная и фазовая характеристики аналоговых фильтров, эквивалентных выходным отсчетам БПФ, определяются модулем и фазой весовой функции и (га):
yi(n)=si(n)v(n).
Основные параметры наиболее часто применяемых весовых функций приведены в [2]. Выбор конкретной весовой функции определяется следующими параметрами: уровнем боковых лепестков .До.л, крутизной ската S, полосой пропускания фильтра Дf. Отметим, что уровень боковых лепестков с использованием прямоугольной весовой функции [v(n) = 1 при l<n<N] составляет — 13 дБ, S= — 6 дБ/октава.
Если требуется более высокое значение Ае.л, то необходимо вводить в алгоритм спектрального анализа этап весовой обработки.
4. Дискретное преобразование Фурье (ДПФ,)

ДПФ вычисляется по алгоритму БПФ (см. § 2.1). Существует множество алгоритмов БПФ, отличающихся друг от друга, главным образом, числом выполняемых операций умножения и сложения. Реализация операции умножения на МП требует значительного процессорного времени. В свою очередь, вычисление ДПФ составляет основную часть времени вычисления спектра входного яодмассива. Поэтому выбор наиболее эффективного (с вычислительной точки зрения) алгоритма БПФ позволит значительно улучшить конструктивные параметры МПУ. Анализ различных типов алгоритмов БПФ выходит за рамки данной книги. Эти вопросы изложены в [2, 42]. Хотелось бы только отметить, что количество элементарных операций, затрачиваемых на выполнение базовой операции (БО), не всегда является параметром, определяющим эффективность алгоритма в целом. Например, аппаратурная сложность МП, реализующего БО вычисления ДПФ по алгоритму числового преобразования Ферма (ЧПФ), примерно в 3 — 6 раз меньше сложности МП БО, реализующего БПФ по основанию 2. Кроме того, для решения задач обработки радиосигналов один комплексный отсчет для обычного БПФ содержит примерно 27 разрядов, в случае ЧПФ одно действительное слово содержит 33 разряда. Поэтому при вычислений операций свертки умеренной длины (до jV=64) аппаратурный выигрыш при использовании ЧПФ-процессора получается значительным. При увеличении длины; обрабатываемого подмассива, выигрыш в аппаратурных затратах на реализацию БО компенсируется увеличением объема памяти [42]. Разрядность представления входных отсчетов можно оценить следующим образом: iBx»]log2 d[,. где ]а[ — ближайшее к а большее целое число. Для спектрального анализа, входных сигналов время вычисления одного выходного отсчета должно быть неболее Tд. Зная допустимое время вычисления T, а также учитывая значения lвх и N, можно ориентировочно выбрать наиболее эффективные для конкретного случая алгоритмы БПФ.
Фильтрация. Частотная характеристика фильтра с бесконечной импульсной характеристикой (БИХ-фильтра) приведена на рис. 3.2. Основными исходными данными являются: частота настройки w0Тя, полоса пропускания по уровню ДА — 2Аw2Тд, полоса пропускания по уровню А — 2Дw1Tд, амплитуда пульсаций в полосе прозрачности 2AwsTд — ДВ и в полосе задержания 2AwrTa — В.
Коэффициент прямоугольности a = Дw1/Дw2. Близость коэффициента прямоугольности а к единице определяется порядком фильтра. Поэтому задача заключается в выборе минимального порядка фильтра, при котором обеспечиваются перечисленные выше параметры. Если использовать при синтезе цифровых фильтров в качестве аналоговых фильтров-прототипов фильтры Баттер-ворта, Чебышева или эллиптические, то для заданных параметров можно рассчитать зависимость порядка аналоговых фильтров от коэффициента прямоугольности, а затем пересчитать эту зависимость для цифровых фильтров. На рис. 3.3 показана зависимость порядка фильтра от коэффициента прямоугольности аналоговых фильтров и цифровых фильтров, причем b = = tg aДw2Tд/tg Дw2Tд.

Рис. 3.2. Частотная характеристика цифрового БИХ-фильтра

Рис. 3.3. Зависимость порядка фильтра Баттерворта (1), Чебышева (2) и эллиптического (5) от коэффициента прямоугольности
Коэффициенты передачи каскадных цифровых НЧ-фильтров Баттерворта и Чебышева

эллиптических

где М — порядок фильтра (при четных М отсутствует сомножитель перед знаком произведения); Со, С1i, С2i, Dij — коэффициенты фильтра; k0, k1 — масштабирующие коэффициенты.
Анализируя передаточные характеристики фильтров и их исходные данные, можно ограничить число алгоритмов, реализация которых будет рассматриваться на последующих этапах. Если допустимы пульсации частотной характеристики, то целесообразно в качестве прототипа использовать фильтры Че-бышева или эллиптические. Из-за наличия нулей передаточной функции, не равных единице, ошибки и аппаратурные затраты эллиптических фильтров больше, чем фильтров Чебышева того же порядка.
Преимущества эллиптичес ких цифровых фильтров по сравнению с фильтрами Чебышева того же порядка становятся очевидными при коэффициенте прямоугольности а<1,4 за счет меньшего порядка фильтра.
Таким образом, результатом анализа алгоритмов обработки являются основные параметры их реализации: размерность и число входных подмассивов, порядок фильтра, частота дискретизации, уровень боковых лепестков, время обработки и др.
Моделирование алгоритмов. Для выбора наиболее эффективного конструктивного варианта реализации МПУ необходимо обеспечить возможность сравнивать различные варианты друг с другом. Различные системы команд и состав МПК БИС затрудняют решение этой задачи. Поэтому для повышения общности представления алгоритмов и программ применяется их моделирование [43]. Целью такого моделирования является оптимазиция реализуемого алгоритма с точки зрения времени его выполнения на различных МПК БИС. Использование графовых моделей позволяет также исследовать поток данных МПУ и оценить основные характеристики различных структурных вариантов построения МПУ. С помощью графовых моделей можно анализировать микропрограммы, последовательности команд или алгоритм решения некоторой задачи с учетом возможности подключения аппаратных процессоров. Графовые модели алгоритма и программы отличаются только степенью детализации отдельных операторов языка моделирования. ,
Граф программы — это циклический ориентированный граф, вершины X которого представляют различные шаги программы. Вершины связаны друг с другом дугами U, представляющими разветвление и циклы в программе. Граф программы содержит одну начальную вершину х0, предшествующую всем остальным вершинам графа и не имеющую входящих дуг, и одну конечную вершину хк, которая следует за всеми остальными вершинами и не имеет исходящих дуг. Каждой вершине приписывается одно или несколько значений аргументов, которые могут представлять время выполнения данной вершины, погрешность вычисления, потребность в памяти для соответствующего шага программы и т.
п. Для определения времени выполнения программы TпР необходима задать, как минимум, tij — время выполнения i-го шага программы j-м МП.
С каждой дугой иij связывается значение вероятности того,. что из вершины Xi управление будет передано в вершину Xj. Если для дуги значение рц не указано, то оно принимается равным единице.
Важной особенностью графовых моделей является их универсальность. Они могут успешно применяться для оптимизации микропрограмм. В этом случае каждая вершина представляет собой микрокоманду БИС АУ, а дуги указывают последовательность выполнения этих микрокоманд. Такие модели применимы при проектировании, например, МП БО. Необходимость их обусловлена тем, что разработка на микрокомандном уровне моделей алгоритма решения сложных задач, как, например, спектрального анализа, потребует значительного времени и большого объема памяти. В этом случае целесообразно применение блочного многоуровневого моделирования при условии сохранения критериев-на различных уровнях моделирования [44]. Вначале моделируется, например, микропрограмма БО и выбирается оптимальный вариант построения МП БО, затем БО становится сама вершиной-и моделируется уже алгоритм спектрального анализа и т. д.
Графовая модель программы обычно строится на основе ее логической структурной схемы. Построенный граф отображает структуру программы. Затем определяются параметры модели. Некоторая часть этих параметров: размер подмассивов входных данных N, число подмассивов Lп, число этапов вычисления БПФ L, порядок фильтра М, время вычисления базовой операции Tбо, вероятности рij и другие определяются в результате анализа исходных данных реализуемого алгоритма. Другие параметры модели определяются из анализа заданной элементной базы: МПК БИС, их быстродействия, системы микрокоманд и т. п.
В некоторых случаях, когда назначение параметров модели аналитическим путем затруднительно, разрабатывают вначале рабочую версию программы на языке, близком (по составу операторов, распределению регистров и т.
п.) к языку моделирования. Она позволяет проверить логику работы моделируемой программы. Кроме того, некоторые значения параметров модели, например рц, можно получить из анализа этой программы.
Для исследования полученной модели программы обычно требуется ее упрощение. Для корректного проведения такого упрощения принимаются следующие гипотезы: времена выполнения и коэффициенты циклов являются либо константами, либо случайными переменными с независимыми стационарными функциями распределения; вероятности рц не зависят от того, сколько раз выполнялась вершина и откуда было передано к ней управление-В процессе упрощения модели несколько вершин, связанных друг с другом, заменяются одной вершиной с эквивалентными параметрами времени выполнения, вероятностей перехода между вершинами. Некоторые элементарные преобразования графовой модели показаны на рис. 3.4. Параметры fi, ti и б2i представляютчастоту повторения, математическое ожидание и дисперсию времени выполнения вершины Xi. Параметр рij представляет вероятность передачи управления из (вершины х, в вершину Xj.
При упрощении графовой модели программы необходимо тщательно проверить предположения о независимости времени выполнения каждой вершины и вероятности перехода по каждой дуге от параметров других элементов графа. Если существуют вершины, для которых эти предположения неверны, то соответствующие части графа не упрощаются. Упрощения графовых моделей проводятся формальными методами, например с помощью-подсистемы CSS [43].
Модель программы может быть удобно представлена в табличной форме. Существует много способов представления модели; в простейшем из них граф, содержащий n вершин, представляется таблицей из n строк. Каждая строка состоит из следующих элементов: описания выполняемой операции, временных характеристик выполняемой операции для всех исходных МП, указателей-вершин-последователей и значений вероятностей переходов в эти вершины-последователи (табл. 3.3).
В табл. 3.3 дано простейшее описание элементов вершины графа. Описание операции содержит информацию только о выполняемой функции (сложение, вычитание, умножение и т. п.) и представляется кодом. В более сложных случаях описание выполняемой операции может представлять последовательность операторов языка моделирования или при описании действий для определенной вершины модель может использовать генератор случайной величины с заданным распределением и т. п.
Временные характеристики выполняемой операции в простейшем случае представляют собой среднее время tij выполнения:
данной операции МП. Если функция
|
Вершина графа |
Описание операции |
Временные характеристики выполняемой операции |
Вершины-последователи |
Вероятность Pii |
|
МП, ... МП„ |
1 ... k |
1 ... k |
||
|
XI |
XXXY |
t11
Un |
X2
... — |
1 ... — |
|
Xz |
XYXY |
t21
hn |
X3
... X4 |
Р23 ... p34. |
|
. |
. |
. |
. |
|
|
|
. |
. |
. |
. |
|
|
|
|
|
|
|
Xk |
YYXX |
tk1
tkn |
— ... — |
0 ... 0 |

Рис. 3.4. Преобразования графовой модели:
а — последовательное сокращение

6 — устранение петли

в — параллельное сокращение

г — декомпозиция вершины

данной операции МП. Если функция вершины отображает запрос ввода-вывода или другую операцию взаимодействия с МПУ, то в этом случае время выполнения для нее задается извне модели. Значения параметра гц определяется исходя из быстродействия соответствующих МПК с учетом разрядности представления операндов, которая определяется на этапе анализа алгоритма. Для операторов языка моделирования, не имеющих аналогов по выполняемой функции в системах команд МП, разрабатываются подпрограммы или аппаратные процессоры реализации этих операторов. Время выполнения подпрограмм может имеряться средним значением t и дисперсией о2.
Вершины-последователи представляют собой вершины графа, использующие результаты вычисления, произведенного на данном шаге программы. Они описываются своим номером. Заключительный элемент содержит значение вероятности передачи управления в ту или иную вершину-последователь. Сумма вероятностей передачи управления одной, неконечной вершины равна 1. Если вершина-последователь единственная, то передача управления в эту вершину осуществляется с вероятностью, равной 1. Конечная вершина не содержит вершин-последователей. Число столбцов этого элемента, как и предыдущего, определяется максимальным числом вершин-последователей.
Описание модели в табл. 3.3 не является исчерпывающим. В зависимости от цели, преследуемой при разработке модели, таблица может быть дополнена другими элементами, например значением емкости памяти или числом регистров общего назначения (РОН), значением погрешности вычисления соответствующего оператора и т. п.
Итак, графовая модель программы не зависит от типа МП, его системы команд и позволяет оценить быстродействие и точность реализации алгоритма на заданном наборе МП.
3.3. АВТОМАТИЗАЦИЯ ВЫБОРА ТИПА И ЧИСЛА МИКРОПРОЦЕССОРОВ
На этапе выбора типа и числа МП решается одна из сложных задач проектирования МПУ: оценка вариантов использования аппаратных средств и программного обеспечения для реализации исходного алгоритма (А). Кроме того, определяется тип и число МП, обеспечивающих решение заданного алгоритма А в реальном масштабе времени (ТПр<Т) и с заданной точностью (б<бдоп).
Исходными данными для выбора типа и числа МП являются результаты анализа решаемого алгоритма и графовая модель программы, рассмотренная в § 3.2. Заданный алгоритм реализуется на элементной базе, которая может быть представлена, например, в виде табл. 3.4.
При решении задачи на различных

При решении задачи на различных уровнях сложности под МП могут пониматься различные конструктивно-функциональные модули. Если речь идет о реализации МПУ на базе МПК, то в данном случае под МП понимаются БИС АУ, процессорные секции и т. п. Если определяется оптимальный состав микропроцессорной системы управления ЛА или сложным радиоэлектронным комплексом, то в качестве МП (используются либо отдельные микро-ЭВМ, либо функциональные модули типа рассмотренных в § 1.2. Для одних задач МП могут конструктивно представлять собой БГИС, для других — функциональную ячейку. Кроме МП, которые программно реализуют функции, в список элементной базы включены также модули, реализующие некоторые функции аппаратным или программно-аппаратным способом. Число типов таких модулей (как и МП) очень велико: БИС умножителей, сумматоров, арифметических расширителей (арифметика с плавающей запятой); модули, реализующие сложные операции, например МП БО БПФ (см. рис. 2.3), и др.
При задании исходной совокупности МП необходимо определить множество М процессорных модулей, некоторая комбинация которых (МосМ) является оптимальным вариантом построения обрабатывающей части МПУ. Для определения Мо надо исходить из особенностей конкретного применения МПУ в составе РЭУ: условия эксплуатации, энергетические ресурсы, конструктивная совместимость с РЭУ и др. Кроме того, необходимо учитывать следующие характеристики МП:
программные возможности: разрядность; набор команд; методы адресации; время выполнения команд; число РОН, доступных пользователю; наличие стека и его характеристики; максимальная адресуемая память;
аппаратные возможности: максимальная рабочая частота синхронизации, напряжение питания, возможность совмещения с другими логическими схемами, потребляемая мощность, сложность схемы МП, наличие в его составе вспомогательных элементов для расширения функциональных возможностей; возможность комплектация вспомогательными элементами, например, аппаратные умножители, интерфейсные схемы, арифметика с плавающей запятой и др.; размеры корпуса « число выводов, число портов ввода-вывода и др.;
системные характеристики: наличие прерываний, включая их уровень, число и систему приоритетов; ПДП; наличие программного обеспечения (редактор, отладчик, ассемблер, вспомогательное ПО для записи программ в ППЗУ, пакет тригонометрических функций, диагностические программы для МП и памяти) и т. п.;
наличие документации: описания МП, руководящего технического материала по применению, вспомогательной информации;
экономические возможности: стоимость МП, наличие опыта работы с данным МП, .наличие основного и резервного поставщика и т. п.
Совокупность заданных МП М представляет собой открытое множество, которое расширяется при появлении новых МП, отвечающих перечисленным выше требованиям. Каждый МП представляет собой строку таблицы, которая характеризуется рядом элементов (параметров МП). В табл. 3.4 приведен минимальный перечень параметров. При решении конкретных задач число рассматриваемых параметров может быть увеличено.
Важнейшей характеристикой МП является набор команд и время их выполнения. Микропроцессоры, входящие в М, имеют различные системы команд. Независимость модели программы от системы команд конкретных МП достигается выбором языка моделирования.
Проектирование специализированных МПУ, ориентированных на решение задач определенного класса, обычно требует разработки своего языка моделирования. Уровень разработки этого языка может быть различным и зависит от того, какие задачи ставятся разработчиком на данном этапе проектирования.
В общем случае в качестве языка моделирования могут быть использованы алгоритмические языки, ассемблеры, системы команд специализированных вычислительных устройств, решающих подобные задачи, и т. п. В простейшем случае язык моделирования может быть получен путем анализа алгоритмов обработки и систем команд исходных МП. Упрощенный вариант анализа может представлять собой такую последовательность действий:
1. Из исходного множества различных систем команд (МК) выбирается MKi=MK, наиболее соответствующая реализуемому алгоритму (наличие операций умножения, деления, ПДП и др.).
2. MKi дополняется операторами, наиболее часто встречающимися при реализации алгоритмов данного класса (тригонометрические преобразования, комплексное умножение и т. п.). Кроме того, МКг может дополняться операторами, реализуемыми ап-паратно.
3. Система команд каждого МП расширяется путем включения в ее состав подпрограмм реализации дополнительных операторов.
Сформированная, таким образом, система команд по типу выполняемых операций имеет аналоги в системе команд любого МП. Это делает графовую модель программы, представленную в такой системе команд, независимой от типа МП. Особенности систем команд конкретных МП учитываются значением аргумента вершины модели t{j, так как в одном случае это команда и значение ta меньше, в другом — подпрограмма и значение tij соответственно больше. В отличие от МП АЛ реализует одну или несколько операторов выбранного языка моделирования. Кроме набора команд каждый МП характеризуется конструктивными параметрами: разрядностью l, потребляемой мощностью Рп, габаритами, числом выводов. Перечень этих параметров может быть расширен.
Графовая модель программы с учетом принятых в § 3.2 гипотез представляет собой цепь Маркова. Поэтому среднее значение и дисперсия времени ее выполнения определяются следующим образом [46]:

где fi — среднее значение частоты повторения i-го шага программы при однократном проходе; gij — вероятность попадания в состояние Xj, если хi является начальным состоянием: ри — вероятность перехода из вершины Xi в Xj.
Итак, исходя из (3.4), задачу выбора числа и типа МП на I этапе конструкторского синтеза МПУ можно свести к определению группы МП Мо=М, обеспечивающих решение алгоритма при выполнении ограничений Tпр<T, б<бдоп.
Решение задачи включает несколько стадий. Вначале определяются МП, обеспечивающие решение задачи в однопроцессорном варианте. Для тех МП, быстродействие которых недостаточно для однопроцессорного варианта решения задачи, анализируется возможность повышения их производительности путем подключения аппаратных процессоров либо распараллеливанием вычислений.
При расчете погрешности вычислений МПУ исходят из гипотезы о независимости ошибок округления в цепочке последовательных элементарных операций [47]. Среднее квадратическое значение погрешности вычислений МПУ

где ат, стм, аи — средние квадратические значения трансформируемой, методической и инструментальной погрешностей соответственно.
Трансформируемые ошибки порождаются ошибками задания исходных величин. Эти ошибки в процессе выполнения арифметических операций изменяют свою величину (трансформируются). Значение ат можно определить из выражения

где F(xi, X2, ..., хп) — вид реализуемой функции; бi — среднее квадратическое значение погрешности аргумента Xi. Значение погрешности представления входных данных

Методические погрешности представляют собой погрешности численных методов, принятых для вычисления функции F(xu х2, ..., хп). Поскольку алгоритм обработки задан, то, следовательно, ам определено.
Инструментальные погрешности обусловлены конечным числом разрядов, предназначенных для представления операндов и необходимостью округления результатов некоторых элементарных арифметических операций. Результирующая инструментальная погрешность представляет сумму накопившихся ошибок при последовательных округлениях элементарных операций. Величина ее определяется реализуемым алгоритмом и разрядностью МП. Результирующее значение инструментальной погрешности
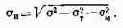
Проведя предварительные вычисления, алгоритм выбора типа и числа МП можно представить в виде следующей последовательности действий:
1. Определяется разрядность ячеек ОЗУ, предназначенных для хранения входного массива данных: lBX = ]log2 UМакс/бвх[, где Umskc — амплитуда входного сигнала; бвх — средняя квадратиче-ская погрешность входного сигнала.
2. Определяется число Дl:

3. Определяется число разрядов, требуемое для компенсации инструментальной погрешности:

где ф — длина цепочки последовательных операций с округлениями.
4. Определяется разрядность МП, обеспечивающая при данной би погрешность представления результатов вычислений не выше бдоп.

Методика расчета разрядности МП, работающих в системах счисления с плавающей запятой, рассмотрена в [48].
5. Корректируется время выполнения операций, представлен-ных в табл. 3.3 с учетом разрядности МП l и времени распространения сигналов переноса.
6. С учетом элементарных преобразований графов, представленных на рис. 3.4, упрощается исходная модель программы.
7. Частота повторения начальной вершины f1 принимается равной 1. Последовательно двигаясь от вершины к вершине, определяются средние частоты их повторения:

где fi — средние частоты повторения предыдущей вершины; т — число дуг, входящих в вершину Xj.
8. На основании данных табл. 3.3 (ti) и результатов, полученных в предыдущем пункте, из выражения (3.6) определяется среднее время выполнения программы каждым МП, представленным в табл. 3.3.
9. С помощью выражения (3.7) определяется D(Tnp). Для упрощения программирования выражения (3.7) оно может быть представлено ib следующем виде [46]:

где ij={ti}j — вектор-столбец значений выполнения шагов программы j-м МП; ij — -{tjifi}; Q=||qij|| — матрица, элементы которой определяются следующим образом:


— вероятность попадания на r-м шаге выполнения программы в состояние Xj, если Xi является начальным состоянием.
Значения элементов матрицы Q определяются значениями матрицы вероятности переходов ||рц||.
10. Для определения верхней границы 7ПР необходимо знать закон распределения плотности вероятности значений ГПР. Если этот закон неизвестен, то можно использовать неравенство Чебы-шева, дающее оценку вероятности того, что абсолютное отклонение случайной величины от ее среднего значения |Tпр — Tпр| не превзойдет некоторого положительного числа a с вероятностью р:

11. Полученное значение 7щ, сравнивается с Т. Микропроцессоры, имеющие значение Тпр<T, образуют группу M0.

Рис. 3.5. Матрица данных
12. Для определения возможности повышения производительности МП необходимо оценить степень параллелизма решаемого алгоритма. Две операции могут выполняться одновременно (параллельно) разными МП, если их операнды определены. Подпрограммы с независимыми данными могут быть определены на основании анализа матрицы данных O = ||ojj||, причем

Матрица О имеет размерность пхп. Строки матрицы совпадают с вершинами графа G(X, U), а столбцы представляют собой вершины-последователи. Иными словами, элементы столбца указывают вершины, результаты операции которых являются операндами данной вершины.
На рис. 3.5 приведен пример матрицы данных. Из анализа матрицы видно, что вершины х2 и х3 определяются только результатом операции вершины х1, следовательно, они могут быть выполнены одновременно.
Построение «матрицы О осуществляется по данным табл. 3.3. Анализируются столбцы матрицы О. Определяются столбцы с совпадающими элементами. Эти столбцы представляют собой начальные вершины подпрограмм, которые могут выполняться одновременно. Подпрограмма включает только те вершины, которые были определены на предыдущих шагах вычислений.
13. С помощью выражений (3.10) и (3.11) определяются Tпр ij, D(Tпpij), где i, j — номер подпрограммы и шип МП соответственно.
14. Сравниваются полученные значения Тпрц с Т. Если Тпр ij<. <T, то переход к п.15, если нет, то к п.16.
15. Определяется минимальное число МП (Кмп), объединенных параллельно и обеспечивающих ТПр ij<Т.
16. Оценивается число последовательно включенных МП:

17. После анализа результатов, полученных в пп.15 и 16, оп ределяется число МП данного типа, необходимое для реализации алгоритма в реальном времени. Эти данные заносятся в массив Мо-
18. Определяется возможность реализации подпрограмм ап-г паратными процессорами (АП). Изменяются веса соответствующих вершин и корректируется значение Тпр. Если Тпр<.Т, то соответствующие МП и АП фиксируются в массиве Мо-
19. Каждый элемент массива Мо представляет собой один из возможных структурных вариантов реализации исходного алгоритма А на заданном наборе МП (см. табл. 3.4) в рамках заданных ограничений (б<7ДОп, Т<Тпр). Лучшим из вариантов будет тот, который размещается на меньшей площади монтажной платы.
Таким образом, данный алгоритм позволяет определить массив Мо, который включает тип и число МП этого типа, обеспечивающее решение алгоритма А в реальном масштабе времени аппаратным или программно-аппаратным путем с использованием одно- или многопроцессорной структуры построения МПУ.
Пример 3.1. Определить тип и число МП БИС, обеспечивающих выполнение БО алгоритма БПФ с прореживанием по времени при следующих ограничениях: Г=2 мкс; система счисления — с фиксированной запятой; аш=2 мВ: динамический диапазон входного сигнала d=45 дБ; тип монтажной платы — односторонняя печатная плата; размерность входного массива vV= 128; потери на выполнение БО — не более 4 дБ; рдоп = 0,1 Вт/см2.
Алгоритм БО БПФ с основанием г = 2 и прореживанием по времени рассматривался в § 2.1. Структурная схема алгоритма представлена на рис. 3.6,а [2]. Алгоритм реализуется на базе МПК БИС, представленных в табл. 1.2. Исключение составляет МПК БИС серии К588. Поскольку алгоритм БО включает операцию умножения, которая не может быть реализована на умножителе К.588ВР2 быстрее 2 мкс, что не удовлетворяет временным ограничениям.
Для упрощения задачи в исходный массив МП М (табл. 3.5) включены только АУ, расширители арифметических операций и схемы обмена информацией.
Содержание табл. 3.5 соответствует табл. 3.4. Состав операторов определен из анализа алгоритма БО БПФ. При оценке времени выполнения операции были сделаны следующие допущения: операции сложения (СЛ), вычитания (ВЧТ), пересылки между регистрами общего назначения (Рг — Рг) выполняются за один такт работы МП; операции пересылки память — регистр (П — Рг) » регистр — память (Рг — П) выполняются за три такта работы МП. Операция умножения последовательным умножителем КР1802ВР2 выполняется за 2 мкс, параллельными умножителями — за один такт работы МП.
Операция умножения двух 16-разрядных чисел МП К1800ВС1 и КМ1804ВС2 выполняется программно, в первом случае за 20 тактов, во втором — за 17 тактов [5]. Действительные значения параметров некоторых БИС могут незначительно отличаться от приведенных в табл. 3.5.
Первым шагом алгоритма выбора типа и числа МП является определение разрядности МП, обеспечивающей требуемую точность вычислений. Выше приведена методика определения разрядности МП для системы счисления с фиксированной запятой. Эта методика справедлива для любых цифровых вычислительных устройств. Вместе с тем, в РЭА, и в частности в цифровой обработке сигналов, вместо понятия среднее квадратическое значение погрешности на выходе устройства пользуются производным от него понятием: потери (Я), вносимые вычислителем. Под потерями понимается уменьшение отношения сигнал-шум на выходе устройства, обусловленное трансформируемой и инструментальной погрешностями. Эти погрешности называют шумами вычислений. Известно [2], что при Д<Збвх, где Д — цена младшего разряда после округления, бвх — среднее квадратическое значение погрешности на входе АУ, ошибки вычислений аддитивны с сигналом.

Рис. 3.6. Структурная схема алгоритма выполнения базовой операции быстрого преобразования Фурье с основанием два и прореживанием по времени (а) и ее графовая модель (б)
Основные конструктивные параметры печатных плат
|
Параметры реализации |
Варианты реализаций микропроцессора базовой операции |
||||||||||
|
Рис. 3.9,а |
Рис. 3.9,6 |
Рис. 3.9.S |
Рис. З.Э.г |
||||||||
|
Тип используемых микросхем |
К1800ВС1 |
К500ИШ79 |
КР1802ВВ1 |
КР1802ВР5 |
КМ1804ВС2 |
КМ1804ВР1 |
КР1802ВР5 |
КР1802ИМ1 |
КР1802БВ1 |
KPI802BP5 |
КР1802ИМ1 |
|
Число микросхем, шт. |
8 |
2 |
4 |
1 |
4 |
1 |
4 |
24 |
4 |
1 |
4 |
|
Период вычисления БО, мкс |
1,86 |
1,2 |
0,2 |
0,9 |
|||||||
|
Среднее число выводов одной микросхемы, шт. |
40 |
40 |
50 |
43 |
|||||||
|
Шаг установки микросхем, мм |
50X38,5 |
47,5x32,5 |
45x38,5 |
42,5x32,5 |
|||||||
|
Размеры краевых полей (x1; х2; у1, у2), мм |
5; 5; 5; 22,5 |
5; 5; 5; 22,5 |
5; 5; 5; 22,5 |
5; 5; 5; 22,5 |
|||||||
|
Размеры печатной платы, мм |
110X220 |
105x190 |
190X297 |
137,5X125 |
|||||||
|
Площадь печатной платы, см2 |
242 |
199,5 |
564,3 |
171,5 |
|||||||
|
Потребляемая мощность, Вт |
12,6 |
17,2 |
56 |
16,6 |
|||||||
|
Удельная потребляемая мощность, Вт/см2 |
0,05 |
0,09 |
0,0992 |
0,097 |
Из анализа данных табл. 3.7 вытекает, что предпочтительными вариантами реализации МП БО являются структуры, изображенные на рис. З.ЭДг.
3.4. АВТОМАТИЗАЦИЯ ВЫБОРА ЭЛЕМЕНТНОЙ БАЗЫ ЗАПОМИНАЮЩИХ УСТРОЙСТВ
Большое число типов БИС ЗУ и противоречивость требований, предъявляемых к модулям памяти, предопределяют многообразие вариантов их реализации. Выбор оптимального варианта представляет собой сложную задачу, решение которой без использования средств автоматизации затруднительно.
Рассмотрим алгоритм выбора элементной базы ЗУ по критерию минимума общей площади монтажных плат. Исходными данными являются: емкость ОЗУ (ПЗУ), определяемая на этапе анализа алгоритма; разрядность операндов, констант, команд и их количество; частота дискретизации входного сигнала; длительность цикла вычисления результата (7ц); допустимое значение удельной мощности рассеивания; допустимое значение интенсивности отказав или нара1ботка на отказ; возможные конструктивные варианты реализации модуля ЗУ: печатная плата (одно- или двухсторонняя, многослойная), микросборка (однослойная, многослойная). Кроме параметров реализации модуля ЗУ задают также основные характеристики и перечень заданных серий микросхем ЗУ. Этот перечень может быть задан в виде таблицы, по форме аналогичной табл. 3.4, но содержащей следующие столбцы: серия БИС ЗУ, емкость (слов), разрядность, длительность цикла обращения, потребляемая мощность, интенсивность отказов, тип корпуса или размеры кристалла и др.
1. Определяется коэффициент распараллеливания ЗУ, обеспечивающий считывание и запись информации в реальном времени:

где N0=NBX + NBb!x — общее число входных операндов, считываемых из ОЗУ (ПЗУ) (iVBx), и результатов вычислений, записываемых в ОЗУ за время одного цикла вычислений 7Ц; t0 — длительность цикла обращения, под которым понимается либо большее из времен записи ш считывания (для ОЗУ), либо время считывания ПЗУ.
2. Рассчитывается коэффициент распараллеливания ОЗУ, обеспечивающий временное согласование работы АЦП и ОЗУ, предназначенного для хранения входного массива:

Выбираем Kр>mах {К1Р, К2р}. Это значение обеспечивает работу МПУ в РМВ.
3. Распараллеливание блоков памяти приводит к необходимости использования буферного ЗУ (БЗУ), выполняющего временное согласование работы ОЗУ (ПЗУ) и МП. Можно выделить два типа БЗУ: первое принимает информацию с АЦП и МП. Общее число входов-выходов этого БЗУ равно No + l, а разрядность (N0+l)l. Между БЗУ и ОЗУ обычно находится мультиплексор, коммутирующий (N0 + 1)l входов на Kpl выходов, соединенных с входами блоков ОЗУ.
Буферное ЗУ второго типа устанавливается между выходом ОЗУ и МП. На вход БЗУ поступает информация с К выходов блоков памяти разрядностью KL Эта информация коммутируется на l входы АУ.
Число микросхем регистрового БЗУ

где l БЗУ1, lбзу2 — разрядность регистров БЗУ первого и второго типа. Для коммутации информации используются мультиплексоры типа (N0+ 1) X 1 и K Х 1 соответственно. ;.
4. Число микросхем для реализации ОЗУ

где Е — число слов ОЗУ, lОзу, Eозу — разрядность и число адре--сов микросхем ОЗУ соответственно.
5. Аналогично п.4 определяется число микросхем ПЗУ.
6. Определяется значение интенсивности отказов модуля ЗУ:

где Кi — число микросхем i-й серии в модуле
ЗУ; Хг — интенсивность отказов микросхем i-й серии; k — число типов микросхем, используемых при реализации модуля ЗУ. Если Лзу<лдоп, то переход к п.8, если нет, то переход к п.7.
7. Определяется тип и кратность резервирования блоков ЗУ, обеспечивающих Л3у<ЛДОП при минимальной площади монтажных плат. Методика решения задачи оптимального резервирования изложена в [49].
Резервирование является одним из методов повышения надежности функционирования устройств. Другие методы и их сравнительный анализ рассмотрены в [47].
8. С учетом полученных значений кратности резервирования определяется общая площадь монтажных плат Sj, необходимая для размещения модуля ЗУ, реализованного на конкретном j-м наборе микросхем.
Методика вычисления площади подложек микросборок заданного набора микросхем приведена в § 2.4. Порядок расчета площади печатных плат рассмотрен в примере 3.3.
9. Вычисляется удельная мощность рассеивания модуля ЗУ, реализованного на j-м наборе микросхем:

где Pi — мощность, потребляемая микросхемой i-го типа; k — коэффициент полезного действия (& «0,24-0,3).
Сравниваем полученное значение рУА j с допустимым значением рдоп. Если Рудi>рДоп, то корректируем значение Sj:
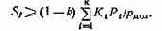
10. Расчеты по пп. 1 — 9 повторяются для всех возможных наборов типов микросхем, заданных в исходных данных.
После про ведения всех вычислений получаем массив значений


где G — максимальное число возможных вариантов реализации модуля ЗУ. Оптимальным считается такой набор серий микросхем, который дает минимальное значение S3y.
При м е р 3.4. Определить структуру и оптимальные параметры модуля ОЗУ МП БО, рассмотренного в примере 3.3.
Исходные данные: емкость ОЗУ EОзу =256 слов, длительность цикла вычисления ТЦ = Т-О =2 МКС Разрядность массива входных отсчетов 8, выходных 16. Частота дискретизации Fд=1 МГц. Основание преобразования r=2. Допустимое значение удельной мощности рассеивания: pДOП=0,02 Вт/см2. Наработка на отказ T=104 ч. Тип конструкции — односторонняя печатная плата. Модуль ОЗУ реализуется на микросхемах, приведенных в табл. 1.5.
1. Выбираем из табл. 1.5 первый этап микросхем — КР132РУ6А.
2. Определяем коэффициент распараллеливания ОЗУ:

3. Поскольку Кр=1, модуль ОЗУ может быть реализован одним блоком; зходные, выходные и промежуточные массивы отсчетов будут записываться по свошл адресам. Разрядность слов принимается максимальной — 16 бит.
Число микросхем КР132РУ6А, необходимое для реализации модуля ОЗУ, равно

4. Полагая, что интенсивность отказов любой микросхемы из табл. 1.5 равна 10-6, определяем наработку на отказ модуля ЗУ:
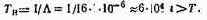
5. Считая, что установочные размеры микросхемы равны 36X32,5 мм, а значения краевых полей х1=Х2=y1=5 мм, y2=10 мм, определяем площадь печатной платы, необходимую для размещения микросхем КР132РУ6А:

6. Удельная мощность рассеяния модуля ОЗУ

Корректируем значение площади печатной платы: S=8/0,02=400 см2. 7. В соответствии с алгоритмом необходимо повторить вычисления для каждой серии табл. 1.5. Однако даже поверхностный анализ показывает, что оптимальной будет серия КР537РУ8А. При условии равенства установочныж размеров микросхем площадь печатной платы для этой серии равна 24,1 см2.
Таким образом, приведенный выше алгоритм позволяет выбрать серию микросхем, обеспечивающих реализацию модулей памяти в рамках заданных ограничений и при минимальной площади монтажных плат.
Без существенной пе ределки алгоритм может быть использован для выбора элементной базы ЗУ по другим критериям.
3.5. ВЫБОР АНАЛОГО-ЦИФРОВОГО ПРЕОБРАЗОВАТЕЛЯ
Аналого-цифровое преобразование входного сигнала x(t) заключается в дискретизации его по времени и квантованию получаемых дискретных отсчетов по уровню. При выполнении этих процессов входной сигнал представляется последовательностью чисел в той или иной позиционной системе счисления. Неидентичность представления сигнала в цифровую форму называют потерями, или шумами аналого-цифрового преобразования [2, 30], Источниками этих шумов являются временная дискретизация сигнала и его амплитудное квантование. Для случая вероятностной оценки шумов, когда ошибки дискретизации и квантования представляются как случайные шумоподобные процессы типа «белый шум», причем любые два источника шума некоррелированы, шумы АЦП суммируются с входными шумами, шумами вычислений» снижая отношение сигнал-шум на выходе МПУ.
Уровни шумов аналого-цифрового преобразования зависят от параметров АЦП, которые обусловлены характеристиками входного сигнала.
Среднее значение тАцп и дисперсия а2АЦП шума квантования в зависимости от выбранной системы счисления и способа округления результата определяются соотношениями:

где ДАцп — шаг квантования.
Зависимость уровней шумов от частоты дискретизации и длительности выборки АЫП будет рассмотрена ниже.
Итак, при выборе АЦП на основании характеристик обрабатываемого сигнала определяют требуемые параметры АЦП: частоту дискретизации, длительность выборки, разрядность и потери, вносимые аналого-цифровым преобразователем. Затем из группы АЦП, параметры которых соответствуют вычисленным значениям, определяют оптимальный. Следует отметить, что небольшое число типов АЦП относительно типов микросхем ЗУ или МП облегчает решение этой задачи и сводит ее практически к определению основных параметров АЦП, удовлетворяющих обрабатываемому сигналу.
Выбор частоты дискретизации входного сигнала зависит от диапазона обрабатываемых частот.
В соответствии с теоремой Котельнмкова FM,>2fmaкc, где fмакс — максимальная частота спек тра сигнала. Однако при дискретизации входного сигнала на несущей частоте огибающая его спектра S(f) состоит из двух симметричных относительно начала координат огибающих составляющих спектров S+(f) и S-(f), причем S(f) =5+(f) +S-(f) (рис. 3.10). Если принять, что спектральная плотность сигнала равна нулю вне полосы ( — fс — AF, — fc + AF) — для отрицательных частот и (fс — AF, fc + AF) — для положительных частот, то можно выбрать Fa значительно ниже, чем fмакс.
При выборе Fц исходят из условия, что К и К-М переносов огибающей спектра S~(f) не образуют пересечений с S+(f). Если пересечений с S+(f) нет, то в силу цикличности спектра эти пересечения отсутствуют во всем диапазоне частот.
Пересечения спектров будут отсутствовать лишь при выполнении следующего условия [50]:

Решая систему неравенств (3.13) относительно FR, получаем

Используя неравенство (3.14), можно построить области допустимых значений частот дискретизации, обеспечивающие отсутствие пересечений составляющих спектра S+(f) и S~(f), так как для всех частот, принадлежащих этим областям, будет справедливо неравенство Fд>4ДF. Наибольший интерес представляет выбор минимально возможной частоты дискретизации. Такой выбор соответствует FR/2ДF>2. При этом необходимо учитывать, что при снижении FA уменьшается — бf и +6f, т. е. огибающие спектра сближаются.

Рис. 3.10. Выбор частоты дискретизации входного сигнала

Рис. 3.11. Определение длительности выборки аналого-цифрового преобразователя
Длительность выборки АЦП существенно влияет на величину потерь квантования. Обычно считается, что выборка происходит за время, значительно меньшее длительности периода входного сигнала, и поэтому эти выборки условно можно считать дельта-функциями — 8(t — KTK). При квантовании на несущей частоте период входного сигнала уменьшается и становится соизмеримым с длительностью выборки АЦП (рис, 3.11).
С учетом конечной длительности выборки дискретизированный входной сигнал можно представить следующим образом [50]:

где 0 — длительность выборки входного сигнала.
Считаем, что выборку АЦП можно аппроксимировать прямоугольной функцией вида

Подставив эти значения в (3.15) и приведя необходимые преобразования, получим выражение для спектра сигнала с учетом длительности выборки [50]: V

где S(f) — спектр сигнала при длительности выборки сигнала,; стремящейся к нулю S(f) — спектр сигнала при длительности выборки, равной ф.
Сомножитель sin (пfф)/(пfф) приводит к снижению амплитуды спектральных составляющих, что эквивалентно уменьшению отношения сигнал-шум, а следовательно, увеличению потерь. Сомножитель ехр( — jnfQ) приводит к сдвигу фазы спектральных отсчетов, причем величина сдвига зависит от диапазона частот принимаемого сигнала.
С точки зрения уменьшения отношения сигнал-шум, определяющим является значение первого сомножителя.
В табл. 3.8 приведены основные результаты роста потерь при увеличении длительности выборки .входных отсчетов.
Разрядность АЦП определяется динамическим диапазоном

Таблица 3.9

Разрядность АЦП определяется динамическим диапазоном входного сигнала и допустимыми шумами квантования. Если на вход АЦП подается сигнал с максимальной амплитудой UMaKC и дисперсией шума ст2ш, то шаг квантования А обычно выбирается равным 1 — Зстш. При увеличении А снижается отношение сигнал/шум на выходе АЦП. Это снижение называют потерями квантования и определяют следующим образом:

где ДАцп, б2ацп — шаг квантования и дисперсия шумов АЦП (при ААЦп<Збш, б2ацп=Д2ацп/12).
В табл. 3.9 приведены некоторые значения Пкв для различных соотношений Ддцп и стш.
Выбрав из табл. 3.9 значения Якв, с учетом заданного значения динамического диапазона d определяется разрядность АЦП Г21:

Таким образом, можно рекомендовать следующий порядок выбора типа АЦП:
1) в соответствии с (3.14) определяется FA;
2) исходя из заданного уровня потерь Пзад и fc определяются Ф, П9, Пкв. При этом потери ПАцп = Пф+ПКв<П3ад;
3) определяется минимальное значение lацп. удовлетворяющее п. 2;
4) Из табл. 1.6 выбираются АЦП, удовлетворяющие пп. 1), 2),3).
3.6. АЛГОРИТМ КОНСТРУКТОРСКОГО СИНТЕЗА
И ОЦЕНКИ ЭФФЕКТИВНОСТИ РАЗЛИЧНЫХ ВАРИАНТОВ
РЕАЛИЗАЦИИ МИКРОПРОЦЕССОРНЫХ УСТРОЙСТВ
Решение задачи конструкторского синтеза и оценки эффективности различных вариантов реализации МПУ включает следующие этапы: анализ требований реализации заданного алгоритма; построение различных вариантов МПУ; оценка конкурирующих вариантов и выбор наиболее эффективного из них.
Рассмотрим алгоритм выполнения этих этапов на примере проектирования цифрового спектроанализатора, реализованной на основе алгоритма БПФ. Исходными данными являются: диапазон анализируемых частот 200 кГц; длительность сигнала 2,5 мс: динамический диапазон по входу 30 дБ; амплитуда входного сигнала 63 мВ; среднее квадратическое значение шума на входе 2 мВ; величина внеполосного затухания 40 дБ; несущая частота 20 МГц; полоса .пропускания эквивалентного фильтра не более 550 Гц; число подмассивов обработки 1.
Микропроцессорное уст ройство реализуется на печатных платах с одно- или двухсторонней компоновкой; при этом удельная мощность рассеивания не более 0,08 Вт/см2, наработка на отказ не менее 20 000 ч.
Анализ требований реализации заданного алгоритма. Задачей этого этапа является определение параметров спектроанализатора, необходимых для построения различных вариантов МПУ. Как известно [2], применяются, в основном, два варианта построения спектроанализатора: с формирователем квадратур (ФК) (см. рис. 2.5) и без него. Использование ФК позволяет в 2 раза снизить .Рд при параллельной работе двух АЦП в каналах ФК. Недостатком такой структуры является ограниченный динамический диапазон входного сигнала. Из табл. 3.1 и 3.2 определяем, что для обеспечения уровня ложных сигналов не выше 40 дБ нелинейность амплитудных характеристик должна быть не более 1%, а отклонение разности фаз в квадратурных каналах от п/2 не более 1°. Для обеспечения такой точности необходимо в алгоритм спектрального анализа ввести коррекцию мнимой и действительной частей входных отсчетов. При дискретизации на несущей частоте вдвое увеличивается входной массив, что потребует введения дополнительного этапа вычисления! ДПФ. Поэтому, с точки зрения временных затрат, эти структурные варианты примерно равноценны.
Несущая частота равна 20 МГц. Из табл. 3.8 определяем, что для обеспечения снижения отношения сигнал-шум не более 2 — 3 дБ длительность выборки сигнала 9=0,36 Tп=9 нc. Разработка УВХ с такими параметрами представляет собой сложную задачу, поэтому выбираем структуру с ФК. Частота дискретизации входного сигнала Рд>ДF=200 кГц. Полоса пропускания эквивалентного фильтра Дf'=1/Tс=400 Гц. Число спектральных отсчетов Nc — =Тс/Тя = 500. Исходя из заданного динамического диапазона входного сигнала при условии Дацп/бш=1 определим разрядность АЦП: lАцп=] Iog2d [=5.
Для обеспечения внеполосного подавления от — 40 дБ используем весовую обработку входных отсчетов [30].
Известно, что весовая обработка приводит к расширению Дf'. Допустимое значение коэффициента расширения k<Дf/Дf'= = 1,37. Этим требованиям удовлетворяет окно Хэмминга, обеспечивающее подавление боковых лепестков до — 43 дБ и ширину полосы пропускания Дf= = 400-1,35=544 Гц.
Операция весовой обработки (как и операция коррекции) сводится к умножению входных отсчетов на постоянную величину. Для сокращения аппаратурных затрат целесообразно совместить выполнение этих операций и использовать один умножитель. При этом корректирующая функция Ф должна учитывать значения весового окна, а также параметры нелинейности и отклонения фаз квадратурных каналов.
Аппаратурные затраты МПУ и особенно ЗУ во многом определяются выбранной системой счисления. При построении цифровых устройств обработки огналов применяются системы счисления с фиксированной, плавающей и по-Слочно-плавающей запятой [30]. Методика расчета разрядности представления комплексных входных отсчетов в различных системах счисления рассмотрена в [2,30]. В этих работах показано, что в системе счисления с фиксированной Запятой разрядность комплексных отсчетов lк.ч>2(lАЦП+L), где L — число тапов вычисления БПФ. В системе счисления с плавающей запятой разрядность кодов мантиссы и порядка выбирается согласно следующим неравенствам: lк.м>lАЦП, lп=log2L. Признак переполнения отсутствует при выполнении условия: (2lАЦП — 1)>3бс(j) + 2iUвх/ДАцп , где бс (j) — суммарное сред-нее квадратическое отклонение шума, полученное в результате выполнения j-го этапа БПФ. Если данное условие не выполняется, то результат БО должен масштабироваться.
Система счисления с поблочно-плавающей запятой представляет собой комбинацию представления чисел с фиксированной и плавающей запятой. Вместо нормирования каждого представляемого числа в отдельности в данной системе один и тот же порядок используется для представления целого массива (блока) чисел. Для этого из массива выбирается наибольшее число и представляется с плавающей запятой для определения общего порядка.
Значения остальных (меньших) чисел содержат их мантиссы. С точки зрения ис пользуемой емкости памяти система счисления с поблочно-плавающей запятой более экономична. С учетом методики, изложенной в [2], найдем разрядность представления чисел в различных системах счисления: с фиксированной запятой lк.ч>30, с плавающей lк.ч>22, с поблочно-плавающей lк.ч>18. С точки зрения экономики памяти целесообразно выбрать систему счисления с поблочно-плавающей запятой. Однако поскольку массив обрабатываемых отсчетов невелик, оценим объем сэкономленной памяти:
ДEОЗУ = 2NХДl=1КХ14.
Достигнутый аппаратурный выигрыш составляет две микросхемы емкостью 2КХ8. Вместе с тем использование системы счисления с поблочно-плавающей запятой требует введения дополнительных операций масштабирования, что усложняет структуру МП БО. Поэтому в данном случае выбираем систему счисления с фиксированной запятой.
Алгоритм спектрального анализа приведен на рис. 3.12,а. На вход устройства поступают отсчеты с Гд=5 мкс. Блок коррекции выполняет умножение входных отсчетов на значения корректирующей функции, которые хранятся в ППЗУ, емкостью NX 16. В регистрах Pcl — Ргб записаны основные параметры обрабатываемого массива: начальный адрес массива входных отсчетов {Pel), начальный адрес массива поворачивающих коэффициентов (Рг2), число БО, выполняемых на каждом этапе вычислений (РгЗ), текущий номер выполняемого этапа БПФ или номер итерации (Рг4), число итераций, необходимых для выполнения БПФ (Рг5) и текущей номер выполняемой БО (Ргб).
Вычисление текущих значений адресов входных отсчетов осуществляется с учетом необходимости перестановки данных после выполнения каждого этапа БПФ [30]. После выполнения 256 БО изменяется текущее значение номера итерации, что учитывается при вычислении значений адресов. После вычисления L итераций в ОЗУ записаны 512 комплексных значений спектральных-отсчетов входного сигнала.
В качестве базиса описания алгоритма, изображенного на рис. 3.12,а, примем команды, приведенные в табл. 3.5 и дополненные подпрограммами коррекции входных отсчетов, выполнения БО и вычисления текущего значения адресов.
На каждой итерации вычисления БПФ выполняется N/2 БО, в которык участвует N отсчетов, разбитых на N/2J групп, где J — номер выполняемом итерации. Считаем, что в данном случае применяется алгоритм БПФ с замещением, т. е. результаты выполнения БО записываются в те же ячейки ОЗУ, ив которых считывались исходные данные. В этом случае алгоритм формирования адресов считывания ОЗУ при коэффициенте распараллеливания Kр = 1 может быть представлен следующим выражением [2]: 1

где t=0, 1..... (NL — 1) — номер формируемого адреса.
Реализация этого алгоритма может быть осуществлена двоичным счетчиком, первый разряд которого выполняет функцию i mod 2. Умножение этого разряда на 29-J увеличивает вес разряда в формируемом адресе. Как следует из алгоритма, на первой итерации этот вес равен 8, на второй 7 и т. д. Второе слагаемое алгоритма определяет вес разрядов счетчика, начиная со второго. На первой итерации разрядам 2 — 9 счетчика присваиваются веса с первого по восьмой, на второй итерации — с первого по седьмой и т. д. На девятой итерации значение (i-2)mod 1 равно 0. Третье слагаемое уравнения (3.17) реализуется использованием соответствующих разрядов счетчика. На первой итерации значение 210((4-210)mod 512 равно 0. На второй итерации девятый разряд счетчика является девятым разрядом адреса считывания. На третьей итерации девятый и восьмой разряды являются девятым и восьмым разрядом АСч. На девятой итерации разряды счетчика со второго по девятый соответствуют аналогичным разрядам АСч-
Адреса считывания поворачивающих коэффициентов W формируются следующим образом:
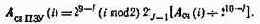
Алгоритмы (3.17) и (3.18) могут быть реализованы программно и аппа-ратно. Так как системы команд МП, приведенных в табл. 1.2, не ориентированы на выполнение операций с отдельными битами, то программная реализация алгоритма (3.17) потребует не менее 10 микрокоманд.
Один из вариантов аппаратной реализации алгоритма формирования адресов считывания приведен на рис. 3.13 [2]. Разряды 9-разрядного счетчика реализуют отдельные слагаемые алгоритма (3.17) в соответствии с приведенным выше описанием. Коммутация разрядов счетчика (изменение их веса) осуществляется мультиплексорами, управление которыми производится кодом номера итерации. При реализации устройства на микросхемах серии 133 необходимы 3 микросхемы 133ИЕ7, 17 микросхем 133КП5 и 2 микросхемы 133ИР13. Время формирования адреса одного отсчета около 300 не.
Небольшой объем обрабатываемого массива данных позволяет реализовать формирователь адресов считывания ОЗУ и ПЗУ на микросхемах памяти. Чио ло адресов ОЗУ JVL=4608, ПЗУ=256-8=2048. Разрядность адреса считывания ОЗУ A'CЧ = ]log2NL[=13; A'счпзу = 11. Устройство формирования адресов может быть реализовано на трех микросхемах РПЗУ с ультрафиолетовым стиранием информации К573РФ6 емкостью 8К.Х8 либо на других микросхемах (см. табл. 1.5).
Коррекция входных отсчетов заключается в умножении этих отсчетов, поступающих с АЦП, на значения корректирующей функции, хранимые в ППЗУ емкостью 512 слов. Особенностью данного алгоритма является ограниченный динамический диапазон входного сигнала, а следовательно, и небольшая разрядность входных отсчетов (6 бит). Это позволяет реализовать коррекцию входных отсчетов на ПЗУ, выполняющем роль умножителя. На адресные входы ПЗУ подаются два числа: множитель и множимое. В ячейке ПЗУ, адрес которой равен коду перемножаемых чисел, хранится их произведение. Поскольку разрядность входных отсчетов 6 бит, разрядность корректирующей функции тоже может быть принята 6 бит. Для реализации такого умножителя необходимо взять БИС ПЗУ, имеющую не менее 4К адресуемых ячеек.


Рис. 3.12. Структурная схема алгоритма спектрального анализа (а) и его графовая модель (б)
Путем формального анализа данных, представленных
|
Номер вершины |
X7 |
Х3 |
X9 |
X11 |
Х12 |
X13 |
|
X15 |
|
|
x1 |
|
|
1 |
|
|
|
|
|
|
|
x2 |
|
1 |
|
|
|
|
|
|
|
|
х3 |
|
1 |
|
|
|
|
|
|
|
|
x4 |
|
1 |
|
|
|
1 |
|
|
|
|
x5 |
|
|
|
|
|
|
1 |
|
|
|
x6 |
|
1 |
|
|
|
|
|
1 |
|
|
х7 |
|
|
|
|
1 |
|
|
|
|
|
x8 |
|
|
1 |
|
|
|
|
|
|
|
x9 |
|
|
|
1 |
|
|
|
|
|
|
x10 |
|
|
|
|
|
|
|
|
|
|
x11 |
|
|
|
|
|
1 |
|
|
|
|
x12 |
|
|
|
|
|
|
1 |
|
|
|
x13 |
|
|
|
|
|
|
|
1 |
|
|
x14 |
|
|
|
|
|
|
|
|
1 |
В первых трех вариантах БО вычисляется на МП БО, приведенном на рис. 3.9,г. Другие блоки алгоритма реализуются следующим образом: в первом варианте на микросхеме К1800ВС1, во втором — на микросхемах КМ1804ВС2 и К573РФ6А (блок xs), в третьем — на микросхемах К588ВС2, К573РФ6А (блоки xi, xs), 564ИЕ10 (блоки xiiy xu). Четвертый вариант микропроцессора включает два МП БО, приведенных на рис. 3.9,а, и микросхему К573РФ6А, реализующую блок алгоритма Ха.
Такты вычислений
Таблица 3.13
| Структурный вариант реализации | Тип и число используемых микросхем | Время выполнения программы, МКС | Потребляемая мощность, Вт | Структурный вариант реализации | Тип и число используемых микросхем | Время выполнения программы, МКС | Потребляемая мощность, Вт | |
| К588ВС2 1 | ||||||||
| К1800ВС1 | 4 | К573РФ6А 2 | ||||||
| I | К1800ВА4 КР1802ВВ1 | 4
4 |
2099 | 26 | III | 564ИЕ10 2 КР1802ВВ1 4 | 2099 | 18 |
| КР1802ВР5 | 1 | КР1802ВР5 1 | ||||||
| КР1802ИМ1 | 4 | КР1802ИМ1 4 | ||||||
| К573РФ6А | 1 | К1800ВС1 16 | ||||||
| II | КМ1804ВС2 КР1802ВВ1 | 2
4 |
2099 | 20 | VI | К500ИШ79 2 К1800ВА4 4 | 239,8 | 28,5 |
| КР1802ВР5 | 1 | К573РФ6А 1 | ||||||
| КР1802ИМ1 | 4 |
Построение и выбор вариантов реализации ОЗУ, ПЗУ. Для выполнения алгоритма спектрального анализа необходимо ОЗУ, в котором размещаются два массива (входной и рабочий), содержащие по 1024 15-разрядных отсчета. Время выполнения БО TБО =2500/2333 = 1,07 икс.
Блоки ОЗУ и ПЗУ реализуются на микросхемах, приведенных в табл. 1.5. Разрядность шины данных 16 бит. Для построения и выбора варианта реализации ОЗУ, ПЗУ используем алгоритм, рассмотренный в § 3.4.
1. Выбираем из табл. 1.5 первый тип микросхем (КР132РУ6А).
2. Определяем коэффициент распараллеливания ОЗУ:

3. Распараллеливание блоков памяти приводит к необходимости использования БЗУ, роль которого могут выполнять либо регистры общего назначения МП БИС, либо БИС ОИ КР1802ВВ1. Для согласования скорости работы Б35 и ОЗУ необходимо включить мультиплексор, который реализуется на четырех микросхемах K530KJI11 при КР = 2.
4. Определяем число микросхем КР132РУ6А, необходимое для реализации ОЗУ:

5. Выбираем из табл. 1.5 следующую серию ОЗУ и повторяем пп. 2 — 4. Варианты реализации ОЗУ, содержащие минимальное число микросхем, приведены в табл. 3.14.
Рассуждая аналогично, можно определить, что ПЗУ поворачивающих коэффициентов может быть реализовано на одной микросхеме К573РФЗ.
Оценка конкурирующих вариантов построения МПУ и выбор оптимального из них осуществляется путем направленного перебора вариантов реализации отдельных модулей МПУ.
1. Выбираем первый вариант реализации МПУ — К.П08ПВ1, первый струк-турный вариант МП (табл. 3.13), ОЗУ КР537РУ8А и ПЗУ К573РФЗ.
Тип конструкции ФЯ
Таблица 2.4
Тип МП |
Время выполнения операции, мкс | Разрядность, бит | Тип
корпуса |
Число РОН | Число портов, шт. | ||||||||
| УМН | ел | 1 вчт | 1 ПРС 1 Рг — Рг | ПРС П — Рг | ПРС Рг — П | ввода | вывода | ввода-вывода | |||||
| КР1802ВС1 | — | 0,15 | 0,15 | 0,15 | 0,45 | 0,45 | 8 | 1,3 | 2206.42 — 1 | 2 | 2 | ||
| К1800ВС1 | 0,6 | 0,03 | 0,03 | 0,03 | 0,09 | 0,09 | 4 | 1,4 | 2207.48 — 1 | 8 | 1 | __. | 2 |
| КМ.1804ВС2 | 1,7 | 0,1 | 0,1 | ОД | 0,3 | 0,3 | 4 | 1,5 | 2123.40 — 6 | 16 | 2 | 1 | __, |
| КР1802ВВ1 | — | — | — | 0,1 | 0,2 | 0,2 | 4 | 1,4 | 2206.42 — 1 | 4 | __ | __, | 4 |
| КР1802ИР1 | — | — | — | 0,1 | 0,3 | 0,2 | 4 | 1,4 | 239.24 — 2 | 16 | __ | __. | 2 |
| КР1802ВР2 | 2,0 | — | — | — | — | — | 8 | 1,5 | 2206.42 — 1 | 2 | — | __, | 2 |
| КР1802ВРЗ | 0.15 | — | — | — | — | — | 8 | 3 | 2206.42 — 1 | 3 | 2 | 1 | __ |
| КР1802ВР4 | 0,15 | — | __ | — — | — | 12 | 4 | 2136.64 — 1 | 3 | 2 | 1 | __ | |
| КР1802ВР5 | 0,15 | __ | __ | __ | — | 16 | 5 | 2136.64 — 1 | 3 | 1 | __ | 2 | |
| КР1802ИМ1 | — | 0,15 | 0,15 | __ | __ | __ | 4 | 1,5 | 2207.48 — 1 | 5 | 4 | 1 | __ |
| КМ1804ВР1 | — | — . | 0,015 | — | — | 16 | 0,6 | 201.16 — 16 | __ | __ | __ | — | |
| К500ИП179 | — | — | — | 0,002 | — | — | 16 | 0,7 | 201.16 — 16 | — | — | — | — |
Таблица 3.6
| Вершина графа | x1 | x2 | х3 | x4 | x5 | х6 | x7 | x8 | х9 | |||||||||||||||
| Описание выполняемой операции | ЗГ | ЗГ | УМН | ЗП | ЗГ | УМН | ЗП | ЗГ | УМН | |||||||||||||||
| Время выполнения КР1802 | 0,45 0,45 | 0,15 | 0,45 | 0,45 | 0,15 | 0,45 | 0,45 | 0,15 | ||||||||||||||||
| операции, мкс К1800 | 0,09 0.09 | 0,6 | 0,03 | 0,09 | 0,6 | 0,03 | 0,09 | 0,6 | ||||||||||||||||
| КМ1804 | 0,3 0,3 | 1,7 | 0,1 | 0,3 | 1,7 | 0,1 | 0,3 | 1.7 | ||||||||||||||||
| Вершины-последователи | х3, хе ха, х12 | x4 , x10 | — | Хд, х9 | х7, х13 | — | Х9, Х12 | X10 | ||||||||||||||||
| X10 | X11 | X12 | Х13 | X14 | X15 | X16 | X17 | Х18 | X19 | X20 | X21 | X22 | X23 | X24 | ||||||||||
| ВЧТ | 1 ЗП | УМН | СЛ | ЗП | ЗГ | СЛ | 1 ЗП | | ВЧТ | ЗП | ЗГ | СЛ | ЗП | ВЧТ | ЗП | ||||||||||
| 0,15 | 0,45 | 0Л5 | 0,15 | 0,45 | о | 0,15 | 0,15 | 0,15 | 0,15 | 0,45 | 0,15 | 0,15 | 0,15 | 0,15 | ||||||||||
| 0,03 | 0,03 | 0,6 | 0,03 | 0,03 | 0,09 | 0,03 | 0,03 | 0,03 | 0,03 | 0,09 | 0,03 | 0,03 | 0,03 | 0,03 | ||||||||||
| 0,1 | 0.1 | 1,7 | 0,1 | 0,1 | 0,3 | 0.1 | 0.1 | 0,1 | 0,1 | 0,3 | 0,1 | 0,1 | 0,1 | 0,1 | ||||||||||
| Х11,x16, x18 | — | X13 | X14, X21, X22 | — | Х16, X18 | X17 | — | X19 | — | X2l, X23 | X22 | — | X24 | |||||||||||
Потери БО

где б2БО — среднее квадратическое значение вычислений БО; б2вх = б2ш+б2ацп, При выборе цены младшего разряда АЦП ДАцп=бш, допуская, что ошибки округления равномерно распределены по амплитуде в пределах младшего разряда и имеют дисперсию [2], б2АцП=бш2/12, получим б2Вх= 1,08 бш2.
Поскольку бш и ПБО заданы, из (3.12) можно определить аБО и в соответствии с пп. 1 — 4 алгоритма найти l.
Решая уравнение (3.12) относительно сгБО, получим: аБО»28,7 мВ. Так как динамический диапазон d=lO lg/(UMaKc/б2BX), то

Разрядность ячеек входного ОЗУ

Разрядность МП, обеспечивающая шумовые потери на вычислении БО массива) из 128 входных отсчетов, равна

Принимаем о-и = сгБО; тогда Дl=5.
Как следует из (2.2), вычисление двухточечного БПФ включает четыре умножения и шесть сложений действительных чисел. При выполнении БПФ массива из N входных отсчетов необходимо выполнить N/2-log2N БО. С учетом этого, длина цепочки последовательных операций с округлениями г|з = 1792~ Тогда

l=8 бит.
Итак, для обеспечения потерь на вычисление БО не более 4 дБ разрядность МП должна быть равна 8. Однако чаще всего разрядность МП обработки сигналов определяет не допустимый уровень потерь, а требование отсутствия аномальных погрешностей, вызванных переполнением разрядной сетки МП. Во избежание переполнений используются различные методы масштабирования результатов вычислений [30]. Каждый метод требует затрат процессорного времени на выполнение операций масштабирования, которых в условиях жестких временных ограничений может не оказаться. Тогда заведомо увеличивают разрядность МП с тем расчетом, чтобы гарантировать отсутствие переполнения на всех этапах вычислений. При этом, конечно, увеличиваются аппаратные затраты.
С учетом изложенного разрядность МП ltm>l + L + знаковый разряд, где L = log2N — старшие разряды кода входных данных, добавляемые для предотвращения переполнений на всех этапах вычислений Выберем lМП = 16
При коррекции времени выполнения операций с учетом разрядности необходимо учитывать следующее: в табл. 3.5 длительность программной реализации операции умножения соответствует 16-разрядным числам. Кроме того, при выполнении арифметических операций используются микросхемы ускоренного переноса К500ИП179 и КМ1804ВР1, которые вносят незначительную задержку распространения сигнала переноса (2 и 15 не соответственно). С учетом этого в табл. 3.6 приведены времена выполнения шагов программы БО.
Вычисление БО на МПК КР1802 может быть реализовано с использованием параллельного умножителя 16x16 типа КР1802ВР5. Умножитель обменивается информацией с МП БИС КР1802ВС1 по магистрали данных. При этом увеличивается время записи произведения, так как пересылка между МП БИС и умножителем эквивалентна пересылке Рг — П.
Алгоритм БО БПФ представляет собой цепочку последовательных операций, значит, TПр равно сумме времен выполнения отдельных его шагов: Tпp1 = 6,6 мкс, TПр2=3,36 мкc, Tпр3= 10 мкс. Микропроцессоры, приведенные в табл. 3.4, не обеспечивают вычисление БО в реальном времени. Для повышения быстродействия вычисления БО необходимо распараллелить ее алгоритм. Для этого в соответствии с п. 12 приведенного выше алгоритма и по данным табл. 3.6 строим матрицу данных (рис. 3.7). Из этой матрицы можно определить подпрограммы, допускающие параллельные вычисления.

Рис. 3.7. Матрица данных алгоритма базовой операции быстрого преобразования Фурье
Последовательность выполнения подпрограмм по тактам представлена на рис. 3.8. При распараллеливании алгоритма БО БПФ он выполняется за пять тактов. Однако время выполнения БО может быть доведено до одного такта при использовании «конвейерной» структуры вычислений. Принципы построения таких вычислителей рассмотрены в [33, 39]. Суть «конвейерной» организации вычислений заключается в том, что для реализации некоторой программы используются N МП, каждый из которых выполняет только часть программы.
Промежуточный результат вычислений 1-го МП передается i+1-му, а i- й МП принимает новые исходные данные от I — 1 МП и повторяет вычисление своей подпрограммы. Программа должна быть распределена между МП таким образом, чтобы обеспечивалась максимальная загрузка каждого МП. Это возможно лишь в случае равенства времен выполнения своих подпрограмм всеми МП, включенными в «конвейер». В любом другом случае длительность одного такта работы «конвейера» будет определяться самым медленным МП цепочки.
При конвейерном вычислении БО на первом такте вычисляются вершины хи х% х5, xs, на втором х3, х6, хд, хХч и т. д. Через пять тактов на выходе МП появится первый результат, последующие результаты будут появляться через каждый такт.
Анализ времен выполнения отдельных операций показывает, что при реализации БО на МПК БИС серий К1800 и КМ 1804 длительность умножения значительно больше длительности выполнения других операций. Поэтому в данном случае целесообразно распараллелить алгоритм БО, например при использовании двух МП K1800BG1 на первом могут быть выполнены подпрограммы I, II, III, VI, VII; на втором IV, V, VIII и IX (рис. 3.8). С учетом дополнительных операций пересылок время выполнения БО будет примерно равно 1,86 мкс, что удовлетворяет временному ограничению. Проводя формальный анализ данных табл. 3.5 и 3.6, а также матрицы данных (рис. 3.7 и 3.8), можно генерировать различные структурные варианты построения МП БО. Некоторые из них показаны на рис. 3.9.

Рис. 3.8. Временная диаграмма вычисления базовой операции быстрого преобразования Фурье (I — IX — подпрограммы)

Рис. 3.9. Структурные схемы микропроцессоров базовых операций на МПК К1800 (а), КР1802 и КМ1804 (б) с распараллеливанием вычислений (в) и без распараллеливания вычислений (г)
Микропроцессор, представленный на рис. 3.9,6, использует «конвейерную» организацию вычислений. В соответствии с временной диаграммой на рис. 3.8 на первом этапе осуществляется загрузка комплексного значения поворачивающего коэффициента W и одного отсчета В (вершины х1, x2, х5, x8).
С целью повышения быстродействия вычислений загрузка второго отсчета А во времени может быть совмещена с умножением или первым сложением (т. е. выполнена на втором или третьем такте). Параллельный умножитель КР1802ВР5 выполняет четыре операции умножения (второй такт). Результаты умножений записываются в процессорную секцию КМ1804ВС2, где программно выполняются остальные вычисления. Время вычислений распределяется по тактам следующим образом: первый такт — 0,8 мкс, второй — 0,6 мкс, третий и четвертый — 1,2 мкс, пятый — 1,2 мкс. Первое значение БО будет вычислено за 2,6 (мкс, следующие значения будут поступать с задержкой 1,2 мкс.
На рис. З.Э.в приведена структурная схема МП, обеспечивающего вычисление БО с максимально возможной скоростью (для заданного в табл. 3.5 набора МП). Высокая производительность вычислений достигнута максимальным их распараллеливанием и использованием аппаратных процессоров. За время одного цикла вычислений МПК КР1802 осуществляется выполнение каждого такта (см. рис. 3.8).
На рис. 3.9,г приведена структурная схема конвейерного МП БО без рас-лараллеливания вычислений. Длительность максимального такта равна временя последовательного вычисления шести операций сложения (0,9 мкс).
Для сравнительной оценки различных вариантов МП БО определим необходимую для их размещения площадь печатной платы. Разбиение печатной платы на основные поля и зоны показано на рис. 2.23. Размеры печатной платы могут быть определены из уравнений (2.5) и (2.6).
